 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPU-Net: Multi Scale Identity-Preserved U-Net for Low Resolution Face Recognition
Oct 23, 2020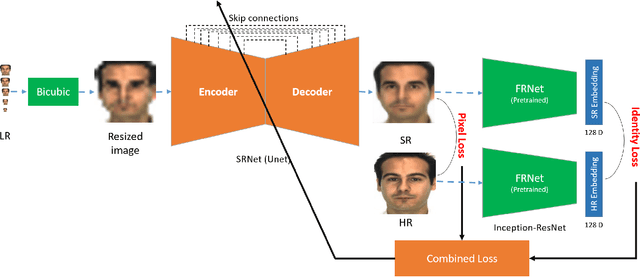


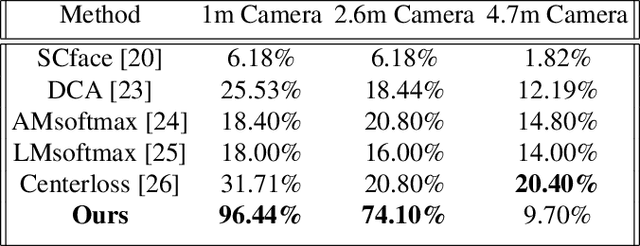
State-of-the-art deep neural network models have reached near perfect face recognition accuracy rates on controlled high resolution face images. However, their performance is drastically degraded when they are tested with very low resolution face images. This is particularly critical in surveillance systems, where a low resolution probe image is to be matched with high resolution gallery images. Super resolution techniques aim at producing high resolution face images from low resolution counterparts. While they are capable of reconstructing images that are visually appealing, the identity-related information is not preserved. Here, we propose an identity-preserved U-Net which is capable of super-resolving very low resolution faces to their high resolution counterparts while preserving identity-related information. We achieve this by training a U-Net with a combination of a reconstruction and an identity-preserving loss, on multi-scale low resolution conditions. Extensive quantitative evaluations of our proposed model demonstrated that it outperforms competing super resolution and low resolution face recognition methods on natural and artificial low resolution face data sets and even unseen identities.
Latent Vector Recovery of Audio GANs
Oct 16, 2020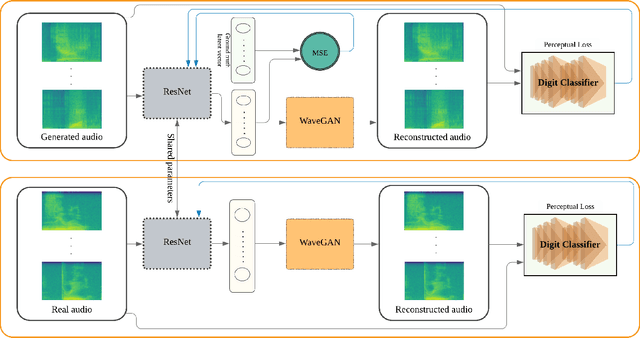
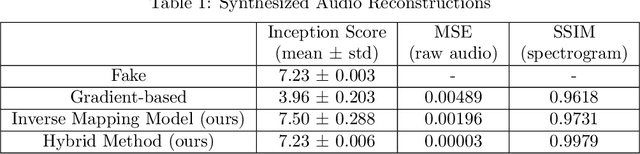
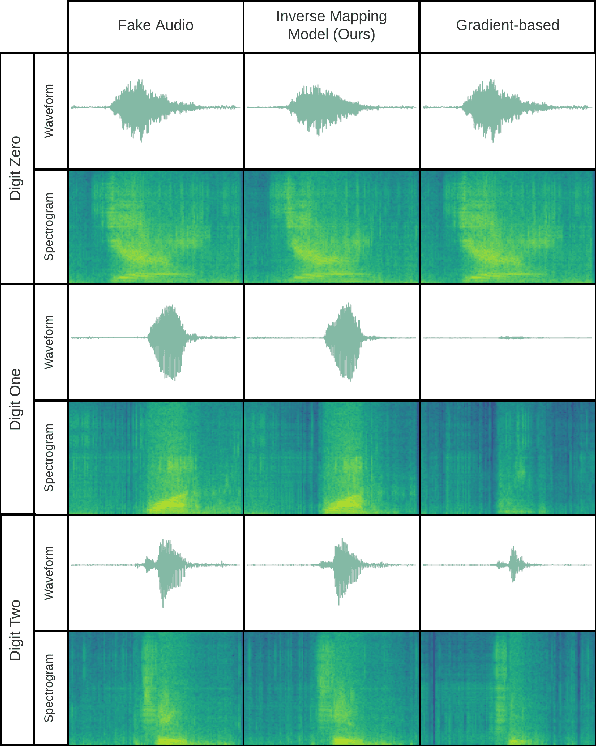
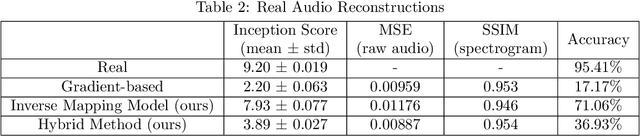
Advanced Generative Adversarial Networks (GANs) are remarkable in generating intelligible audio from a random latent vector. In this paper, we examine the task of recovering the latent vector of both synthesized and real audio. Previous works recovered latent vectors of given audio through an auto-encoder inspired technique that trains an encoder network either in parallel with the GAN or after the generator is trained. With our approach, we train a deep residual neural network architecture to project audio synthesized by WaveGAN into the corresponding latent space with near identical