 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Correlation of Features Extracted by Deep Neural Networks
Paper and Code
Jan 30, 2019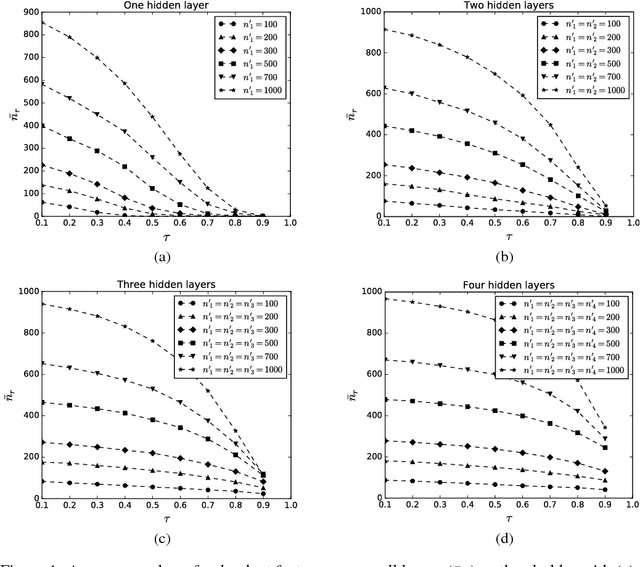
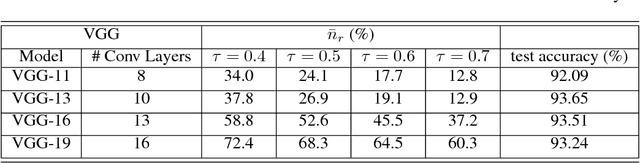
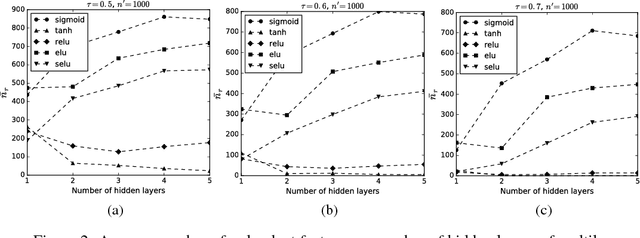
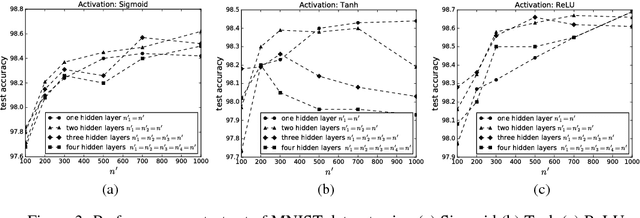
Redundancy in deep neural network (DNN) models has always been one of their most intriguing and important properties. DNNs have been shown to overparameterize, or extract a lot of redundant features. In this work, we explore the impact of size (both width and depth), activation function, and weight initialization on the susceptibility of deep neural network models to extract redundant features. To estimate the number of redundant features in each layer, all the features of a given layer are hierarchically clustered according to their relative cosine distances in feature space and a set threshold. It is shown that both network size and activation function are the two most important components that foster the tendency of DNNs to extract redundant features. The concept is illustrated using deep multilayer perceptron and convolutional neural networks on MNIST digits recognition and CIFAR-10 dataset, respectively.