 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Only Pass Primary School Exams in Indonesia: A Comprehensive Test on IndoMMLU
Paper and Code
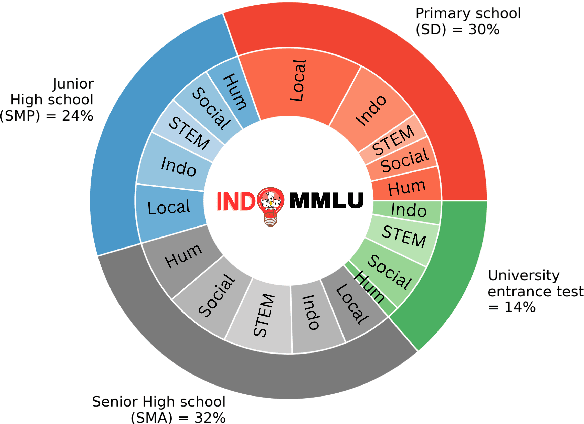
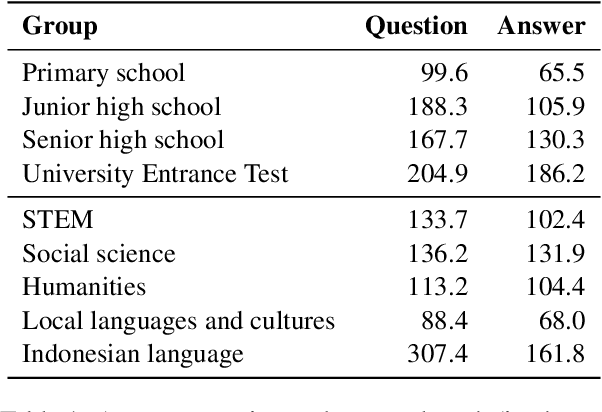

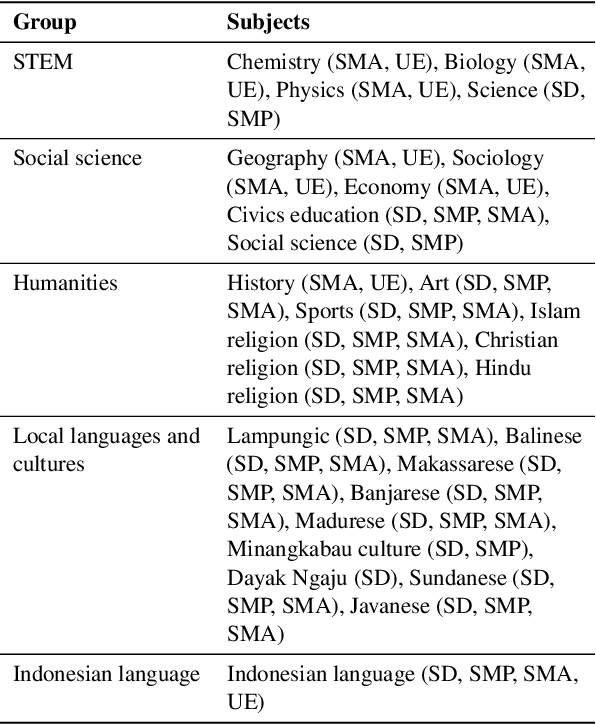
Large language models have made significant advancements in natural language processing (NLP), exhibiting human performance across various classic NLP tasks. These tasks, however, focus on structure and semantics, and few are designed to assess reasoning abilities and real-world knowledge, which are increasingly vital given that these models are trained on extensive textual data and information. While prior research primarily focuses on English, in this work, we gather a collection of exam problems from primary school to university entrance tests in Indonesia, and evaluate whether large language models can pass the exams. We obtain 14,906 questions across 63 tasks and levels, with 46\% of the questions focusing on assessing proficiency in the Indonesian language and knowledge of nine local languages and cultures in Indonesia. Our empirical evaluations show that GPT-3.5 only manages to pass the Indonesian primary school level, with limited knowledge of the Indonesian local languages and cultures. Other smaller models such as BLOOMZ and Falcon fail the exams.