 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing TryOnGAN
Jan 05, 2022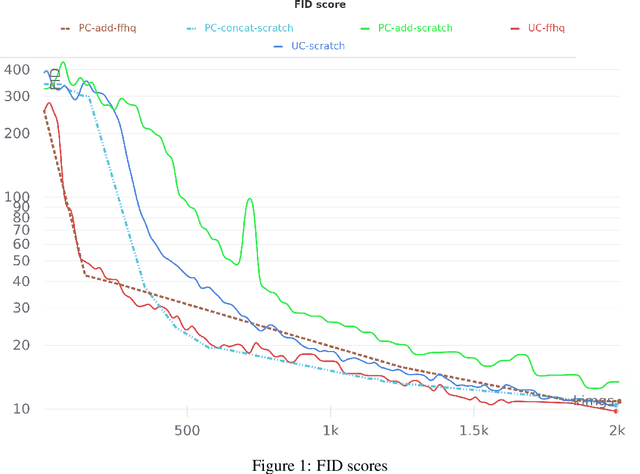

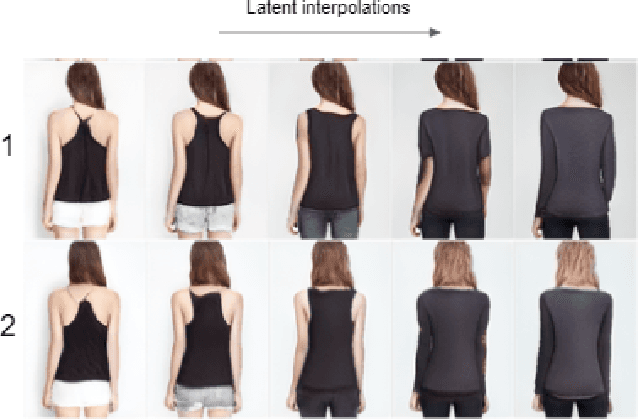

TryOnGAN is a recent virtual try-on approach, which generates highly realistic images and outperforms most previous approaches. In this article, we reproduce the TryOnGAN implementation and probe it along diverse angles: impact of transfer learning, variants of conditioning image generation with poses and properties of latent space interpolation. Some of these facets have never been explored in literature earlier. We find that transfer helps training initially but gains are lost as models train longer and pose conditioning via concatenation performs better. The latent space self-disentangles the pose and the style features and enables style transfer across poses. Our code and models are available in open source.
Learn to Bind and Grow Neural Structures
Nov 21, 2020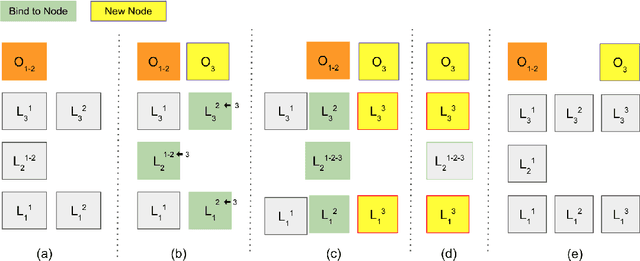

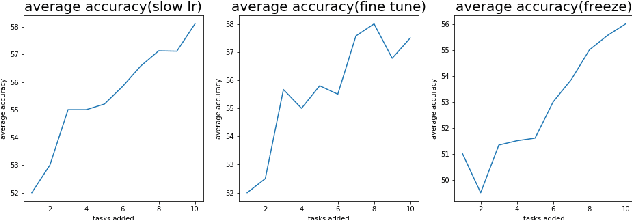

Task-incremental learning involves the challenging problem of learning new tasks continually, without forgetting past knowledge. Many approaches address the problem by expanding the structure of a shared neural network as tasks arrive, but struggle to grow optimally, without losing past knowledge. We present a new framework, Learn to Bind and Grow, which learns a neural architecture for a new task incrementally, either by binding with layers of a similar task or by expanding layers which are more likely to conflict between tasks. Central to our approach is a novel, interpretable, parameterization of the shared, multi-task architecture space, which then enables computing globally optimal architectures using Bayesian optimization. Experiments on continual learning benchmarks show that our framework performs comparably with earlier expansion based approaches and is able to flexibly compute multiple optimal solutions with performance-size trade-offs.
Gestop : Customizable Gesture Control of Computer Systems
Oct 25, 2020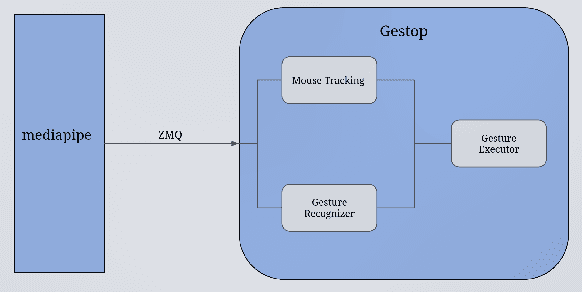

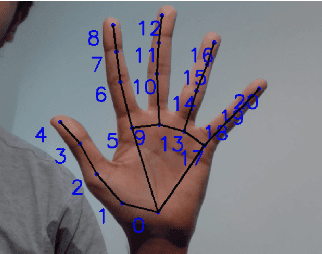
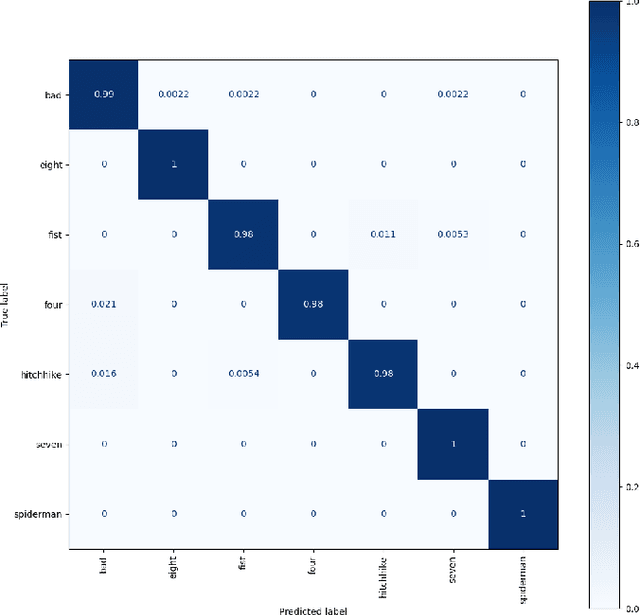
The established way of interfacing with most computer systems is a mouse and keyboard. Hand gestures are an intuitive and effective touchless way to interact with computer systems. However, hand gesture based systems have seen low adoption among end-users primarily due to numerous technical hurdles in detecting in-air gestures accurately. This paper presents Gestop, a framework developed to bridge this gap. The framework learns to detect gestures from demonstrations, is customizable by end-users and enables users to interact in real-time with computers having only RGB cameras, using gestures.