 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Generation of Shareable Synthetic Clinical Notes Using Neural Language Models
May 21, 2019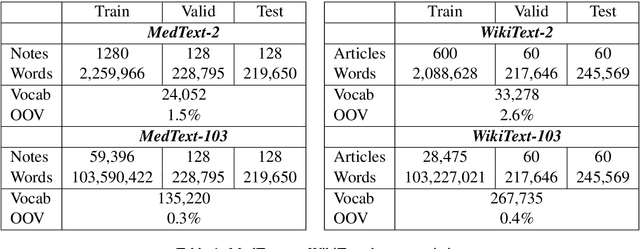

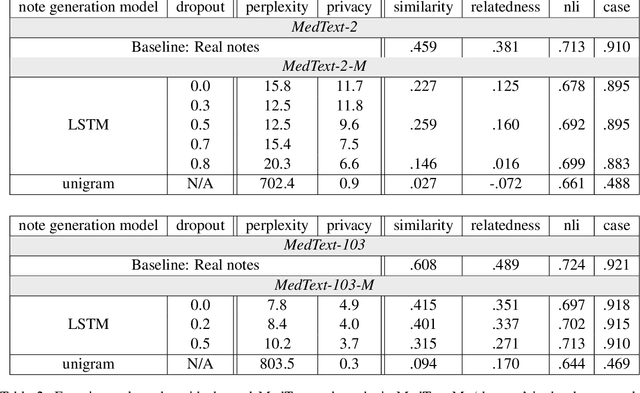
Large-scale clinical data is invaluable to driving many computational scientific advances today. However, understandable concerns regarding patient privacy hinder the open dissemination of such data and give rise to suboptimal siloed research. De-identification methods attempt to address these concerns but were shown to be susceptible to adversarial attacks. In this work, we focus on the vast amounts of unstructured natural language data stored in clinical notes and propose to automatically generate synthetic clinical notes that are more amenable to sharing using generative models trained on real de-identified records. To evaluate the merit of such notes, we measure both their privacy preservation properties as well as utility in training clinical NLP models. Experiments using neural language models yield notes whose utility is close to that of the real ones in some clinical NLP tasks, yet leave ample room for future improvements.
Self-Normalization Properties of Language Modeling
Jun 04, 2018
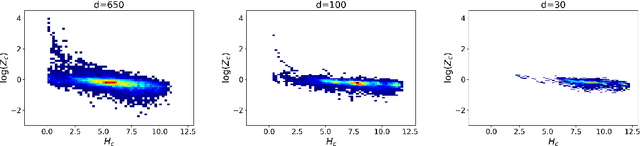
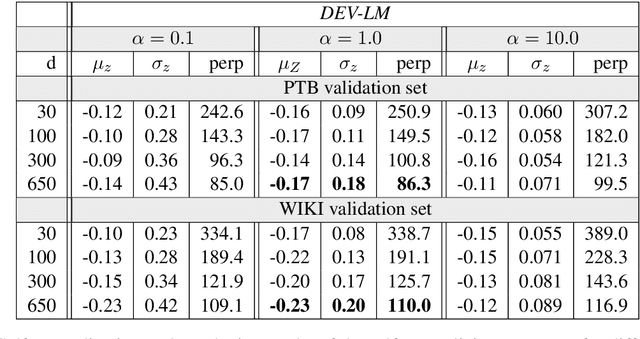

