 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Detection in LLMs: Fast and Memory-Efficient Finetuned Models
Sep 04, 2024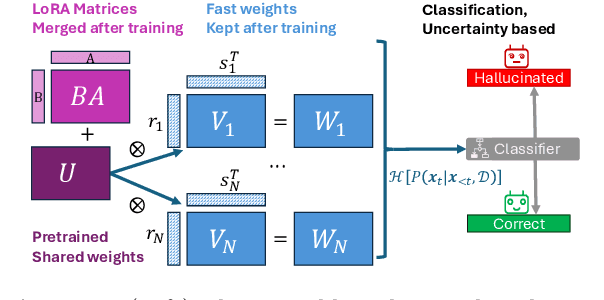

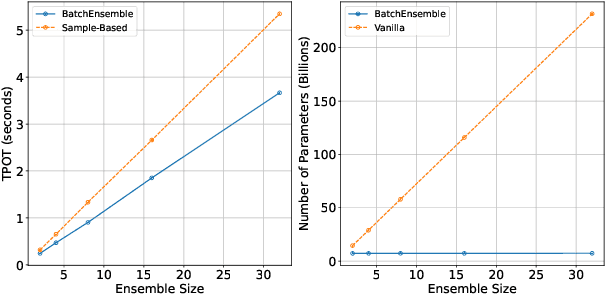
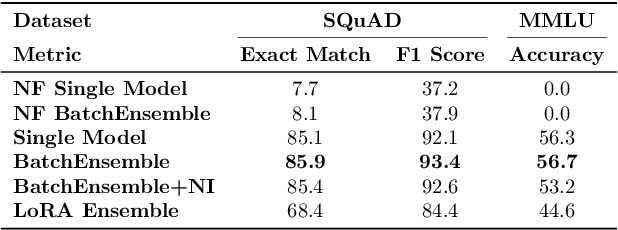
Uncertainty estimation is a necessary component when implementing AI in high-risk settings, such as autonomous cars, medicine, or insurances. Large Language Models (LLMs) have seen a surge in popularity in recent years, but they are subject to hallucinations, which may cause serious harm in high-risk settings. Despite their success, LLMs are expensive to train and run: they need a large amount of computations and memory, preventing the use of ensembling methods in practice. In this work, we present a novel method that allows for fast and memory-friendly training of LLM ensembles. We show that the resulting ensembles can detect hallucinations and are a viable approach in practice as only one GPU is needed for training and inference.
CoMIR: Contrastive Multimodal Image Representation for Registration
Jun 11, 2020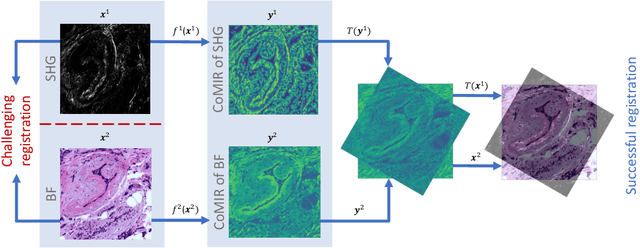

