 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Vector Recovery of Audio GANs
Paper and Code
Oct 16, 2020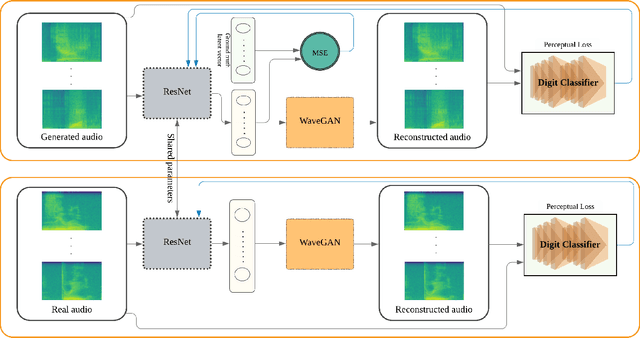
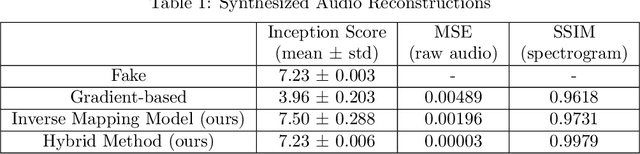
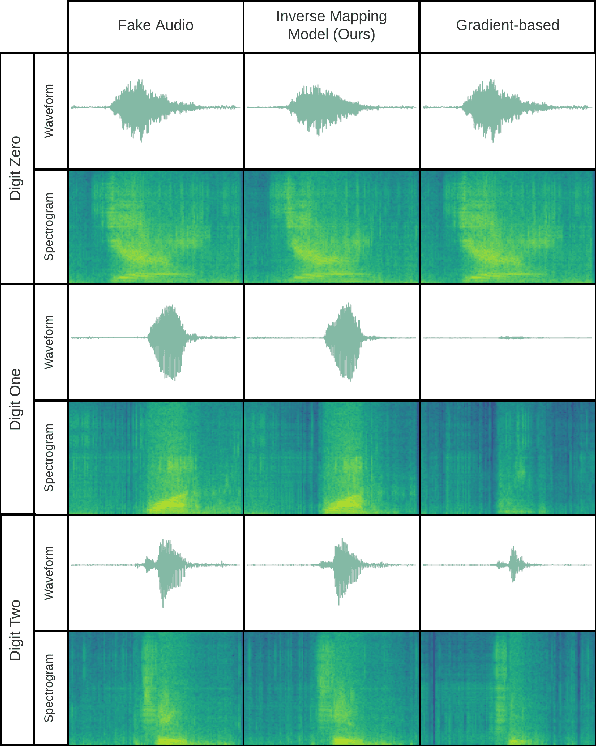
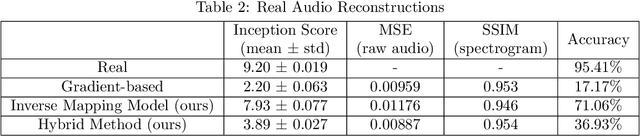
Advanced Generative Adversarial Networks (GANs) are remarkable in generating intelligible audio from a random latent vector. In this paper, we examine the task of recovering the latent vector of both synthesized and real audio. Previous works recovered latent vectors of given audio through an auto-encoder inspired technique that trains an encoder network either in parallel with the GAN or after the generator is trained. With our approach, we train a deep residual neural network architecture to project audio synthesized by WaveGAN into the corresponding latent space with near identical reconstruction performance. To accommodate for the lack of an original latent vector for real audio, we optimize the residual network on the perceptual loss between the real audio samples and the reconstructed audio of the predicted latent vectors. In the case of synthesized audio, the Mean Squared Error (MSE) between the ground truth and recovered latent vector is minimized as well. We further investigated the audio reconstruction performance when several gradient optimization steps are applied to the predicted latent vector. Through our deep neural network based method of training on real and synthesized audio, we are able to predict a latent vector that corresponds to a reasonable reconstruction of real audio. Even though we evaluated our method on WaveGAN, our proposed method is universal and can be applied to any other GANs.