reconstruction performance. To accommodate for the lack of an original latent vector for real audio, we optimize the residual network on the perceptual loss between the real audio samples and the reconstructed audio of the predicted latent vectors. In the case of synthesized audio, the Mean Squared Error (MSE) between the ground truth and recovered latent vector is minimized as well. We further investigated the audio reconstruction performance when several gradient optimization steps are applied to the predicted latent vector. Through our deep neural network based method of training on real and synthesized audio, we are able to predict a latent vector that corresponds to a reasonable reconstruction of real audio. Even though we evaluated our method on WaveGAN, our proposed method is universal and can be applied to any other GANs.
Inverse mapping of face GANs
Sep 11, 2020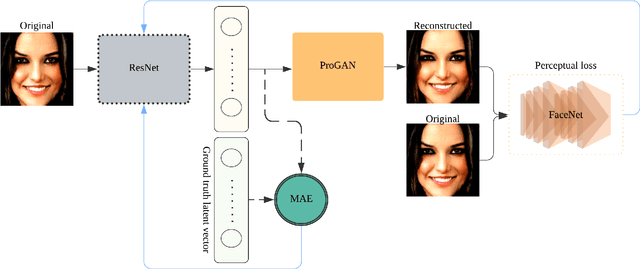
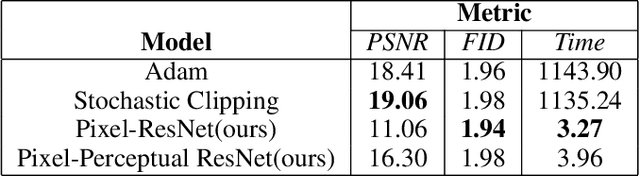
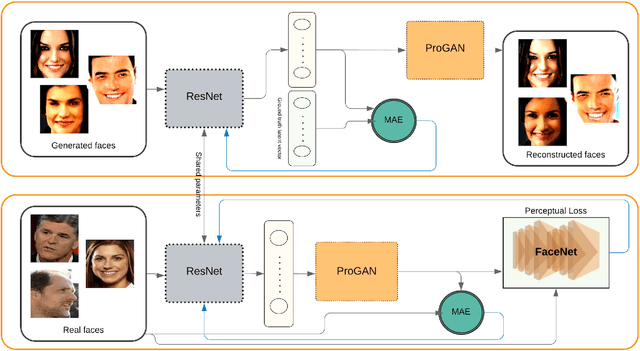
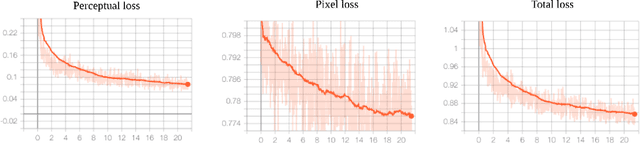
Generative adversarial networks (GANs) synthesize realistic images from a random latent vector. While many studies have explored various training configurations and architectures for GANs, the problem of inverting a generative model to extract latent vectors of given input images has been inadequately investigated. Although there is exactly one generated image per given random vector, the mapping from an image to its recovered latent vector can have more than one solution. We train a ResNet architecture to recover a latent vector for a given face that can be used to generate a face nearly identical to the target. We use a perceptual loss to embed face details in the recovered latent vector while maintaining visual quality using a pixel loss. The vast majority of studies on latent vector recovery perform well only on generated images, we argue that our method can be used to determine a mapping between real human faces and latent-space vectors that contain most of the important face style details. In addition, our proposed method projects generated faces to their latent-space with high fidelity and speed. At last, we demonstrate the performance of our approach on both real and generated faces.