 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuIM-RAG: Advancing Retrieval-Augmented Generation with Inverted Question Matching for Enhanced QA Performance
Jan 06, 2025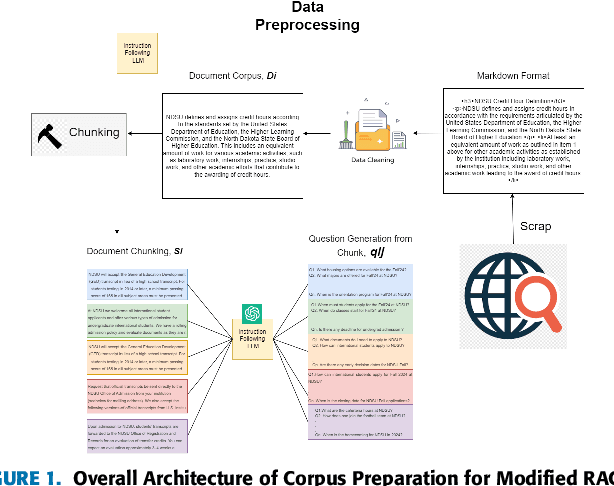
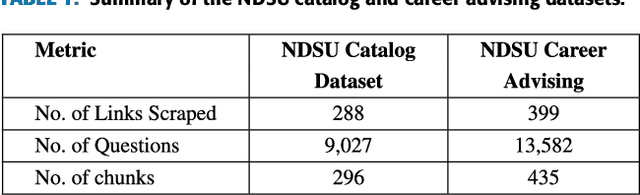
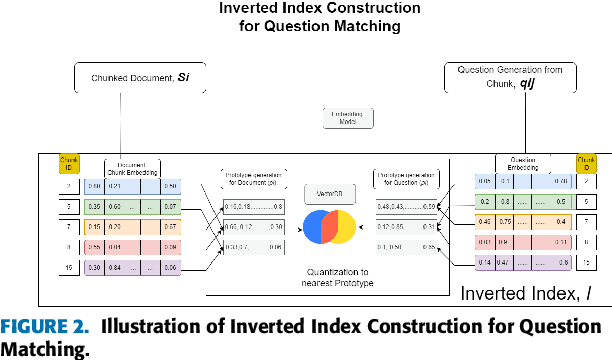
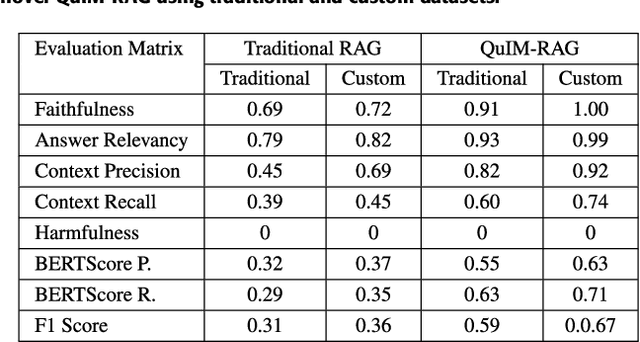
This work presents a novel architecture for building Retrieval-Augmented Generation (RAG) systems to improve Question Answering (QA) tasks from a target corpus. Large Language Models (LLMs) have revolutionized the analyzing and generation of human-like text. These models rely on pre-trained data and lack real-time updates unless integrated with live data tools. RAG enhances LLMs by integrating online resources and databases to generate contextually appropriate responses. However, traditional RAG still encounters challenges like information dilution and hallucinations when handling vast amounts of data. Our approach addresses these challenges by converting corpora into a domain-specific dataset and RAG architecture is constructed to generate responses from the target document. We introduce QuIM-RAG (Question-to-question Inverted Index Matching), a novel approach for the retrieval mechanism in our system. This strategy generates potential questions from document chunks and matches these with user queries to identify the most relevant text chunks for generating accurate answers. We have implemented our RAG system on top of the open-source Meta-LLaMA3-8B-instruct model by Meta Inc. that is available on Hugging Face. We constructed a custom corpus of 500+ pages from a high-traffic website accessed thousands of times daily for answering complex questions, along with manually prepared ground truth QA for evaluation. We compared our approach with traditional RAG models using BERT-Score and RAGAS, state-of-the-art metrics for evaluating LLM applications. Our evaluation demonstrates that our approach outperforms traditional RAG architectures on both metrics.
Can AI Help with Your Personal Finances?
Dec 27, 2024In recent years, Large Language Models (LLMs) have emerged as a transformative development in artificial intelligence (AI), drawing significant attention from industry and academia. Trained on vast datasets, these sophisticated AI systems exhibit impressive natural language processing and content generation capabilities. This paper explores the potential of LLMs to address key challenges in personal finance, focusing on the United States. We evaluate several leading LLMs, including OpenAI's ChatGPT, Google's Gemini, Anthropic's Claude, and Meta's Llama, to assess their effectiveness in providing accurate financial advice on topics such as mortgages, taxes, loans, and investments. Our findings show that while these models achieve an average accuracy rate of approximately 70%, they also display notable limitations in certain areas. Specifically, LLMs struggle to provide accurate responses for complex financial queries, with performance varying significantly across different topics. Despite these limitations, the analysis reveals notable improvements in newer versions of these models, highlighting their growing utility for individuals and financial advisors. As these AI systems continue to evolve, their potential for advancing AI-driven applications in personal finance becomes increasingly promising.