 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning of Constrained Autoencoders for Enhanced Understanding of Data
Paper and Code
Feb 03, 2018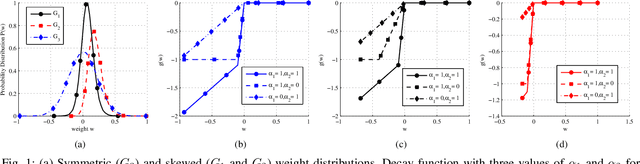

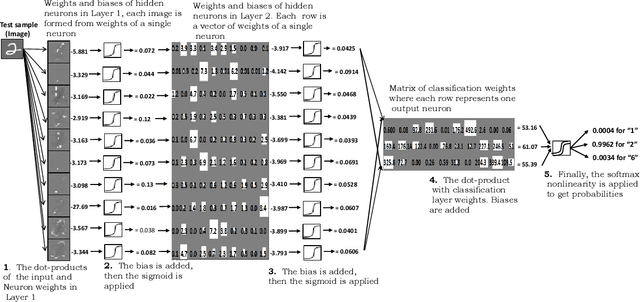
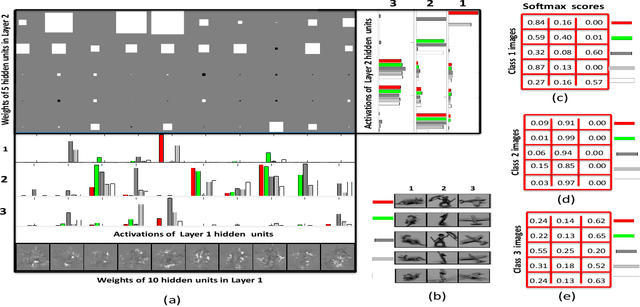
Unsupervised feature extractors are known to perform an efficient and discriminative representation of data. Insight into the mappings they perform and human ability to understand them, however, remain very limited. This is especially prominent when multilayer deep learning architectures are used. This paper demonstrates how to remove these bottlenecks within the architecture of Nonnegativity Constrained Autoencoder (NCSAE). It is shown that by using both L1 and L2 regularization that induce nonnegativity of weights, most of the weights in the network become constrained to be nonnegative thereby resulting into a more understandable structure with minute deterioration in classification accuracy. Also, this proposed approach extracts features that are more sparse and produces additional output layer sparsification. The method is analyzed for accuracy and feature interpretation on the MNIST data, the NORB normalized uniform object data, and the Reuters text categorization dataset.