 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT for Conversational Recommendation: Refining Recommendations by Reprompting with Feedback
Jan 07, 2024Recommendation algorithms have been pivotal in handling the overwhelming volume of online content. However, these algorithms seldom consider direct user input, resulting in superficial interaction between them. Efforts have been made to include the user directly in the recommendation process through conversation, but these systems too have had limited interactivity. Recently, Large Language Models (LLMs) like ChatGPT have gained popularity due to their ease of use and their ability to adapt dynamically to various tasks while responding to feedback. In this paper, we investigate the effectiveness of ChatGPT as a top-n conversational recommendation system. We build a rigorous pipeline around ChatGPT to simulate how a user might realistically probe the model for recommendations: by first instructing and then reprompting with feedback to refine a set of recommendations. We further explore the effect of popularity bias in ChatGPT's recommendations, and compare its performance to baseline models. We find that reprompting ChatGPT with feedback is an effective strategy to improve recommendation relevancy, and that popularity bias can be mitigated through prompt engineering.
Debiasing the Cloze Task in Sequential Recommendation with Bidirectional Transformers
Jan 22, 2023Bidirectional Transformer architectures are state-of-the-art sequential recommendation models that use a bi-directional representation capacity based on the Cloze task, a.k.a. Masked Language Modeling. The latter aims to predict randomly masked items within the sequence. Because they assume that the true interacted item is the most relevant one, an exposure bias results, where non-interacted items with low exposure propensities are assumed to be irrelevant. The most common approach to mitigating exposure bias in recommendation has been Inverse Propensity Scoring (IPS), which consists of down-weighting the interacted predictions in the loss function in proportion to their propensities of exposure, yielding a theoretically unbiased learning. In this work, we argue and prove that IPS does not extend to sequential recommendation because it fails to account for the temporal nature of the problem. We then propose a novel propensity scoring mechanism, which can theoretically debias the Cloze task in sequential recommendation. Finally we empirically demonstrate the debiasing capabilities of our proposed approach and its robustness to the severity of exposure bias.
* 10 pages, 3 figures, Accepted at KDD '22
Debiased Explainable Pairwise Ranking from Implicit Feedback
Jul 30, 2021
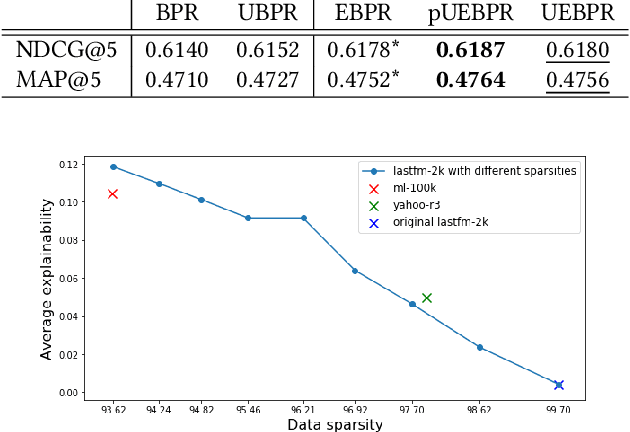


Recent work in recommender systems has emphasized the importance of fairness, with a particular interest in bias and transparency, in addition to predictive accuracy. In this paper, we focus on the state of the art pairwise ranking model, Bayesian Personalized Ranking (BPR), which has previously been found to outperform pointwise models in predictive accuracy, while also being able to handle implicit feedback. Specifically, we address two limitations of BPR: (1) BPR is a black box model that does not explain its outputs, thus limiting the user's trust in the recommendations, and the analyst's ability to scrutinize a model's outputs; and (2) BPR is vulnerable to exposure bias due to the data being Missing Not At Random (MNAR). This exposure bias usually translates into an unfairness against the least popular items because they risk being under-exposed by the recommender system. In this work, we first propose a novel explainable loss function and a corresponding Matrix Factorization-based model called Explainable Bayesian Personalized Ranking (EBPR) that generates recommendations along with item-based explanations. Then, we theoretically quantify additional exposure bias resulting from the explainability, and use it as a basis to propose an unbiased estimator for the ideal EBPR loss. The result is a ranking model that aptly captures both debiased and explainable user preferences. Finally, we perform an empirical study on three real-world datasets that demonstrate the advantages of our proposed models.
* 11 pages, 2 figures, Accepted at RecSys '21
Theoretical Modeling of the Iterative Properties of User Discovery in a Collaborative Filtering Recommender System
Aug 21, 2020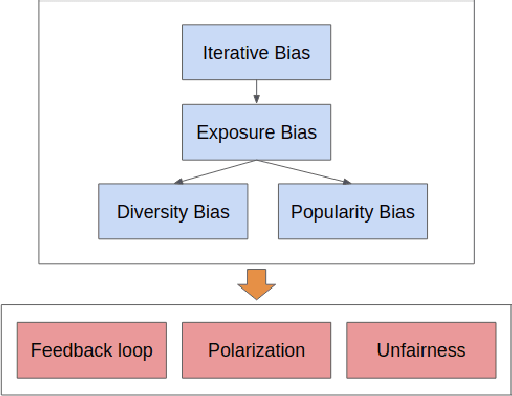


