 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Monte Carlo Meta-Learning of Optimal Prediction Procedures
Feb 26, 2020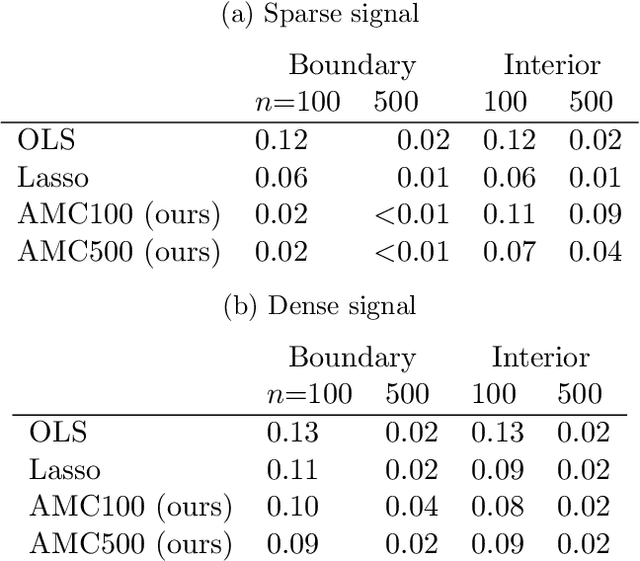
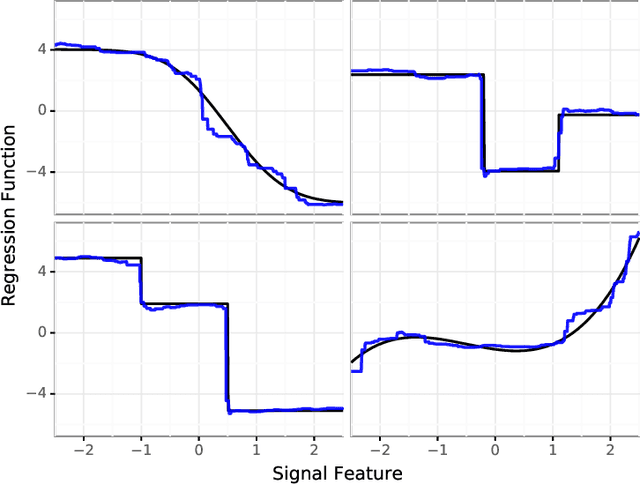
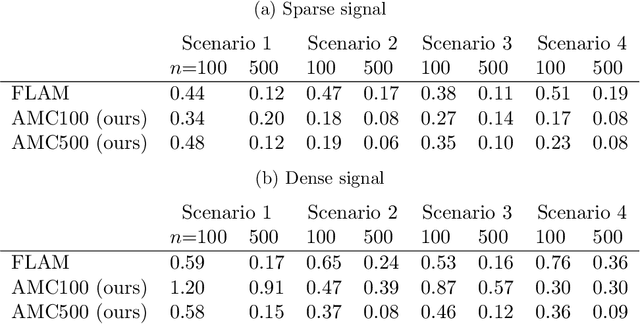
We frame the meta-learning of prediction procedures as a search for an optimal strategy in a two-player game. In this game, Nature selects a prior over distributions that generate labeled data consisting of features and an associated outcome, and the Predictor observes data sampled from a distribution drawn from this prior. The Predictor's objective is to learn a function that maps from a new feature to an estimate of the associated outcome. We establish that, under reasonable conditions, the Predictor has an optimal strategy that is equivariant to shifts and rescalings of the outcome and is invariant to permutations of the observations and to shifts, rescalings, and permutations of the features. We introduce a neural network architecture that satisfies these properties. The proposed strategy performs favorably compared to standard practice in both parametric and nonparametric experiments.
Targeted Learning with Daily EHR Data
May 27, 2017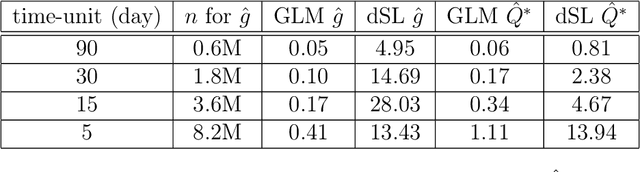


Electronic health records (EHR) data provide a cost and time-effective opportunity to conduct cohort studies of the effects of multiple time-point interventions in the diverse patient population found in real-world clinical settings. Because the computational cost of analyzing EHR data at daily (or more granular) scale can be quite high, a pragmatic approach has been to partition the follow-up into coarser intervals of pre-specified length. Current guidelines suggest employing a 'small' interval, but the feasibility and practical impact of this recommendation has not been evaluated and no formal methodology to inform this choice has been developed. We start filling these gaps by leveraging large-scale EHR data from a diabetes study to develop and illustrate a fast and scalable targeted learning approach that allows to follow the current recommendation and study its practical impact on inference. More specifically, we map daily EHR data into four analytic datasets using 90, 30, 15 and 5-day intervals. We apply a semi-parametric and doubly robust estimation approach, the longitudinal TMLE, to estimate the causal effects of four dynamic treatment rules with each dataset, and compare the resulting inferences. To overcome the computational challenges presented by the size of these data, we propose a novel TMLE implementation, the 'long-format TMLE', and rely on the latest advances in scalable data-adaptive machine-learning software, xgboost and h2o, for estimation of the TMLE nuisance parameters.