 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCANIA Component X Dataset: A Real-World Multivariate Time Series Dataset for Predictive Maintenance
Jan 26, 2024This paper presents a description of a real-world, multivariate time series dataset collected from an anonymized engine component (called Component X) of a fleet of trucks from SCANIA, Sweden. This dataset includes diverse variables capturing detailed operational data, repair records, and specifications of trucks while maintaining confidentiality by anonymization. It is well-suited for a range of machine learning applications, such as classification, regression, survival analysis, and anomaly detection, particularly when applied to predictive maintenance scenarios. The large population size and variety of features in the format of histograms and numerical counters, along with the inclusion of temporal information, make this real-world dataset unique in the field. The objective of releasing this dataset is to give a broad range of researchers the possibility of working with real-world data from an internationally well-known company and introduce a standard benchmark to the predictive maintenance field, fostering reproducible research.
Automotive Multilingual Fault Diagnosis
Oct 13, 2022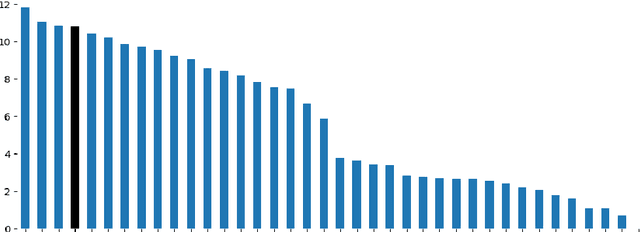

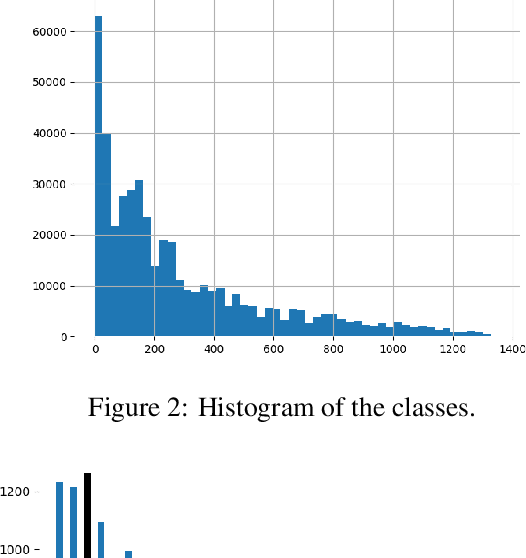
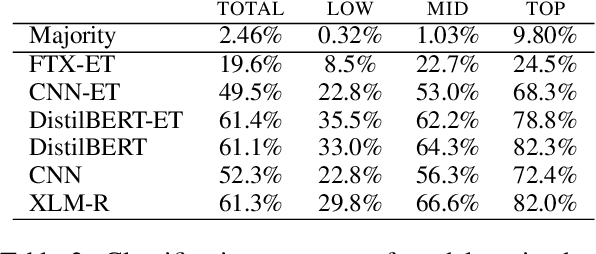
Automated fault diagnosis can facilitate diagnostics assistance, speedier troubleshooting, and better-organised logistics. Currently, AI-based prognostics and health management in the automotive industry ignore the textual descriptions of the experienced problems or symptoms. With this study, however, we show that a multilingual pre-trained Transformer can effectively classify the textual claims from a large company with vehicle fleets, despite the task's challenging nature due to the 38 languages and 1,357 classes involved. Overall, we report an accuracy of more than 80% for high-frequency classes and above 60% for above-low-frequency classes, bringing novel evidence that multilingual classification can benefit automotive troubleshooting management.