 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse mapping of face GANs
Paper and Code
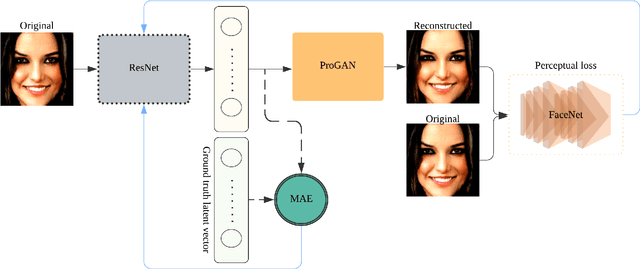
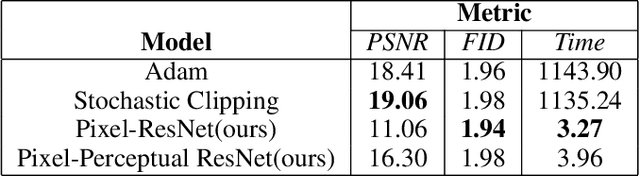
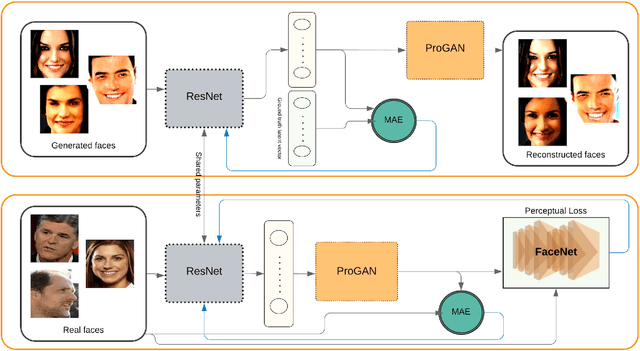
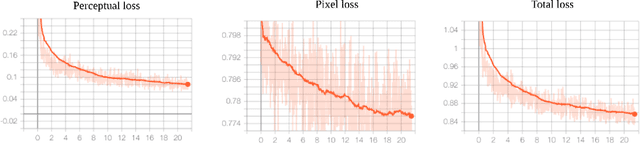
Generative adversarial networks (GANs) synthesize realistic images from a random latent vector. While many studies have explored various training configurations and architectures for GANs, the problem of inverting a generative model to extract latent vectors of given input images has been inadequately investigated. Although there is exactly one generated image per given random vector, the mapping from an image to its recovered latent vector can have more than one solution. We train a ResNet architecture to recover a latent vector for a given face that can be used to generate a face nearly identical to the target. We use a perceptual loss to embed face details in the recovered latent vector while maintaining visual quality using a pixel loss. The vast majority of studies on latent vector recovery perform well only on generated images, we argue that our method can be used to determine a mapping between real human faces and latent-space vectors that contain most of the important face style details. In addition, our proposed method projects generated faces to their latent-space with high fidelity and speed. At last, we demonstrate the performance of our approach on both real and generated faces.