 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Correlation of Features Extracted by Deep Neural Networks
Jan 30, 2019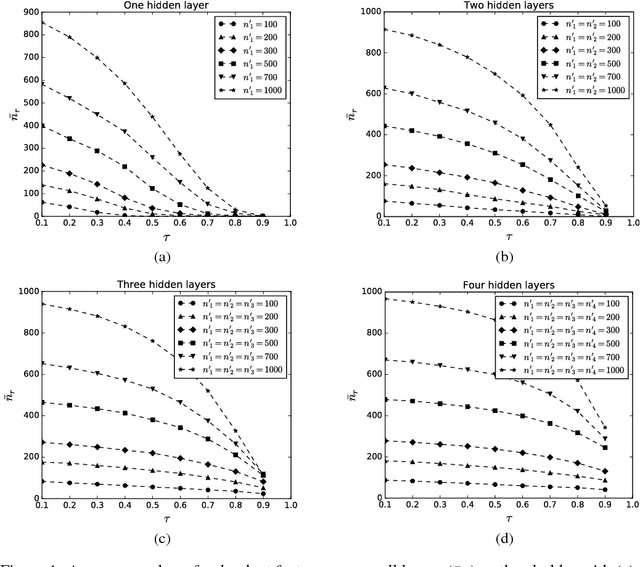
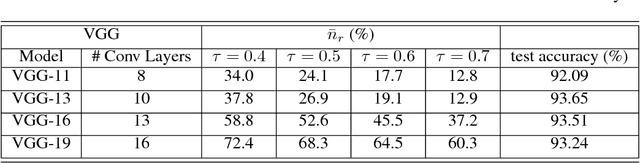
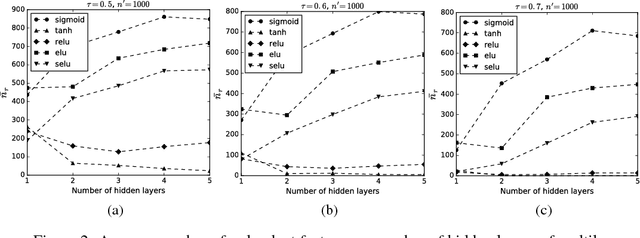
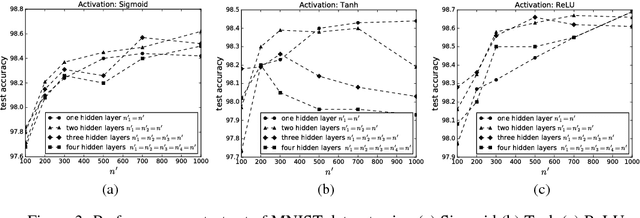
Redundancy in deep neural network (DNN) models has always been one of their most intriguing and important properties. DNNs have been shown to overparameterize, or extract a lot of redundant features. In this work, we explore the impact of size (both width and depth), activation function, and weight initialization on the susceptibility of deep neural network models to extract redundant features. To estimate the number of redundant features in each layer, all the features of a given layer are hierarchically clustered according to their relative cosine distances in feature space and a set threshold. It is shown that both network size and activation function are the two most important components that foster the tendency of DNNs to extract redundant features. The concept is illustrated using deep multilayer perceptron and convolutional neural networks on MNIST digits recognition and CIFAR-10 dataset, respectively.
