 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATE: How to Keep Out Intrusive Neighbors
Jun 01, 2024



Graph Attention Networks (GATs) are designed to provide flexible neighborhood aggregation that assigns weights to neighbors according to their importance. In practice, however, GATs are often unable to switch off task-irrelevant neighborhood aggregation, as we show experimentally and analytically. To address this challenge, we propose GATE, a GAT extension that holds three major advantages: i) It alleviates over-smoothing by addressing its root cause of unnecessary neighborhood aggregation. ii) Similarly to perceptrons, it benefits from higher depth as it can still utilize additional layers for (non-)linear feature transformations in case of (nearly) switched-off neighborhood aggregation. iii) By down-weighting connections to unrelated neighbors, it often outperforms GATs on real-world heterophilic datasets. To further validate our claims, we construct a synthetic test bed to analyze a model's ability to utilize the appropriate amount of neighborhood aggregation, which could be of independent interest.
Are GATs Out of Balance?
Oct 25, 2023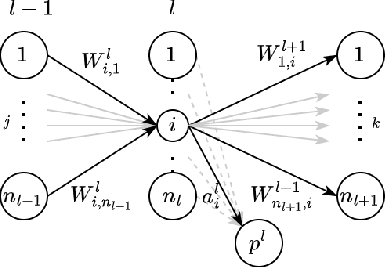

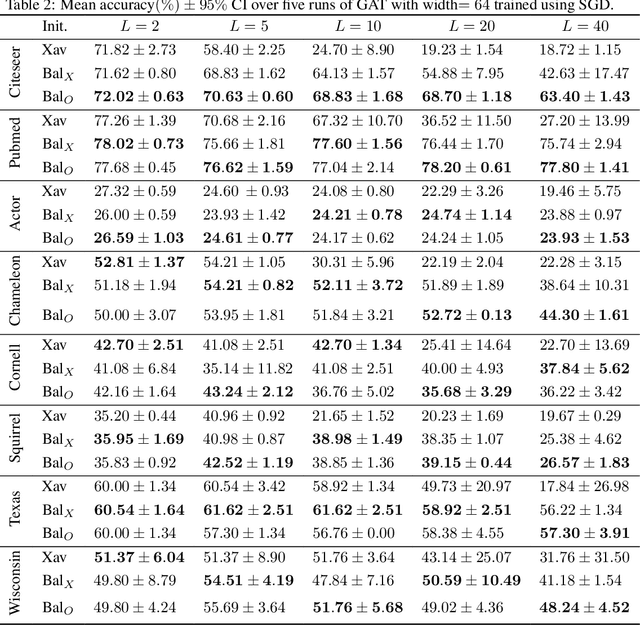
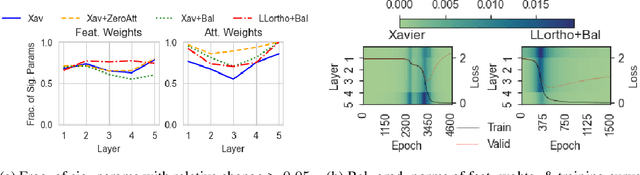
While the expressive power and computational capabilities of graph neural networks (GNNs) have been theoretically studied, their optimization and learning dynamics, in general, remain largely unexplored. Our study undertakes the Graph Attention Network (GAT), a popular GNN architecture in which a node's neighborhood aggregation is weighted by parameterized attention coefficients. We derive a conservation law of GAT gradient flow dynamics, which explains why a high portion of parameters in GATs with standard initialization struggle to change during training. This effect is amplified in deeper GATs, which perform significantly worse than their shallow counterparts. To alleviate this problem, we devise an initialization scheme that balances the GAT network. Our approach i) allows more effective propagation of gradients and in turn enables trainability of deeper networks, and ii) attains a considerable speedup in training and convergence time in comparison to the standard initialization. Our main theorem serves as a stepping stone to studying the learning dynamics of positive homogeneous models with attention mechanisms.
Search Based Code Generation for Machine Learning Programs
Feb 06, 2018

Machine Learning (ML) has revamped every domain of life as it provides powerful tools to build complex systems that learn and improve from experience and data. Our key insight is that to solve a machine learning problem, data scientists do not invent a new algorithm each time, but evaluate a range of existing models with different configurations and select the best one. This task is laborious, error-prone, and drains a large chunk of project budget and time. In this paper we present a novel framework inspired by programming by Sketching and Partial Evaluation to minimize human intervention in developing ML solutions. We templatize machine learning algorithms to expose configuration choices as holes to be searched. We share code and computation between different algorithms, and only partially evaluate configuration space of algorithms based on information gained from initial algorithm evaluations. We also employ hierarchical and heuristic based pruning to reduce the search space. Our initial findings indicate that our approach can generate highly accurate ML models. Interviews with data scientists show that they feel our framework can eliminate sources of common errors and significantly reduce development time.