The closed feedback loop in recommender systems is a common setting that can lead to different types of biases. Several studies have dealt with these biases by designing methods to mitigate their effect on the recommendations. However, most existing studies do not consider the iterative behavior of the system where the closed feedback loop plays a crucial role in incorporating different biases into several parts of the recommendation steps. We present a theoretical framework to model the asymptotic evolution of the different components of a recommender system operating within a feedback loop setting, and derive theoretical bounds and convergence properties on quantifiable measures of the user discovery and blind spots. We also validate our theoretical findings empirically using a real-life dataset and empirically test the efficiency of a basic exploration strategy within our theoretical framework. Our findings lay the theoretical basis for quantifying the effect of feedback loops and for designing Artificial Intelligence and machine learning algorithms that explicitly incorporate the iterative nature of feedback loops in the machine learning and recommendation process.
Modeling and Counteracting Exposure Bias in Recommender Systems
Jan 01, 2020

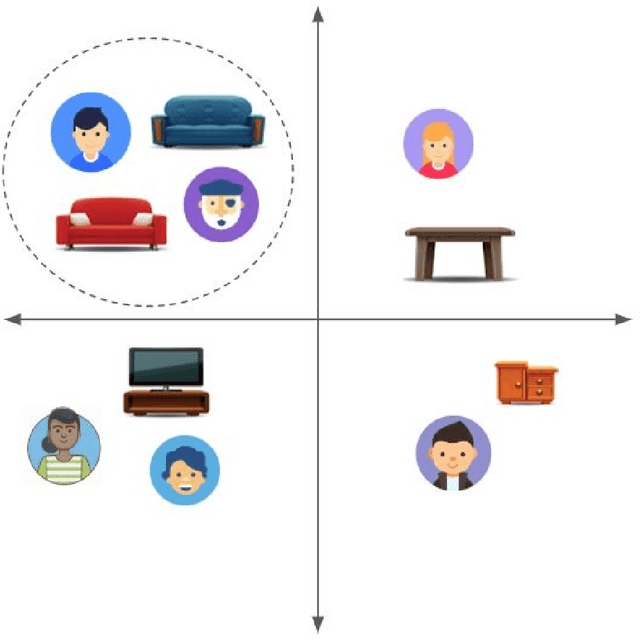

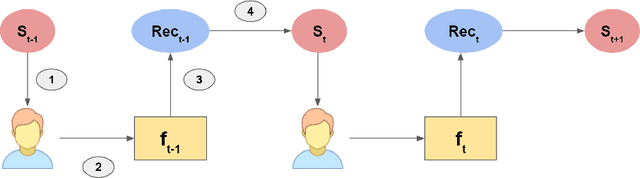
What we discover and see online, and consequently our opinions and decisions, are becoming increasingly affected by automated machine learned predictions. Similarly, the predictive accuracy of learning machines heavily depends on the feedback data that we provide them. This mutual influence can lead to closed-loop interactions that may cause unknown biases which can be exacerbated after several iterations of machine learning predictions and user feedback. Machine-caused biases risk leading to undesirable social effects ranging from polarization to unfairness and filter bubbles. In this paper, we study the bias inherent in widely used recommendation strategies such as matrix factorization. Then we model the exposure that is borne from the interaction between the user and the recommender system and propose new debiasing strategies for these systems. Finally, we try to mitigate the recommendation system bias by engineering solutions for several state of the art recommender system models. Our results show that recommender systems are biased and depend on the prior exposure of the user. We also show that the studied bias iteratively decreases diversity in the output recommendations. Our debiasing method demonstrates the need for alternative recommendation strategies that take into account the exposure process in order to reduce bias. Our research findings show the importance of understanding the nature of and dealing with bias in machine learning models such as recommender systems that interact directly with humans, and are thus causing an increasing influence on human discovery and decision making
An Explainable Autoencoder For Collaborative Filtering Recommendation
Dec 23, 2019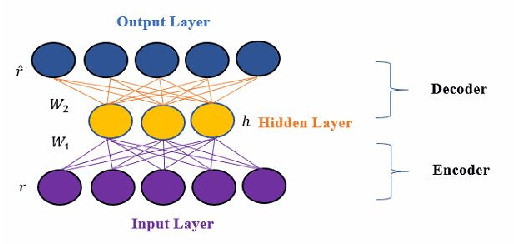

