 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Ignore: Domain Adaptation for Multi-Site MRI Analysis
Oct 13, 2021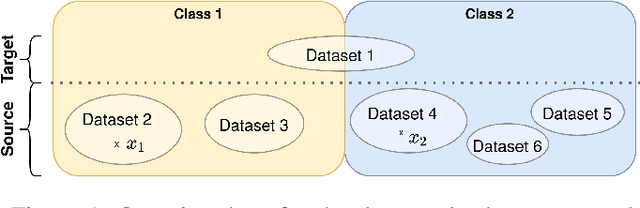

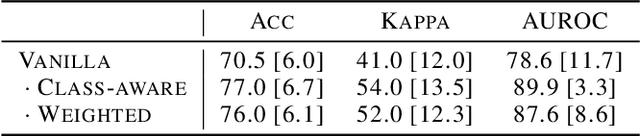
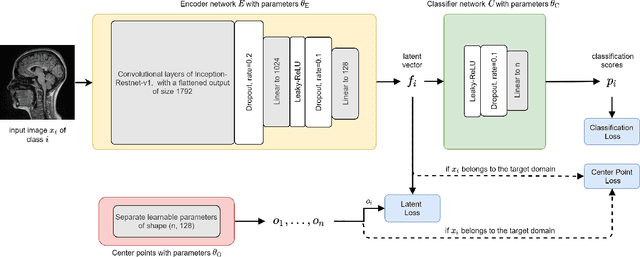
Limited availability of large image datasets is a major issue in the development of accurate and generalizable machine learning methods in medicine. The limitations in the amount of data are mainly due to the use of different acquisition protocols, different hardware, and data privacy. At the same time, training a classification model on a small dataset leads to a poor generalization quality of the model. To overcome this issue, a combination of various image datasets of different provenance is often used, e.g., multi-site studies. However, if an additional dataset does not include all classes of the task, the learning of the classification model can be biased to the device or place of acquisition. This is especially the case for Magnetic Resonance (MR) images, where different MR scanners introduce a bias that limits the performance of the model. In this paper, we present a novel method that learns to ignore the scanner-related features present in the images, while learning features relevant for the classification task. We focus on a real-world scenario, where only a small dataset provides images of all classes. We exploit this circumstance by introducing specific additional constraints on the latent space, which lead the focus on disease-related rather than scanner-specific features. Our method Learn to Ignore outperforms state-of-the-art domain adaptation methods on a multi-site MRI dataset on a classification task between Multiple Sclerosis patients and healthy subjects.