 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized neural language models for real-world query auto completion
May 09, 2018


Query auto completion (QAC) systems are a standard part of search engines in industry, helping users formulate their query. Such systems update their suggestions after the user types each character, predicting the user's intent using various signals - one of the most common being popularity. Recently, deep learning approaches have been proposed for the QAC task, to specifically address the main limitation of previous popularity-based methods: the inability to predict unseen queries. In this work we improve previous methods based on neural language modeling, with the goal of building an end-to-end system. We particularly focus on using real-world data by integrating user information for personalized suggestions when possible. We also make use of time information and study how to increase diversity in the suggestions while studying the impact on scalability. Our empirical results demonstrate a marked improvement on two separate datasets over previous best methods in both accuracy and scalability, making a step towards neural query auto-completion in production search engines.
A Fast Deep Learning Model for Textual Relevance in Biomedical Information Retrieval
Feb 26, 2018


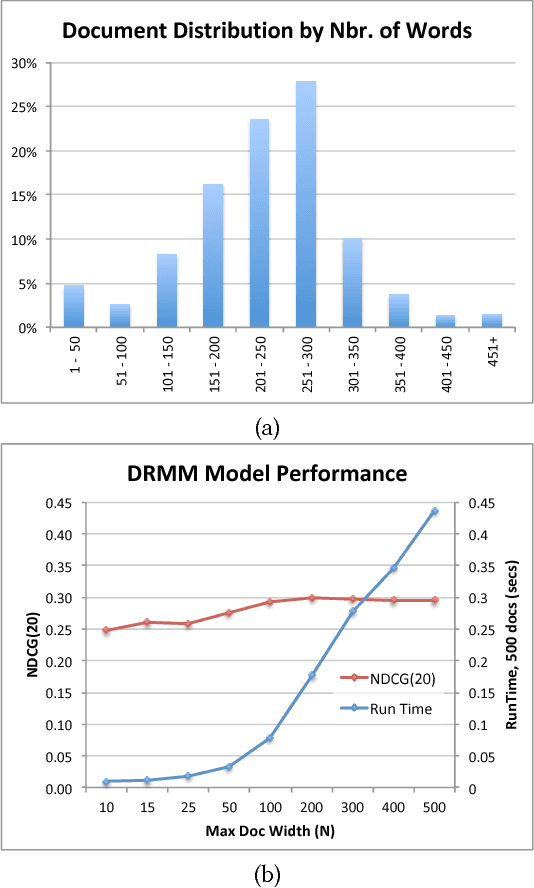
Publications in the life sciences are characterized by a large technical vocabulary, with many lexical and semantic variations for expressing the same concept. Towards addressing the problem of relevance in biomedical literature search, we introduce a deep learning model for the relevance of a document's text to a keyword style query. Limited by a relatively small amount of training data, the model uses pre-trained word embeddings. With these, the model first computes a variable-length Delta matrix between the query and document, representing a difference between the two texts, which is then passed through a deep convolution stage followed by a deep feed-forward network to compute a relevance score. This results in a fast model suitable for use in an online search engine. The model is robust and outperforms comparable state-of-the-art deep learning approaches.
Bridging the Gap: Incorporating a Semantic Similarity Measure for Effectively Mapping PubMed Queries to Documents
Oct 17, 2017
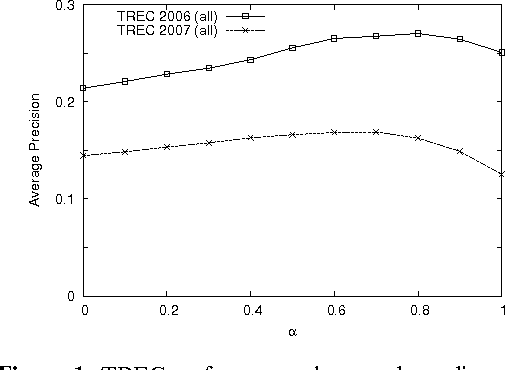


The main approach of traditional information retrieval (IR) is to examine how many words from a query appear in a document. A drawback of this approach, however, is that it may fail to detect relevant documents where no or only few words from a query are found. The semantic analysis methods such as LSA (latent semantic analysis) and LDA (latent Dirichlet allocation) have been proposed to address the issue, but their performance is not superior compared to common IR approaches. Here we present a query-document similarity measure motivated by the Word Mover's Distance. Unlike other similarity measures, the proposed method relies on neural word embeddings to compute the distance between words. This process helps identify related words when no direct matches are found between a query and a document. Our method is efficient and straightforward to implement. The experimental results on TREC Genomics data show that our approach outperforms the BM25 ranking function by an average of 12% in mean average precision. Furthermore, for a real-world dataset collected from the PubMed search logs, we combine the semantic measure with BM25 using a learning to rank method, which leads to improved ranking scores by up to 25%. This experiment demonstrates that the proposed approach and BM25 nicely complement each other and together produce superior performance.