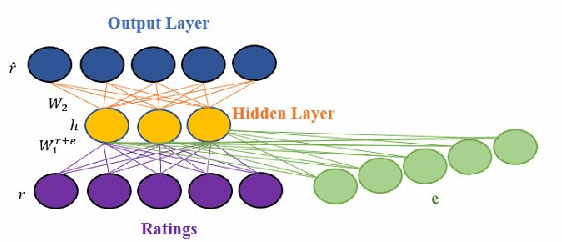

Autoencoders are a common building block of Deep Learning architectures, where they are mainly used for representation learning. They have also been successfully used in Collaborative Filtering (CF) recommender systems to predict missing ratings. Unfortunately, like all black box machine learning models, they are unable to explain their outputs. Hence, while predictions from an Autoencoder-based recommender system might be accurate, it might not be clear to the user why a recommendation was generated. In this work, we design an explainable recommendation system using an Autoencoder model whose predictions can be explained using the neighborhood based explanation style. Our preliminary work can be considered to be the first step towards an explainable deep learning architecture based on Autoencoders.
SeER: An Explainable Deep Learning MIDI-based Hybrid Song Recommender System
Jun 25, 2019

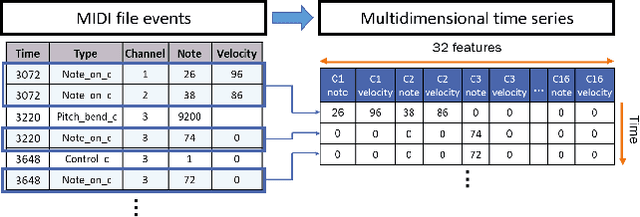
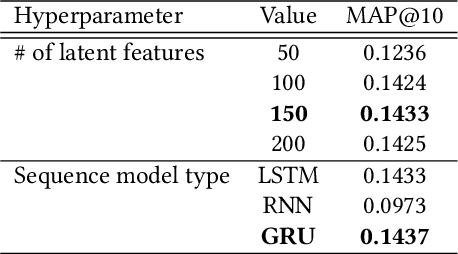
State of the art music recommender systems mainly rely on either Matrix factorization-based collaborative filtering approaches or deep learning architectures. Deep learning models usually use metadata for content-based filtering or predict the next user interaction by learning from temporal sequences of user actions. Despite advances in deep learning for song recommendation, none has taken advantage of the sequential nature of songs by learning sequence models that are based on content. Aside from the importance of prediction accuracy, other significant aspects are important, such as explainability and solving the cold start problem. In this work, we propose a hybrid deep learning structure, called "SeER", that uses collaborative filtering (CF) and deep learning sequence models on the MIDI content of songs for recommendation in order to provide more accurate personalized recommendations; solve the item cold start problem; and generate a relevant explanation for a song recommendation. Our evaluation experiments show promising results compared to state of the art baseline and hybrid song recommender systems in terms of ranking evaluation.
Human-Algorithm Interaction Biases in the Big Data Cycle: A Markov Chain Iterated Learning Framework
Aug 29, 2016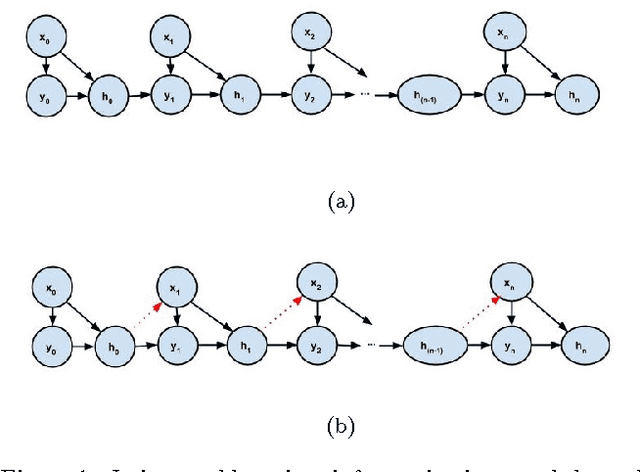
Early supervised machine learning algorithms have relied on reliable expert labels to build predictive models. However, the gates of data generation have recently been opened to a wider base of users who started participating increasingly with casual labeling, rating, annotating, etc. The increased online presence and participation of humans has led not only to a democratization of unchecked inputs to algorithms, but also to a wide democratization of the "consumption" of machine learning algorithms' outputs by general users. Hence, these algorithms, many of which are becoming essential building blocks of recommender systems and other information filters, started interacting with users at unprecedented rates. The result is machine learning algorithms that consume more and more data that is unchecked, or at the very least, not fitting conventional assumptions made by various machine learning algorithms. These include biased samples, biased labels, diverging training and testing sets, and cyclical interaction between algorithms, humans, information consumed by humans, and data consumed by algorithms. Yet, the continuous interaction between humans and algorithms is rarely taken into account in machine learning algorithm design and analysis. In this paper, we present a preliminary theoretical model and analysis of the mutual interaction between humans and algorithms, based on an iterated learning framework that is inspired from the study of human language evolution. We also define the concepts of human and algorithm blind spots and outline machine learning approaches to mend iterated bias through two novel notions: antidotes and reactive learning.
Explainable Restricted Boltzmann Machines for Collaborative Filtering
Jun 22, 2016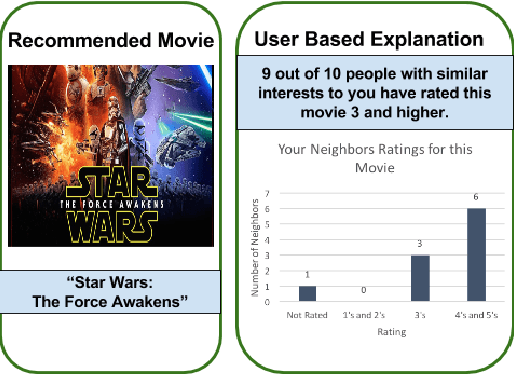


