 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Methods for Minimizing Star-Convex Functions and Beyond
Jun 27, 2019
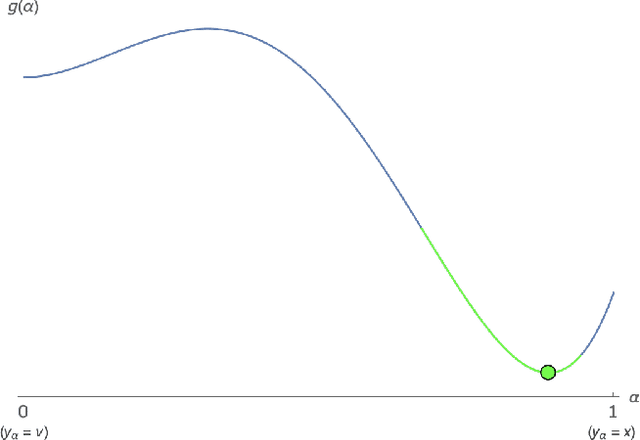
In this paper, we provide near-optimal accelerated first-order methods for minimizing a broad class of smooth nonconvex functions that are strictly unimodal on all lines through a minimizer. This function class, which we call the class of smooth quasar-convex functions, is parameterized by a constant $\gamma \in (0,1]$, where $\gamma = 1$ encompasses the classes of smooth convex and star-convex functions, and smaller values of $\gamma$ indicate that the function can be "more nonconvex." We develop a variant of accelerated gradient descent that computes an $\epsilon$-approximate minimizer of a smooth $\gamma$-quasar-convex function with at most $O(\gamma^{-1} \epsilon^{-1/2} \log(\gamma^{-1} \epsilon^{-1}))$ total function and gradient evaluations. We also derive a lower bound of $\Omega(\gamma^{-1} \epsilon^{-1/2})$ on the number of gradient evaluations required by any deterministic first-order method in the worst case, showing that, up to a logarithmic factor, no deterministic first-order algorithm can improve upon ours.
Low-Memory Neural Network Training: A Technical Report
Apr 24, 2019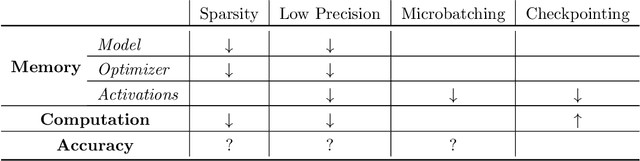
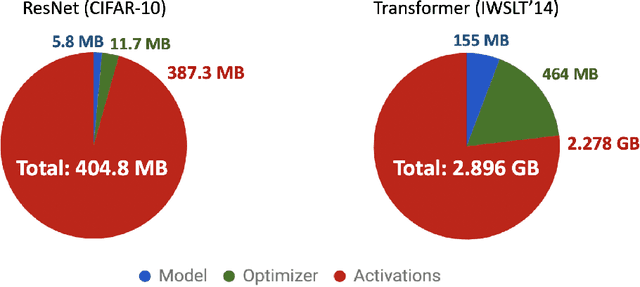
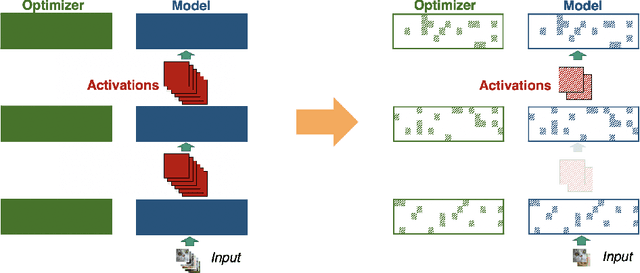

Memory is increasingly often the bottleneck when training neural network models. Despite this, techniques to lower the overall memory requirements of training have been less widely studied compared to the extensive literature on reducing the memory requirements of inference. In this paper we study a fundamental question: How much memory is actually needed to train a neural network? To answer this question, we profile the overall memory usage of training on two representative deep learning benchmarks -- the WideResNet model for image classification and the DynamicConv Transformer model for machine translation -- and comprehensively evaluate four standard techniques for reducing the training memory requirements: (1) imposing sparsity on the model, (2) using low precision, (3) microbatching, and (4) gradient checkpointing. We explore how each of these techniques in isolation affects both the peak memory usage of training and the quality of the end model, and explore the memory, accuracy, and computation tradeoffs incurred when combining these techniques. Using appropriate combinations of these techniques, we show that it is possible to the reduce the memory required to train a WideResNet-28-2 on CIFAR-10 by up to 60.7x with a 0.4% loss in accuracy, and reduce the memory required to train a DynamicConv model on IWSLT'14 German to English translation by up to 8.7x with a BLEU score drop of 0.15.