 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Issue Classifier: A Transfer Learning Framework for Classifying Issue Reports
Paper and Code
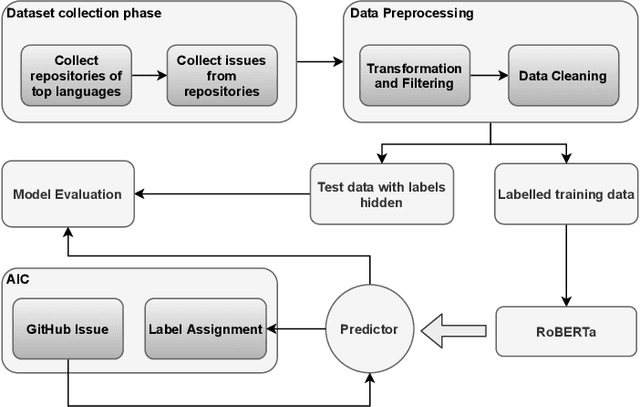

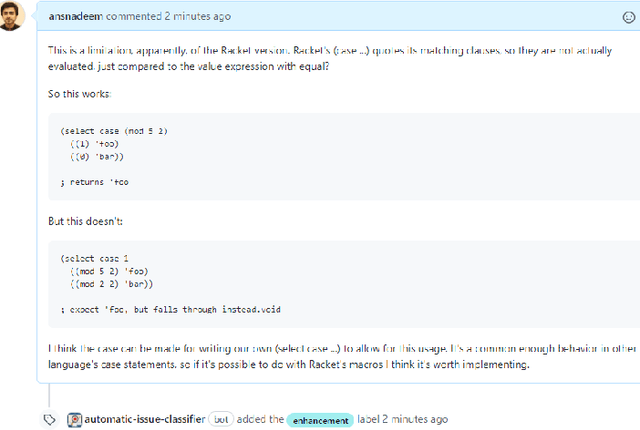

Issue tracking systems are used in the software industry for the facilitation of maintenance activities that keep the software robust and up to date with ever-changing industry requirements. Usually, users report issues that can be categorized into different labels such as bug reports, enhancement requests, and questions related to the software. Most of the issue tracking systems make the labelling of these issue reports optional for the issue submitter, which leads to a large number of unlabeled issue reports. In this paper, we present a state-of-the-art method to classify the issue reports into their respective categories i.e. bug, enhancement, and question. This is a challenging task because of the common use of informal language in the issue reports. Existing studies use traditional natural language processing approaches adopting key-word based features, which fail to incorporate the contextual relationship between words and therefore result in a high rate of false positives and false negatives. Moreover, previous works utilize a uni-label approach to classify the issue reports however, in reality, an issue-submitter can tag one issue report with more than one label at a time. This paper presents our approach to classify the issue reports in a multi-label setting. We use an off-the-shelf neural network called RoBERTa and fine-tune it to classify the issue reports. We validate our approach on issue reports belonging to numerous industrial projects from GitHub. We were able to achieve promising F-1 scores of 81%, 74%, and 80% for bug reports, enhancements, and questions, respectively. We also develop an industry tool called Automatic Issue Classifier (AIC), which automatically assigns labels to newly reported issues on GitHub repositories with high accuracy.