 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDAMA: Unsupervised Domain Adaptation through Multi-discriminator Adversarial Training with Noisy Labels Improves Cardio-fitness Prediction
Jul 31, 2023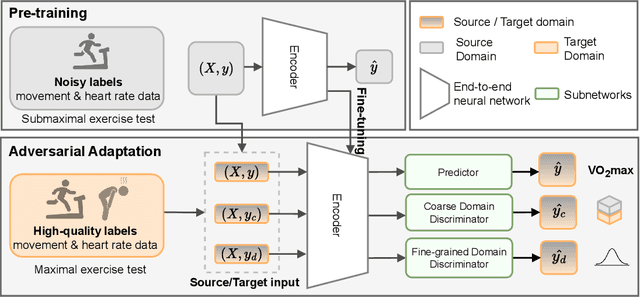
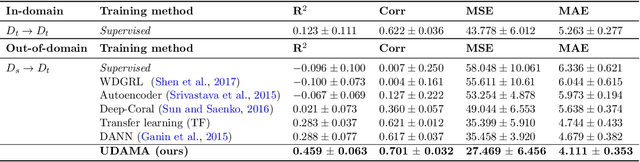
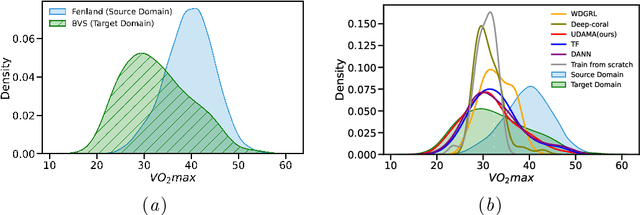

Deep learning models have shown great promise in various healthcare monitoring applications. However, most healthcare datasets with high-quality (gold-standard) labels are small-scale, as directly collecting ground truth is often costly and time-consuming. As a result, models developed and validated on small-scale datasets often suffer from overfitting and do not generalize well to unseen scenarios. At the same time, large amounts of imprecise (silver-standard) labeled data, annotated by approximate methods with the help of modern wearables and in the absence of ground truth validation, are starting to emerge. However, due to measurement differences, this data displays significant label distribution shifts, which motivates the use of domain adaptation. To this end, we introduce UDAMA, a method with two key components: Unsupervised Domain Adaptation and Multidiscriminator Adversarial Training, where we pre-train on the silver-standard data and employ adversarial adaptation with the gold-standard data along with two domain discriminators. In particular, we showcase the practical potential of UDAMA by applying it to Cardio-respiratory fitness (CRF) prediction. CRF is a crucial determinant of metabolic disease and mortality, and it presents labels with various levels of noise (goldand silver-standard), making it challenging to establish an accurate prediction model. Our results show promising performance by alleviating distribution shifts in various label shift settings. Additionally, by using data from two free-living cohort studies (Fenland and BBVS), we show that UDAMA consistently outperforms up to 12% compared to competitive transfer learning and state-of-the-art domain adaptation models, paving the way for leveraging noisy labeled data to improve fitness estimation at scale.
Turning Silver into Gold: Domain Adaptation with Noisy Labels for Wearable Cardio-Respiratory Fitness Prediction
Nov 20, 2022Deep learning models have shown great promise in various healthcare applications. However, most models are developed and validated on small-scale datasets, as collecting high-quality (gold-standard) labels for health applications is often costly and time-consuming. As a result, these models may suffer from overfitting and not generalize well to unseen data. At the same time, an extensive amount of data with imprecise labels (silver-standard) is starting to be generally available, as collected from inexpensive wearables like accelerometers and electrocardiography sensors. These currently underutilized datasets and labels can be leveraged to produce more accurate clinical models. In this work, we propose UDAMA, a novel model with two key components: Unsupervised Domain Adaptation and Multi-discriminator Adversarial training, which leverage noisy data from source domain (the silver-standard dataset) to improve gold-standard modeling. We validate our framework on the challenging task of predicting lab-measured maximal oxygen consumption (VO$_{2}$max), the benchmark metric of cardio-respiratory fitness, using free-living wearable sensor data from two cohort studies as inputs. Our experiments show that the proposed framework achieves the best performance of corr = 0.665 $\pm$ 0.04, paving the way for accurate fitness estimation at scale.
