 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Interested Agents in Collaborative Learning: An Incentivized Adaptive Data-Centric Framework
Dec 09, 2024

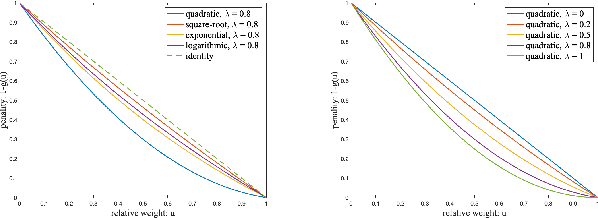
We propose a framework for adaptive data-centric collaborative learning among self-interested agents, coordinated by an arbiter. Designed to handle the incremental nature of real-world data, the framework operates in an online manner: at each step, the arbiter collects a batch of data from agents, trains a machine learning model, and provides each agent with a distinct model reflecting its data contributions. This setup establishes a feedback loop where shared data influence model updates, and the resulting models guide future data-sharing strategies. Agents evaluate and partition their data, selecting a partition to share using a stochastic parameterized policy optimized via policy gradient methods to optimize the utility of the received model as defined by agent-specific evaluation functions. On the arbiter side, the expected loss function over the true data distribution is optimized, incorporating agent-specific weights to account for distributional differences arising from diverse sources and selective sharing. A bilevel optimization algorithm jointly learns the model parameters and agent-specific weights. Mean-zero noise, computed using a distortion function that adjusts these agent-specific weights, is introduced to generate distinct agent-specific models, promoting valuable data sharing without requiring separate training. Our framework is underpinned by non-asymptotic analyses, ensuring convergence of the agent-side policy optimization to an approximate stationary point of the evaluation functions and convergence of the arbiter-side optimization to an approximate stationary point of the expected loss function.
Approximate gradient ascent methods for distortion risk measures
Feb 22, 2022

We propose approximate gradient ascent algorithms for risk-sensitive reinforcement learning control problem in on-policy as well as off-policy settings. We consider episodic Markov decision processes, and model the risk using distortion risk measure (DRM) of the cumulative discounted reward. Our algorithms estimate the DRM using order statistics of the cumulative rewards, and calculate approximate gradients from the DRM estimates using a smoothed functional-based gradient estimation scheme. We derive non-asymptotic bounds that establish the convergence of our proposed algorithms to an approximate stationary point of the DRM objective.
Likelihood ratio-based policy gradient methods for distorted risk measures: A non-asymptotic analysis
Jul 14, 2021

We propose policy-gradient algorithms for solving the problem of control in a risk-sensitive reinforcement learning (RL) context. The objective of our algorithm is to maximize the distorted risk measure (DRM) of the cumulative reward in an episodic Markov decision process (MDP). We derive a variant of the policy gradient theorem that caters to the DRM objective. Using this theorem in conjunction with a likelihood ratio (LR) based gradient estimation scheme, we propose policy gradient algorithms for optimizing DRM in both on-policy and off-policy RL settings. We derive non-asymptotic bounds that establish the convergence of our algorithms to an approximate stationary point of the DRM objective.
Smoothed functional-based gradient algorithms for off-policy reinforcement learning
Jan 06, 2021

We consider the problem of control in an off-policy reinforcement learning (RL) context. We propose a policy gradient scheme that incorporates a smoothed functional-based gradient estimation scheme. We provide an asymptotic convergence guarantee for the proposed algorithm using the ordinary differential equation (ODE) approach. Further, we derive a non-asymptotic bound that quantifies the rate of convergence of the proposed algorithm.