Diversity Regularized Adversarial Learning
Jan 30, 2019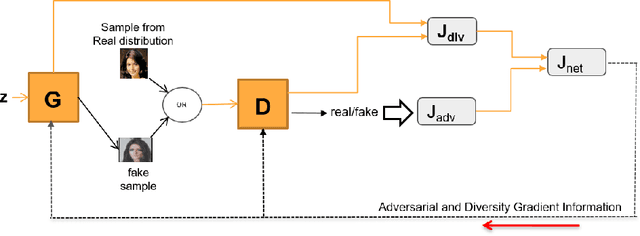
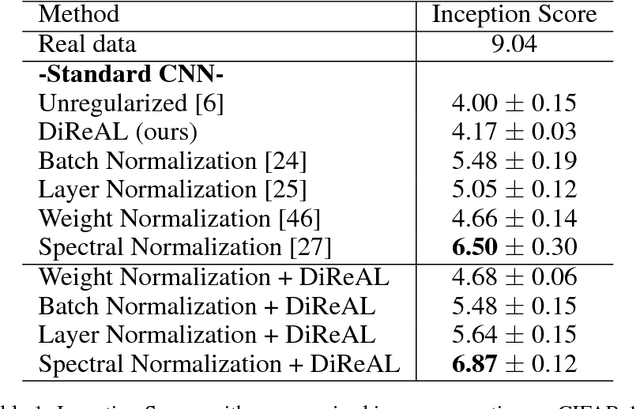
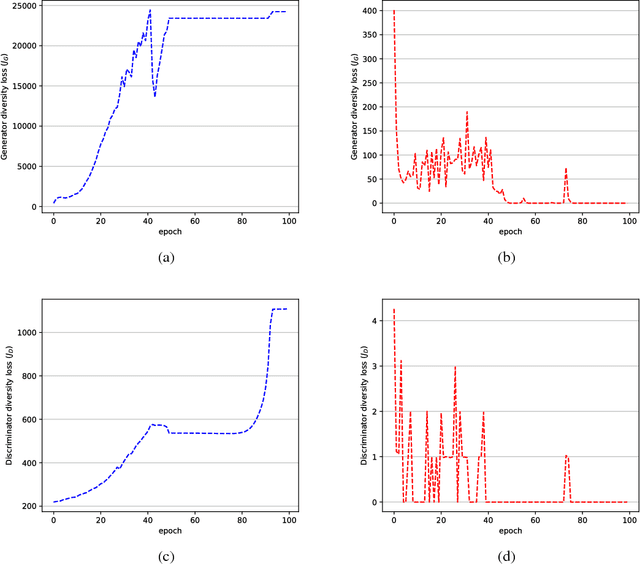
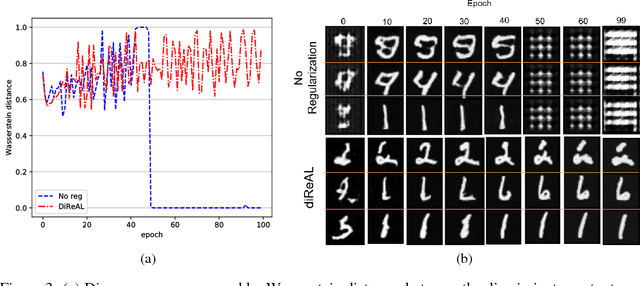
The two key players in Generative Adversarial Networks (GANs), the discriminator and generator, are usually parameterized as deep neural networks (DNNs). On many generative tasks, GANs achieve state-of-the-art performance but are often unstable to train and sometimes miss modes. A typical failure mode is the collapse of the generator to a single parameter configuration where its outputs are identical. When this collapse occurs, the gradient of the discriminator may point in similar directions for many similar points. We hypothesize that some of these shortcomings are in part due to primitive and redundant features extracted by discriminator and this can easily make the training stuck. We present a novel approach for regularizing adversarial models by enforcing diverse feature learning. In order to do this, both generator and discriminator are regularized by penalizing both negatively and positively correlated features according to their differentiation and based on their relative cosine distances. In addition to the gradient information from the adversarial loss made available by the discriminator, diversity regularization also ensures that a more stable gradient is provided to update both the generator and discriminator. Results indicate our regularizer enforces diverse features, stabilizes training, and improves image synthesis.
Building Efficient ConvNets using Redundant Feature Pruning
Feb 21, 2018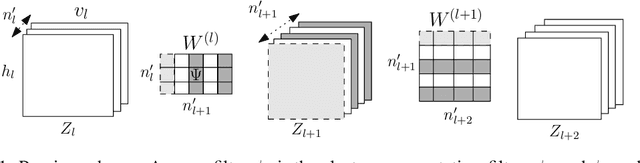
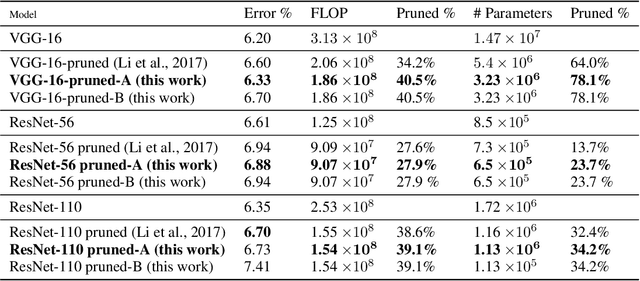
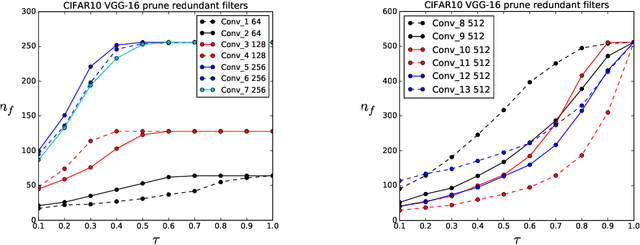
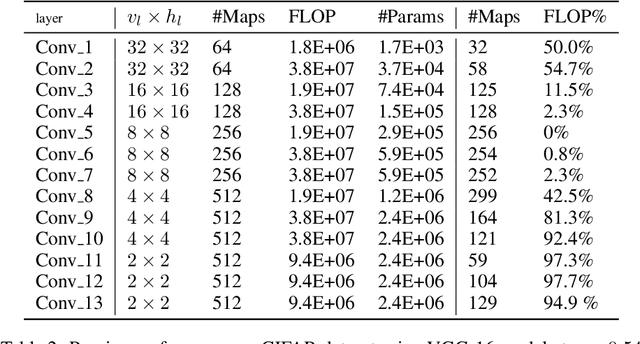
This paper presents an efficient technique to prune deep and/or wide convolutional neural network models by eliminating redundant features (or filters). Previous studies have shown that over-sized deep neural network models tend to produce a lot of redundant features that are either shifted version of one another or are very similar and show little or no variations; thus resulting in filtering redundancy. We propose to prune these redundant features along with their connecting feature maps according to their differentiation and based on their relative cosine distances in the feature space, thus yielding smaller network size with reduced inference costs and competitive performance. We empirically show on select models and CIFAR-10 dataset that inference costs can be reduced by 40% for VGG-16, 27% for ResNet-56, and 39% for ResNet-110.
