 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuIM-RAG: Advancing Retrieval-Augmented Generation with Inverted Question Matching for Enhanced QA Performance
Jan 06, 2025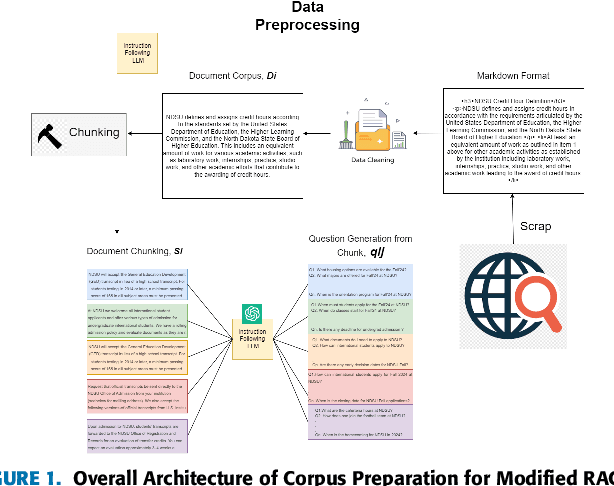
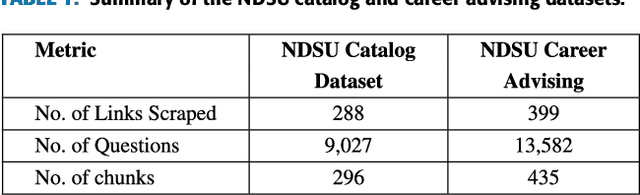
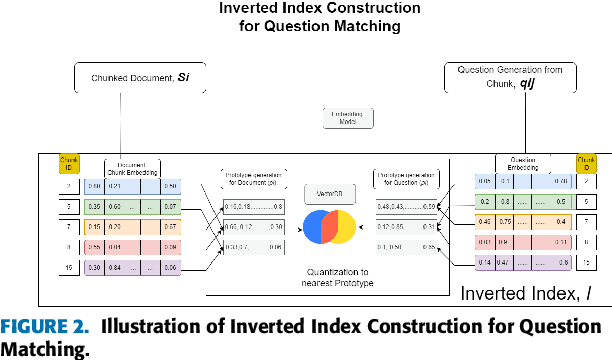
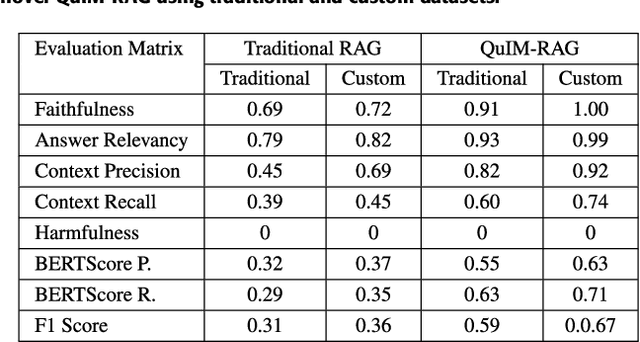
This work presents a novel architecture for building Retrieval-Augmented Generation (RAG) systems to improve Question Answering (QA) tasks from a target corpus. Large Language Models (LLMs) have revolutionized the analyzing and generation of human-like text. These models rely on pre-trained data and lack real-time updates unless integrated with live data tools. RAG enhances LLMs by integrating online resources and databases to generate contextually appropriate responses. However, traditional RAG still encounters challenges like information dilution and hallucinations when handling vast amounts of data. Our approach addresses these challenges by converting corpora into a domain-specific dataset and RAG architecture is constructed to generate responses from the target document. We introduce QuIM-RAG (Question-to-question Inverted Index Matching), a novel approach for the retrieval mechanism in our system. This strategy generates potential questions from document chunks and matches these with user queries to identify the most relevant text chunks for generating accurate answers. We have implemented our RAG system on top of the open-source Meta-LLaMA3-8B-instruct model by Meta Inc. that is available on Hugging Face. We constructed a custom corpus of 500+ pages from a high-traffic website accessed thousands of times daily for answering complex questions, along with manually prepared ground truth QA for evaluation. We compared our approach with traditional RAG models using BERT-Score and RAGAS, state-of-the-art metrics for evaluating LLM applications. Our evaluation demonstrates that our approach outperforms traditional RAG architectures on both metrics.
