 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Generation of Shareable Synthetic Clinical Notes Using Neural Language Models
Paper and Code
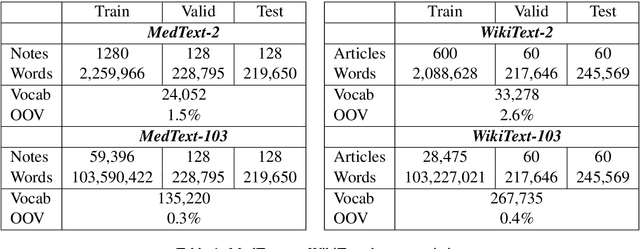

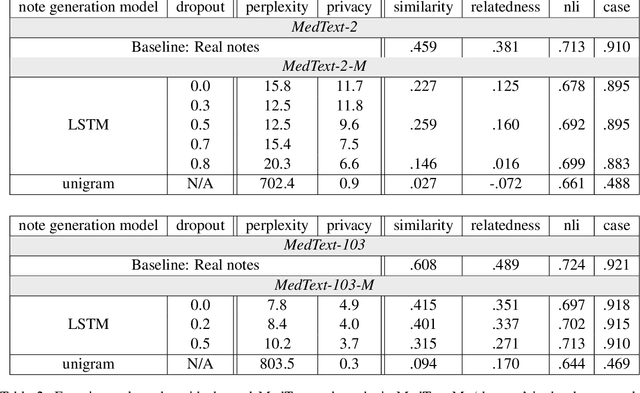
Large-scale clinical data is invaluable to driving many computational scientific advances today. However, understandable concerns regarding patient privacy hinder the open dissemination of such data and give rise to suboptimal siloed research. De-identification methods attempt to address these concerns but were shown to be susceptible to adversarial attacks. In this work, we focus on the vast amounts of unstructured natural language data stored in clinical notes and propose to automatically generate synthetic clinical notes that are more amenable to sharing using generative models trained on real de-identified records. To evaluate the merit of such notes, we measure both their privacy preservation properties as well as utility in training clinical NLP models. Experiments using neural language models yield notes whose utility is close to that of the real ones in some clinical NLP tasks, yet leave ample room for future improvements.