Deep Learning of Constrained Autoencoders for Enhanced Understanding of Data
Feb 03, 2018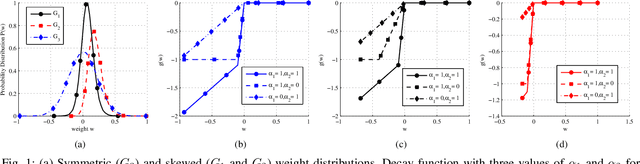

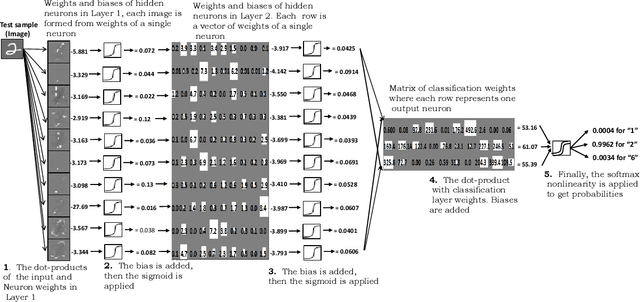
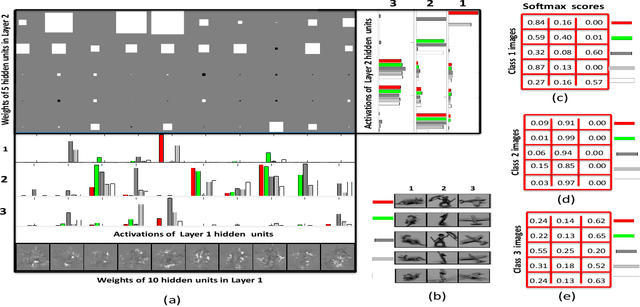
Unsupervised feature extractors are known to perform an efficient and discriminative representation of data. Insight into the mappings they perform and human ability to understand them, however, remain very limited. This is especially prominent when multilayer deep learning architectures are used. This paper demonstrates how to remove these bottlenecks within the architecture of Nonnegativity Constrained Autoencoder (NCSAE). It is shown that by using both L1 and L2 regularization that induce nonnegativity of weights, most of the weights in the network become constrained to be nonnegative thereby resulting into a more understandable structure with minute deterioration in classification accuracy. Also, this proposed approach extracts features that are more sparse and produces additional output layer sparsification. The method is analyzed for accuracy and feature interpretation on the MNIST data, the NORB normalized uniform object data, and the Reuters text categorization dataset.
Deep Learning of Part-based Representation of Data Using Sparse Autoencoders with Nonnegativity Constraints
Jan 12, 2016



We demonstrate a new deep learning autoencoder network, trained by a nonnegativity constraint algorithm (NCAE), that learns features which show part-based representation of data. The learning algorithm is based on constraining negative weights. The performance of the algorithm is assessed based on decomposing data into parts and its prediction performance is tested on three standard image data sets and one text dataset. The results indicate that the nonnegativity constraint forces the autoencoder to learn features that amount to a part-based representation of data, while improving sparsity and reconstruction quality in comparison with the traditional sparse autoencoder and Nonnegative Matrix Factorization. It is also shown that this newly acquired representation improves the prediction performance of a deep neural network.