MaintainoMATE: A GitHub App for Intelligent Automation of Maintenance Activities
Aug 31, 2023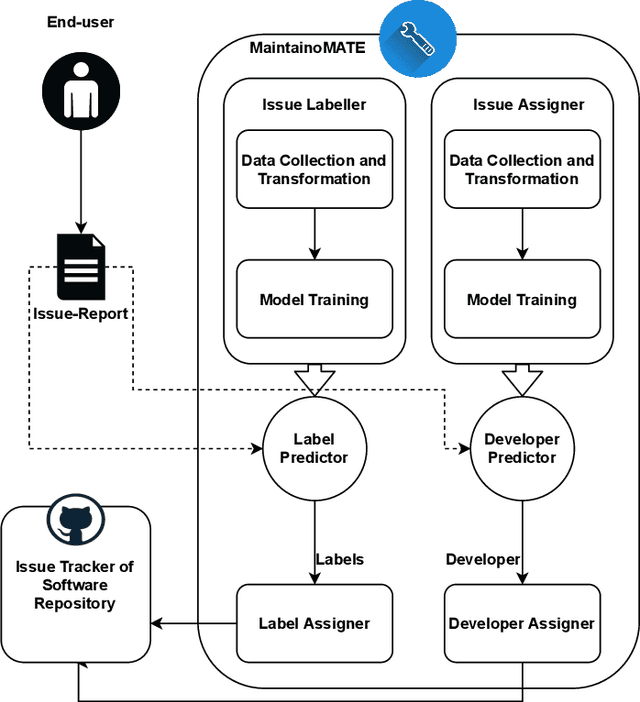
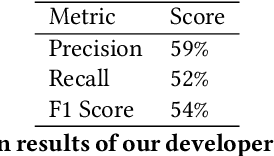
Software development projects rely on issue tracking systems at the core of tracking maintenance tasks such as bug reports, and enhancement requests. Incoming issue-reports on these issue tracking systems must be managed in an effective manner. First, they must be labelled and then assigned to a particular developer with relevant expertise. This handling of issue-reports is critical and requires thorough scanning of the text entered in an issue-report making it a labor-intensive task. In this paper, we present a unified framework called MaintainoMATE, which is capable of automatically categorizing the issue-reports in their respective category and further assigning the issue-reports to a developer with relevant expertise. We use the Bidirectional Encoder Representations from Transformers (BERT), as an underlying model for MaintainoMATE to learn the contextual information for automatic issue-report labeling and assignment tasks. We deploy the framework used in this work as a GitHub application. We empirically evaluate our approach on GitHub issue-reports to show its capability of assigning labels to the issue-reports. We were able to achieve an F1-score close to 80\%, which is comparable to existing state-of-the-art results. Similarly, our initial evaluations show that we can assign relevant developers to the issue-reports with an F1 score of 54\%, which is a significant improvement over existing approaches. Our initial findings suggest that MaintainoMATE has the potential of improving software quality and reducing maintenance costs by accurately automating activities involved in the maintenance processes. Our future work would be directed towards improving the issue-assignment module.
Fair Feature Subset Selection using Multiobjective Genetic Algorithm
Apr 30, 2022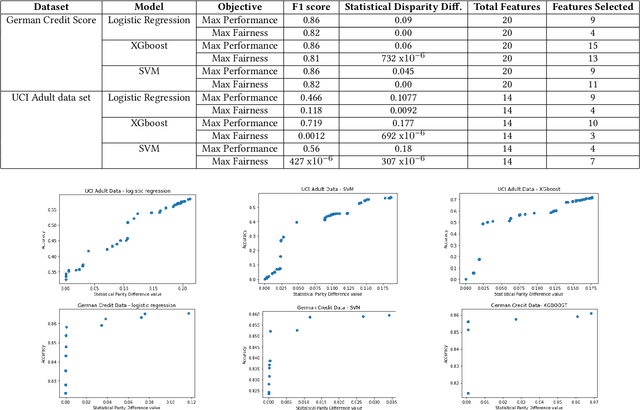
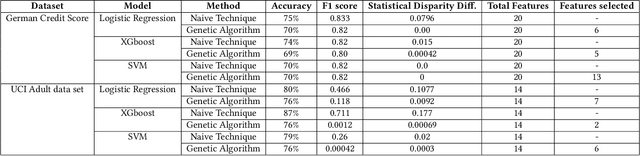
The feature subset selection problem aims at selecting the relevant subset of features to improve the performance of a Machine Learning (ML) algorithm on training data. Some features in data can be inherently noisy, costly to compute, improperly scaled, or correlated to other features, and they can adversely affect the accuracy, cost, and complexity of the induced algorithm. The goal of traditional feature selection approaches has been to remove such irrelevant features. In recent years ML is making a noticeable impact on the decision-making processes of our everyday lives. We want to ensure that these decisions do not reflect biased behavior towards certain groups or individuals based on protected attributes such as age, sex, or race. In this paper, we present a feature subset selection approach that improves both fairness and accuracy objectives and computes Pareto-optimal solutions using the NSGA-II algorithm. We use statistical disparity as a fairness metric and F1-Score as a metric for model performance. Our experiments on the most commonly used fairness benchmark datasets with three different machine learning algorithms show that using the evolutionary algorithm we can effectively explore the trade-off between fairness and accuracy.
