 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding AI-in-Education Development in Teachers' Voices: Findings from a National Survey in Indonesia
Apr 02, 2026Despite emerging use in Indonesian classrooms, there is limited large-scale, teacher-centred evidence on how AI is used in practice and what support teachers need, hindering the development of context-appropriate AI systems and policies. To address this gap, we conduct a nationwide survey of 349 K-12 teachers across elementary, junior high, and senior high schools. We find increasing use of AI for pedagogy, content development, and teaching media, although adoption remains uneven. Elementary teachers report more consistent use, while senior high teachers engage less; mid-career teachers assign higher importance to AI, and teachers in Eastern Indonesia perceive greater value. Across levels, teachers primarily use AI to reduce instructional preparation workload (e.g., assessment, lesson planning, and material development). However, generic outputs, infrastructure constraints, and limited contextual alignment continue to hinder effective classroom integration.
Evaluating Vision-Language and Large Language Models for Automated Student Assessment in Indonesian Classrooms
Jun 05, 2025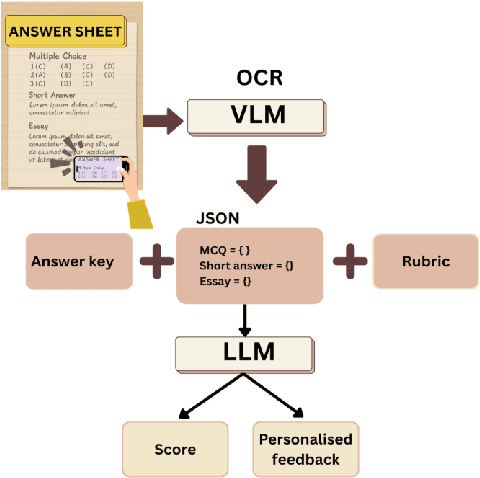
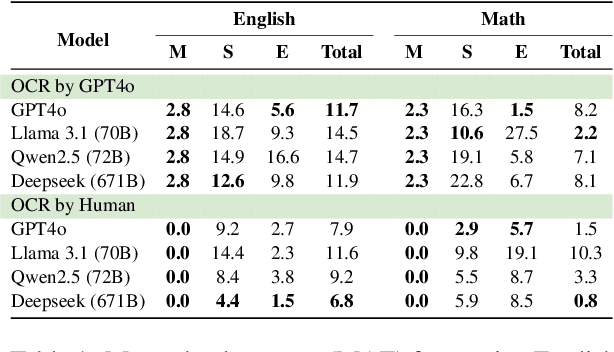
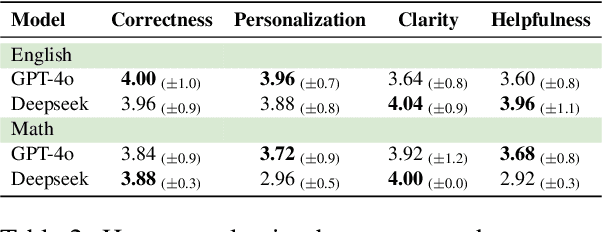

Although vision-language and large language models (VLM and LLM) offer promising opportunities for AI-driven educational assessment, their effectiveness in real-world classroom settings, particularly in underrepresented educational contexts, remains underexplored. In this study, we evaluated the performance of a state-of-the-art VLM and several LLMs on 646 handwritten exam responses from grade 4 students in six Indonesian schools, covering two subjects: Mathematics and English. These sheets contain more than 14K student answers that span multiple choice, short answer, and essay questions. Assessment tasks include grading these responses and generating personalized feedback. Our findings show that the VLM often struggles to accurately recognize student handwriting, leading to error propagation in downstream LLM grading. Nevertheless, LLM-generated feedback retains some utility, even when derived from imperfect input, although limitations in personalization and contextual relevance persist.
IndoCulture: Exploring Geographically-Influenced Cultural Commonsense Reasoning Across Eleven Indonesian Provinces
Apr 02, 2024Although commonsense reasoning is greatly shaped by cultural and geographical factors, previous studies on language models have predominantly centered on English cultures, potentially resulting in an Anglocentric bias. In this paper, we introduce IndoCulture, aimed at understanding the influence of geographical factors on language model reasoning ability, with a specific emphasis on the diverse cultures found within eleven Indonesian provinces. In contrast to prior works that relied on templates (Yin et al., 2022) and online scrapping (Fung et al., 2024), we created IndoCulture by asking local people to manually develop the context and plausible options based on predefined topics. Evaluations of 23 language models reveal several insights: (1) even the best open-source model struggles with an accuracy of 53.2%, (2) models often provide more accurate predictions for specific provinces, such as Bali and West Java, and (3) the inclusion of location contexts enhances performance, especially in larger models like GPT-4, emphasizing the significance of geographical context in commonsense reasoning.
