 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model is All You Need: ByT5-Sanskrit, a Unified Model for Sanskrit NLP Tasks
Sep 20, 2024Morphologically rich languages are notoriously challenging to process for downstream NLP applications. This paper presents a new pretrained language model, ByT5-Sanskrit, designed for NLP applications involving the morphologically rich language Sanskrit. We evaluate ByT5-Sanskrit on established Sanskrit word segmentation tasks, where it outperforms previous data-driven approaches by a considerable margin and matches the performance of the current best lexicon-based model. It is easier to deploy and more robust to data not covered by external linguistic resources. It also achieves new state-of-the-art results in Vedic Sanskrit dependency parsing and OCR post-correction tasks. Additionally, based on the Digital Corpus of Sanskrit, we introduce a novel multitask dataset for the joint training of Sanskrit word segmentation, lemmatization, and morphosyntactic tagging tasks. We fine-tune ByT5-Sanskrit on this dataset, creating a versatile multitask model for various downstream Sanskrit applications. We have used this model in Sanskrit linguistic annotation projects, in information retrieval setups, and as a preprocessing step in a Sanskrit machine translation pipeline. We also show that our approach yields new best scores for lemmatization and dependency parsing of other morphologically rich languages. We thus demonstrate that byte-level pretrained language models can achieve excellent performance for morphologically rich languages, outperforming tokenizer-based models and presenting an important vector of exploration when constructing NLP pipelines for such languages.
Evaluating Neural Morphological Taggers for Sanskrit
May 21, 2020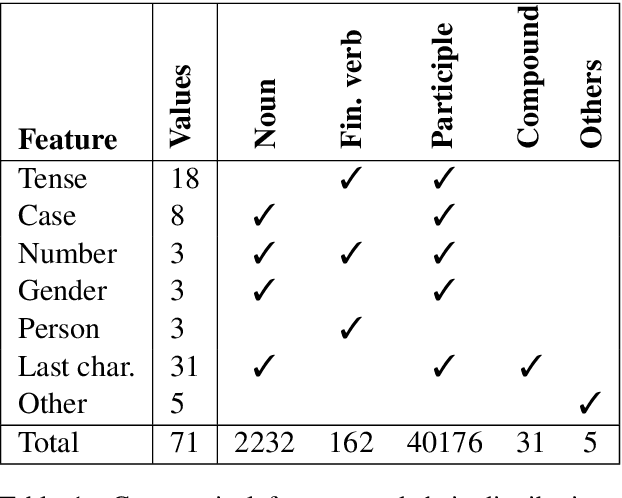
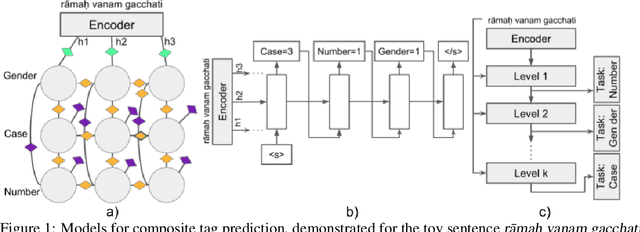
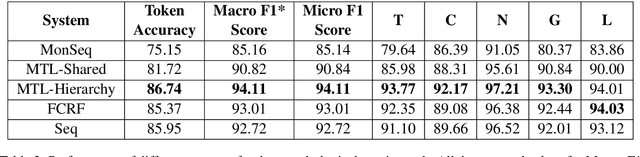
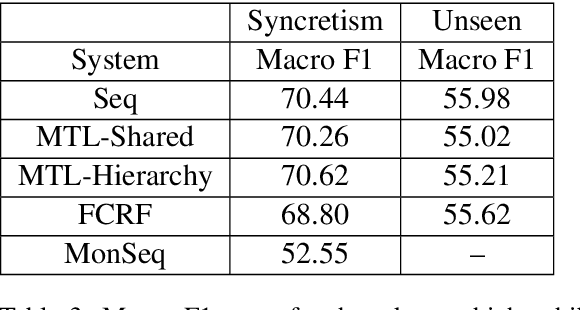
Neural sequence labelling approaches have achieved state of the art results in morphological tagging. We evaluate the efficacy of four standard sequence labelling models on Sanskrit, a morphologically rich, fusional Indian language. As its label space can theoretically contain more than 40,000 labels, systems that explicitly model the internal structure of a label are more suited for the task, because of their ability to generalise to labels not seen during training. We find that although some neural models perform better than others, one of the common causes for error for all of these models is mispredictions due to syncretism.