Automatic Issue Classifier: A Transfer Learning Framework for Classifying Issue Reports
Feb 12, 2022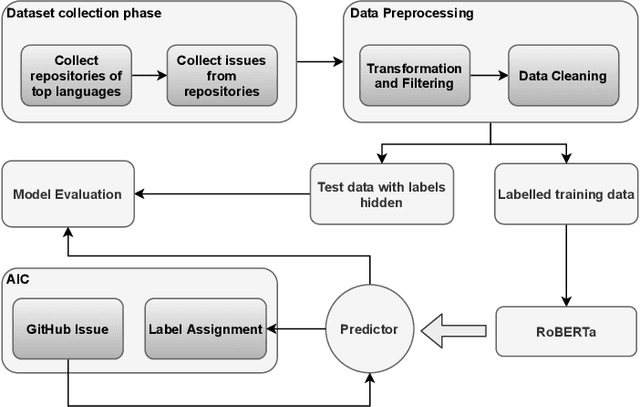

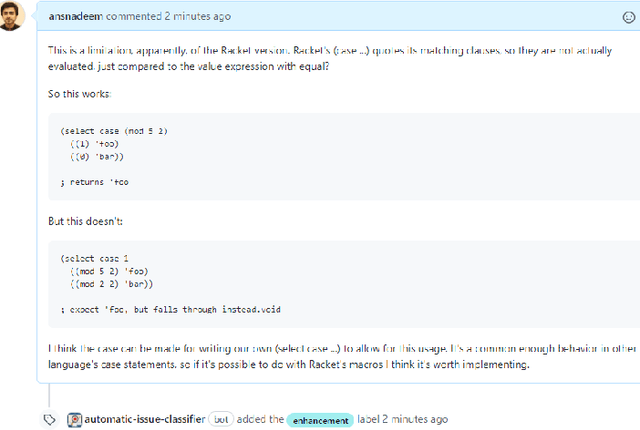

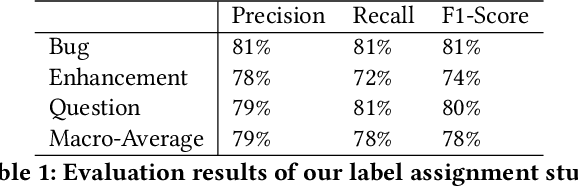
Issue tracking systems are used in the software industry for the facilitation of maintenance activities that keep the software robust and up to date with ever-changing industry requirements. Usually, users report issues that can be categorized into different labels such as bug reports, enhancement requests, and questions related to the software. Most of the issue tracking systems make the labelling of these issue reports optional for the issue submitter, which leads to a large number of unlabeled issue reports. In this paper, we present a state-of-the-art method to classify the issue reports into their respective categories i.e. bug, enhancement, and question. This is a challenging task because of the common use of informal language in the issue reports. Existing studies use traditional natural language processing approaches adopting key-word based features, which fail to incorporate the contextual relationship between words and therefore result in a high rate of false positives and false negatives. Moreover, previous works utilize a uni-label approach to classify the issue reports however, in reality, an issue-submitter can tag one issue report with more than one label at a time. This paper presents our approach to classify the issue reports in a multi-label setting. We use an off-the-shelf neural network called RoBERTa and fine-tune it to classify the issue reports. We validate our approach on issue reports belonging to numerous industrial projects from GitHub. We were able to achieve promising F-1 scores of 81%, 74%, and 80% for bug reports, enhancements, and questions, respectively. We also develop an industry tool called Automatic Issue Classifier (AIC), which automatically assigns labels to newly reported issues on GitHub repositories with high accuracy.
Search Based Code Generation for Machine Learning Programs
Feb 06, 2018

Machine Learning (ML) has revamped every domain of life as it provides powerful tools to build complex systems that learn and improve from experience and data. Our key insight is that to solve a machine learning problem, data scientists do not invent a new algorithm each time, but evaluate a range of existing models with different configurations and select the best one. This task is laborious, error-prone, and drains a large chunk of project budget and time. In this paper we present a novel framework inspired by programming by Sketching and Partial Evaluation to minimize human intervention in developing ML solutions. We templatize machine learning algorithms to expose configuration choices as holes to be searched. We share code and computation between different algorithms, and only partially evaluate configuration space of algorithms based on information gained from initial algorithm evaluations. We also employ hierarchical and heuristic based pruning to reduce the search space. Our initial findings indicate that our approach can generate highly accurate ML models. Interviews with data scientists show that they feel our framework can eliminate sources of common errors and significantly reduce development time.