 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discovery of Formulas for Mathematical Constants
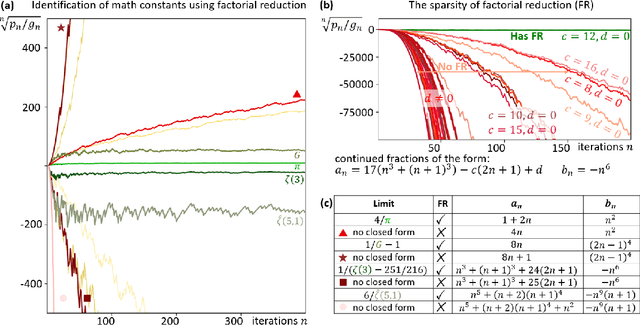
Dec 22, 2024Ongoing efforts that span over decades show a rise of AI methods for accelerating scientific discovery, yet accelerating discovery in mathematics remains a persistent challenge for AI. Specifically, AI methods were not effective in creation of formulas for mathematical constants because each such formula must be correct for infinite digits of precision, with "near-true" formulas providing no insight toward the correct ones. Consequently, formula discovery lacks a clear distance metric needed to guide automated discovery in this realm. In this work, we propose a systematic methodology for categorization, characterization, and pattern identification of such formulas. The key to our methodology is introducing metrics based on the convergence dynamics of the formulas, rather than on the numerical value of the formula. These metrics enable the first automated clustering of mathematical formulas. We demonstrate this methodology on Polynomial Continued Fraction formulas, which are ubiquitous in their intrinsic connections to mathematical constants, and generalize many mathematical functions and structures. We test our methodology on a set of 1,768,900 such formulas, identifying many known formulas for mathematical constants, and discover previously unknown formulas for $\pi$, $\ln(2)$, Gauss', and Lemniscate's constants. The uncovered patterns enable a direct generalization of individual formulas to infinite families, unveiling rich mathematical structures. This success paves the way towards a generative model that creates formulas fulfilling specified mathematical properties, accelerating the rate of discovery of useful formulas.
* 8 figures, 5 tables, 28 pages including the supplementary information. For a 5-minute video abstract see https://recorder-v3.slideslive.com/#/share?share=97010&s=c47967e3-d585-453c-a4dd-a4fa7955dba3 . Code can be found at https://github.com/RamanujanMachine/Blind-Delta-Algorithm
Algorithm-assisted discovery of an intrinsic order among mathematical constants
Aug 22, 2023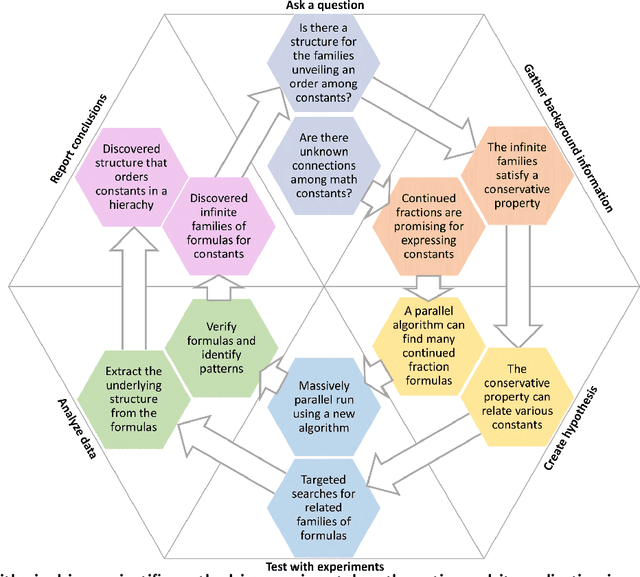


In recent decades, a growing number of discoveries in fields of mathematics have been assisted by computer algorithms, primarily for exploring large parameter spaces that humans would take too long to investigate. As computers and algorithms become more powerful, an intriguing possibility arises - the interplay between human intuition and computer algorithms can lead to discoveries of novel mathematical concepts that would otherwise remain elusive. To realize this perspective, we have developed a massively parallel computer algorithm that discovers an unprecedented number of continued fraction formulas for fundamental mathematical constants. The sheer number of formulas discovered by the algorithm unveils a novel mathematical structure that we call the conservative matrix field. Such matrix fields (1) unify thousands of existing formulas, (2) generate infinitely many new formulas, and most importantly, (3) lead to unexpected relations between different mathematical constants, including multiple integer values of the Riemann zeta function. Conservative matrix fields also enable new mathematical proofs of irrationality. In particular, we can use them to generalize the celebrated proof by Ap\'ery for the irrationality of $\zeta(3)$. Utilizing thousands of personal computers worldwide, our computer-supported research strategy demonstrates the power of experimental mathematics, highlighting the prospects of large-scale computational approaches to tackle longstanding open problems and discover unexpected connections across diverse fields of science.
