Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Neural Morphological Taggers for Sanskrit
Paper and Code
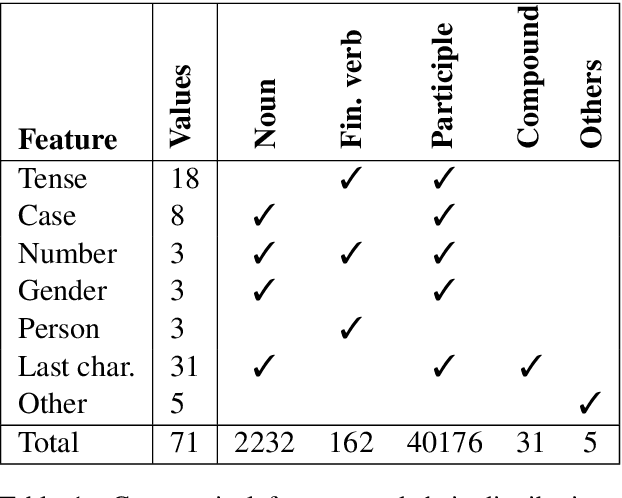
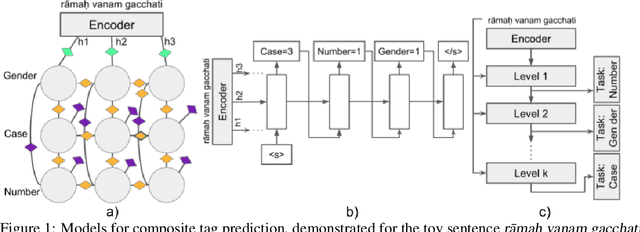
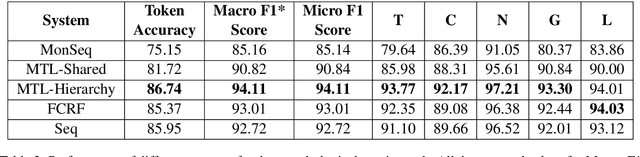
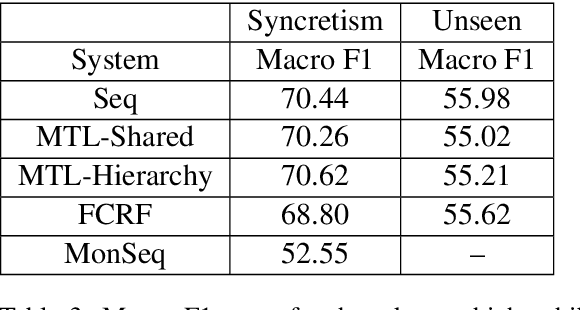
Neural sequence labelling approaches have achieved state of the art results in morphological tagging. We evaluate the efficacy of four standard sequence labelling models on Sanskrit, a morphologically rich, fusional Indian language. As its label space can theoretically contain more than 40,000 labels, systems that explicitly model the internal structure of a label are more suited for the task, because of their ability to generalise to labels not seen during training. We find that although some neural models perform better than others, one of the common causes for error for all of these models is mispredictions due to syncretism.
* Accepted to SIGMORPHON Workshop at ACL 2020
View paper on