Longitudinal cardio-respiratory fitness prediction through free-living wearable sensors
May 06, 2022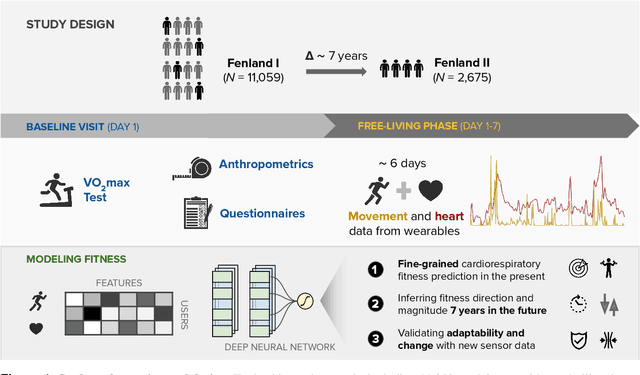
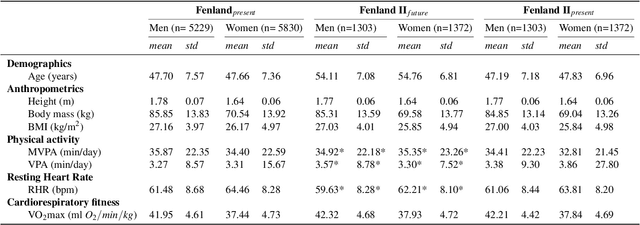
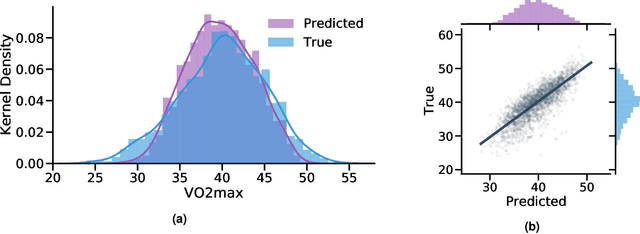
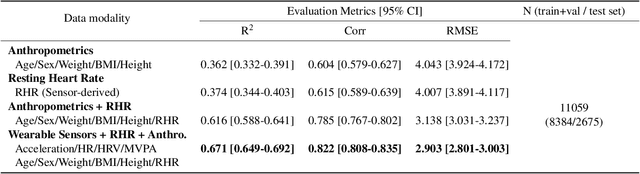
Cardiorespiratory fitness is an established predictor of metabolic disease and mortality. Fitness is directly measured as maximal oxygen consumption (VO2max), or indirectly assessed using heart rate response to a standard exercise test. However, such testing is costly and burdensome, limiting its utility and scalability. Fitness can also be approximated using resting heart rate and self-reported exercise habits but with lower accuracy. Modern wearables capture dynamic heart rate data which, in combination with machine learning models, could improve fitness prediction. In this work, we analyze movement and heart rate signals from wearable sensors in free-living conditions from 11,059 participants who also underwent a standard exercise test, along with a longitudinal repeat cohort of 2,675 participants. We design algorithms and models that convert raw sensor data into cardio-respiratory fitness estimates, and validate these estimates' ability to capture fitness profiles in a longitudinal cohort over time while subjects engaged in real-world (non-exercise) behaviour. Additionally, we validate our methods with a third external cohort of 181 participants who underwent maximal VO2max testing, which is considered the gold standard measurement because it requires reaching one's maximum heart rate and exhaustion level. Our results show that the developed models yield a high correlation (r = 0.82, 95CI 0.80-0.83), when compared to the ground truth in a holdout sample. These models outperform conventional non-exercise fitness models and traditional bio-markers using measurements of normal daily living without the need for a specific exercise test. Additionally, we show the adaptability and applicability of this approach for detecting fitness change over time in the longitudinal subsample that repeated measurements after 7 years.