Automated Search for Conjectures on Mathematical Constants using Analysis of Integer Sequences
Dec 13, 2022Formulas involving fundamental mathematical constants had a great impact on various fields of science and mathematics, for example aiding in proofs of irrationality of constants. However, the discovery of such formulas has historically remained scarce, often perceived as an act of mathematical genius by great mathematicians such as Ramanujan, Euler, and Gauss. Recent efforts to automate the discovery of formulas for mathematical constants, such as the Ramanujan Machine project, relied on exhaustive search. Despite several successful discoveries, exhaustive search remains limited by the space of options that can be covered and by the need for vast amounts of computational resources. Here we propose a fundamentally different method to search for conjectures on mathematical constants: through analysis of integer sequences. We introduce the Enumerated Signed-continued-fraction Massey Approve (ESMA) algorithm, which builds on the Berlekamp-Massey algorithm to identify patterns in integer sequences that represent mathematical constants. The ESMA algorithm found various known formulas for $e, e^2, tan(1)$, and ratios of values of Bessel functions. The algorithm further discovered a large number of new conjectures for these constants, some providing simpler representations and some providing faster numerical convergence than the corresponding simple continued fractions. Along with the algorithm, we present mathematical tools for manipulating continued fractions. These connections enable us to characterize what space of constants can be found by ESMA and quantify its algorithmic advantage in certain scenarios. Altogether, this work continues in the development of augmenting mathematical intuition by computer algorithms, to help reveal mathematical structures and accelerate mathematical research.
On statistical learning via the lens of compression
Dec 30, 2016This work continues the study of the relationship between sample compression schemes and statistical learning, which has been mostly investigated within the framework of binary classification. The central theme of this work is establishing equivalences between learnability and compressibility, and utilizing these equivalences in the study of statistical learning theory. We begin with the setting of multiclass categorization (zero/one loss). We prove that in this case learnability is equivalent to compression of logarithmic sample size, and that uniform convergence implies compression of constant size. We then consider Vapnik's general learning setting: we show that in order to extend the compressibility-learnability equivalence to this case, it is necessary to consider an approximate variant of compression. Finally, we provide some applications of the compressibility-learnability equivalences: (i) Agnostic-case learnability and realizable-case learnability are equivalent in multiclass categorization problems (in terms of sample complexity). (ii) This equivalence between agnostic-case learnability and realizable-case learnability does not hold for general learning problems: There exists a learning problem whose loss function takes just three values, under which agnostic-case and realizable-case learnability are not equivalent. (iii) Uniform convergence implies compression of constant size in multiclass categorization problems. Part of the argument includes an analysis of the uniform convergence rate in terms of the graph dimension, in which we improve upon previous bounds. (iv) A dichotomy for sample compression in multiclass categorization problems: If a non-trivial compression exists then a compression of logarithmic size exists. (v) A compactness theorem for multiclass categorization problems.