Self-normalizing discriminative models approximate the normalized probability of a class without having to compute the partition function. In the context of language modeling, this property is particularly appealing as it may significantly reduce run-times due to large word vocabularies. In this study, we provide a comprehensive investigation of language modeling self-normalization. First, we theoretically analyze the inherent self-normalization properties of Noise Contrastive Estimation (NCE) language models. Then, we compare them empirically to softmax-based approaches, which are self-normalized using explicit regularization, and suggest a hybrid model with compelling properties. Finally, we uncover a surprising negative correlation between self-normalization and perplexity across the board, as well as some regularity in the observed errors, which may potentially be used for improving self-normalization algorithms in the future.
The Role of Context Types and Dimensionality in Learning Word Embeddings
Jul 19, 2017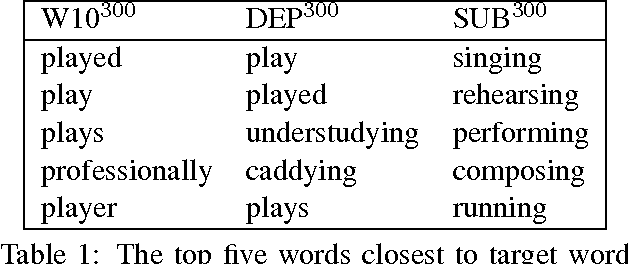
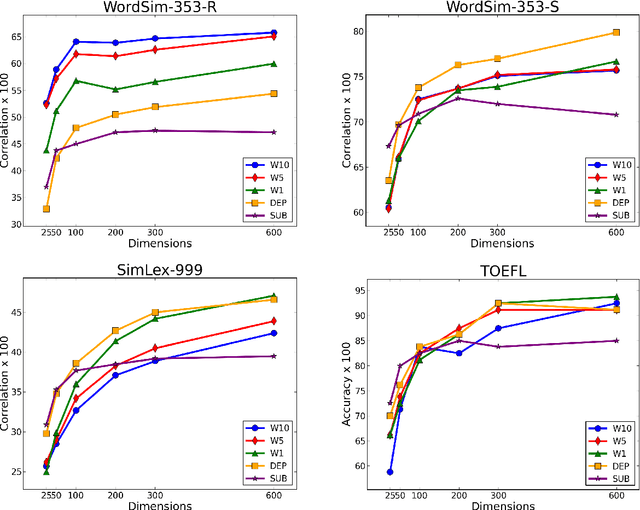
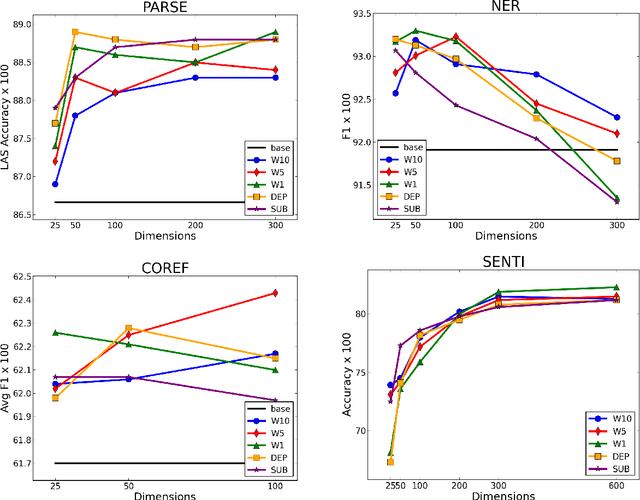
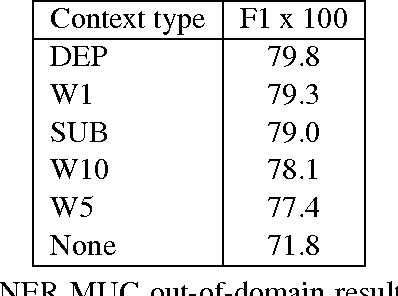
We provide the first extensive evaluation of how using different types of context to learn skip-gram word embeddings affects performance on a wide range of intrinsic and extrinsic NLP tasks. Our results suggest that while intrinsic tasks tend to exhibit a clear preference to particular types of contexts and higher dimensionality, more careful tuning is required for finding the optimal settings for most of the extrinsic tasks that we considered. Furthermore, for these extrinsic tasks, we find that once the benefit from increasing the embedding dimensionality is mostly exhausted, simple concatenation of word embeddings, learned with different context types, can yield further performance gains. As an additional contribution, we propose a new variant of the skip-gram model that learns word embeddings from weighted contexts of substitute words.
A Simple Language Model based on PMI Matrix Approximations
Jul 17, 2017
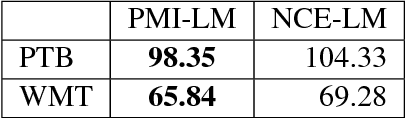
In this study, we introduce a new approach for learning language models by training them to estimate word-context pointwise mutual information (PMI), and then deriving the desired conditional probabilities from PMI at test time. Specifically, we show that with minor modifications to word2vec's algorithm, we get principled language models that are closely related to the well-established Noise Contrastive Estimation (NCE) based language models. A compelling aspect of our approach is that our models are trained with the same simple negative sampling objective function that is commonly used in word2vec to learn word embeddings.
PMI Matrix Approximations with Applications to Neural Language Modeling
Sep 05, 2016

The negative sampling (NEG) objective function, used in word2vec, is a simplification of the Noise Contrastive Estimation (NCE) method. NEG was found to be highly effective in learning continuous word representations. However, unlike NCE, it was considered inapplicable for the purpose of learning the parameters of a language model. In this study, we refute this assertion by providing a principled derivation for NEG-based language modeling, founded on a novel analysis of a low-dimensional approximation of the matrix of pointwise mutual information between the contexts and the predicted words. The obtained language modeling is closely related to NCE language models but is based on a simplified objective function. We thus provide a unified formulation for two main language processing tasks, namely word embedding and language modeling, based on the NEG objective function. Experimental results on two popular language modeling benchmarks show comparable perplexity results, with a small advantage to NEG over NCE.