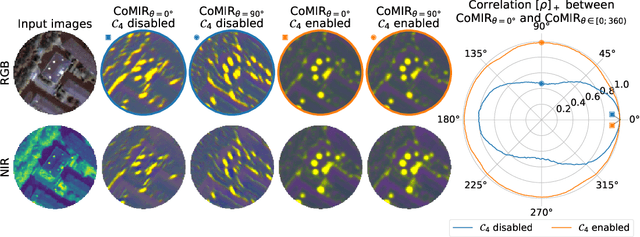
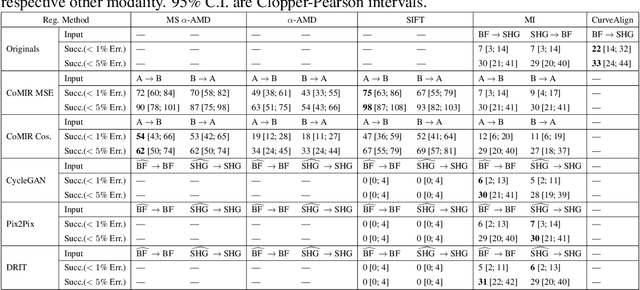
We propose contrastive coding to learn shared, dense image representations, referred to as CoMIRs (Contrastive Multimodal Image Representations). CoMIRs enable the registration of multimodal images where existing registration methods often fail due to a lack of sufficiently similar image structures. CoMIRs reduce the multimodal registration problem to a monomodal one in which general intensity-based, as well as feature-based, registration algorithms can be applied. The method involves training one neural network per modality on aligned images, using a contrastive loss based on noise-contrastive estimation (InfoNCE). Unlike other contrastive coding methods, used for e.g. classification, our approach generates image-like representations that contain the information shared between modalities. We introduce a novel, hyperparameter-free modification to InfoNCE, to enforce rotational equivariance of the learnt representations, a property essential to the registration task. We assess the extent of achieved rotational equivariance and the stability of the representations with respect to weight initialization, training set, and hyperparameter settings, on a remote sensing dataset of RGB and near-infrared images. We evaluate the learnt representations through registration of a biomedical dataset of bright-field and second-harmonic generation microscopy images; two modalities with very little apparent correlation. The proposed approach based on CoMIRs significantly outperforms registration of representations created by GAN-based image-to-image translation, as well as a state-of-the-art, application-specific method which takes additional knowledge about the data into account. Code is available at: https://github.com/dqiamsdoayehccdvulyy/CoMIR.
Introducing Hann windows for reducing edge-effects in patch-based image segmentation
Oct 17, 2019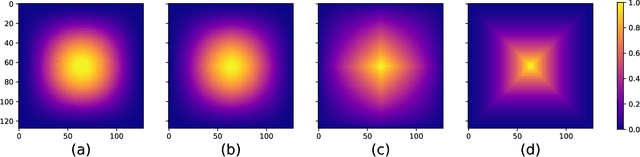

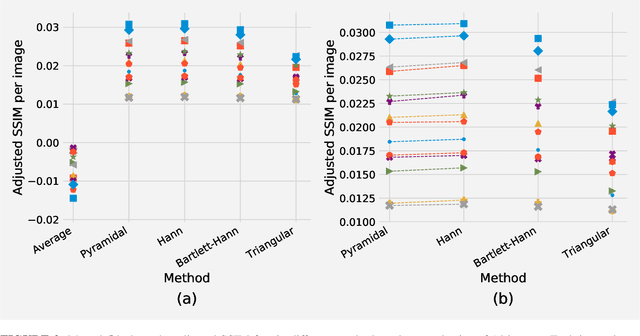
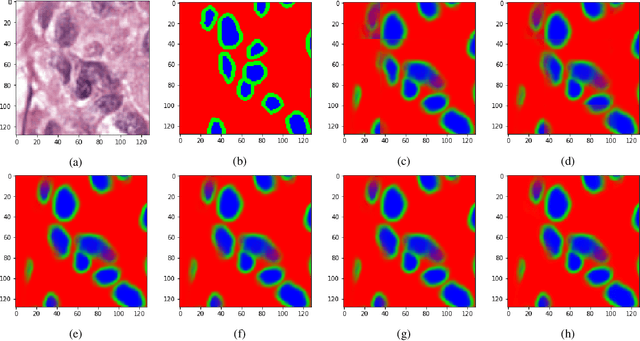
There is a limitation in the size of an image that can be processed using computationally demanding methods such as e.g. Convolutional Neural Networks (CNNs). Some imaging modalities - notably biological and medical - can result in images up to a few gigapixels in size, meaning that they have to be divided into smaller parts, or patches, for processing. However, when performing image segmentation, this may lead to undesirable artefacts, such as edge effects in the final re-combined image. We introduce windowing methods from signal processing to effectively reduce such edge effects. With the assumption that the central part of an image patch often holds richer contextual information than its sides and corners, we reconstruct the prediction by overlapping patches that are being weighted depending on 2-dimensional windows. We compare the results of four different windows: Hann, Bartlett-Hann, Triangular and a recently proposed window by Cui et al., and show that the cosine-based Hann window achieves the best improvement as measured by the Structural Similarity Index (SSIM). The proposed windowing method can be used together with any CNN model for segmentation without any modification and significantly improves network predictions.