Large Language Models Only Pass Primary School Exams in Indonesia: A Comprehensive Test on IndoMMLU
Oct 07, 2023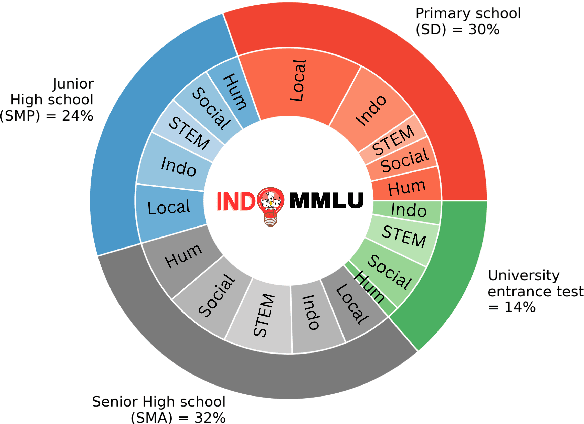
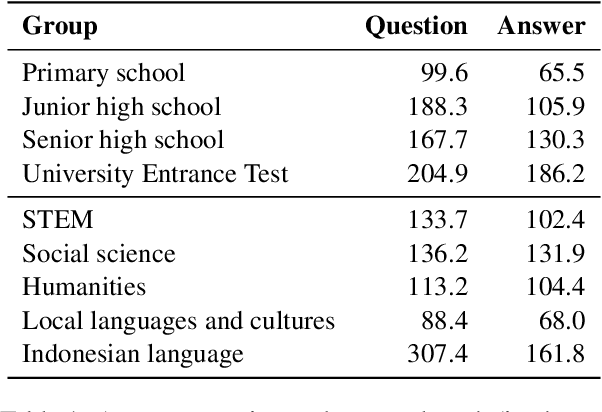

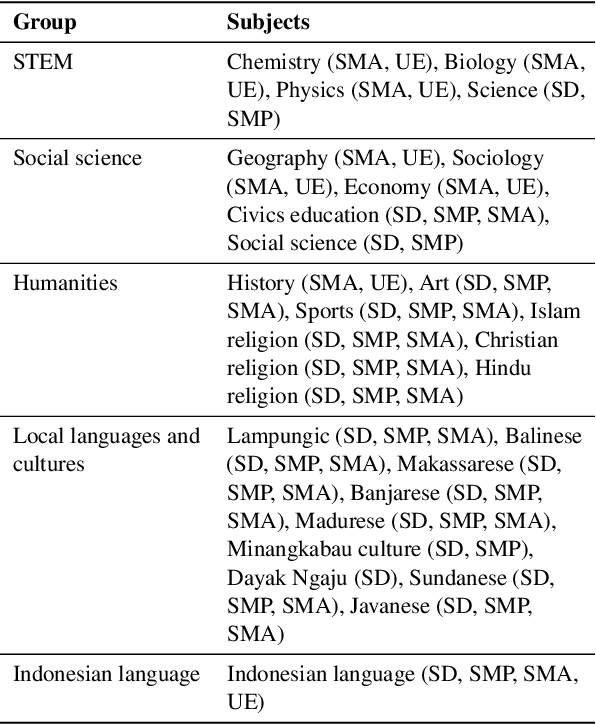
Large language models have made significant advancements in natural language processing (NLP), exhibiting human performance across various classic NLP tasks. These tasks, however, focus on structure and semantics, and few are designed to assess reasoning abilities and real-world knowledge, which are increasingly vital given that these models are trained on extensive textual data and information. While prior research primarily focuses on English, in this work, we gather a collection of exam problems from primary school to university entrance tests in Indonesia, and evaluate whether large language models can pass the exams. We obtain 14,906 questions across 63 tasks and levels, with 46\% of the questions focusing on assessing proficiency in the Indonesian language and knowledge of nine local languages and cultures in Indonesia. Our empirical evaluations show that GPT-3.5 only manages to pass the Indonesian primary school level, with limited knowledge of the Indonesian local languages and cultures. Other smaller models such as BLOOMZ and Falcon fail the exams.