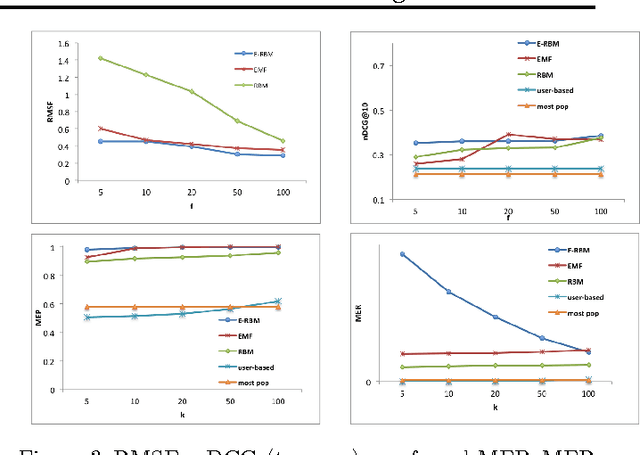
Most accurate recommender systems are black-box models, hiding the reasoning behind their recommendations. Yet explanations have been shown to increase the user's trust in the system in addition to providing other benefits such as scrutability, meaning the ability to verify the validity of recommendations. This gap between accuracy and transparency or explainability has generated an interest in automated explanation generation methods. Restricted Boltzmann Machines (RBM) are accurate models for CF that also lack interpretability. In this paper, we focus on RBM based collaborative filtering recommendations, and further assume the absence of any additional data source, such as item content or user attributes. We thus propose a new Explainable RBM technique that computes the top-n recommendation list from items that are explainable. Experimental results show that our method is effective in generating accurate and explainable recommendations.
Deep Learning of Part-based Representation of Data Using Sparse Autoencoders with Nonnegativity Constraints
Jan 12, 2016



We demonstrate a new deep learning autoencoder network, trained by a nonnegativity constraint algorithm (NCAE), that learns features which show part-based representation of data. The learning algorithm is based on constraining negative weights. The performance of the algorithm is assessed based on decomposing data into parts and its prediction performance is tested on three standard image data sets and one text dataset. The results indicate that the nonnegativity constraint forces the autoencoder to learn features that amount to a part-based representation of data, while improving sparsity and reconstruction quality in comparison with the traditional sparse autoencoder and Nonnegative Matrix Factorization. It is also shown that this newly acquired representation improves the prediction performance of a deep neural network.