 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphEval: A Knowledge-Graph Based LLM Hallucination Evaluation Framework
Jul 15, 2024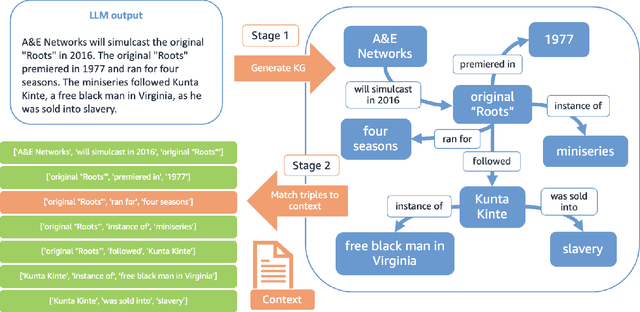

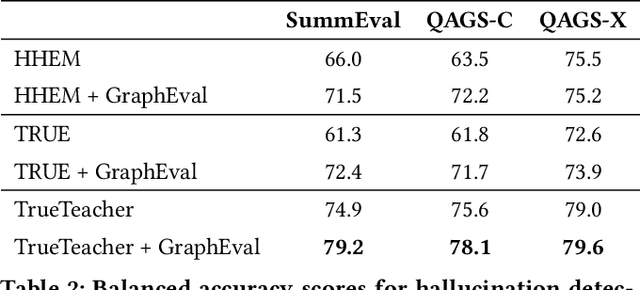
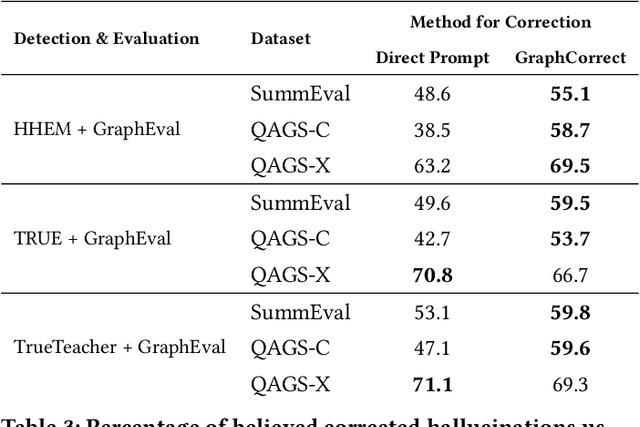
Methods to evaluate Large Language Model (LLM) responses and detect inconsistencies, also known as hallucinations, with respect to the provided knowledge, are becoming increasingly important for LLM applications. Current metrics fall short in their ability to provide explainable decisions, systematically check all pieces of information in the response, and are often too computationally expensive to be used in practice. We present GraphEval: a hallucination evaluation framework based on representing information in Knowledge Graph (KG) structures. Our method identifies the specific triples in the KG that are prone to hallucinations and hence provides more insight into where in the response a hallucination has occurred, if at all, than previous methods. Furthermore, using our approach in conjunction with state-of-the-art natural language inference (NLI) models leads to an improvement in balanced accuracy on various hallucination benchmarks, compared to using the raw NLI models. Lastly, we explore the use of GraphEval for hallucination correction by leveraging the structure of the KG, a method we name GraphCorrect, and demonstrate that the majority of hallucinations can indeed be rectified.
SRMD: Sparse Random Mode Decomposition
Apr 12, 2022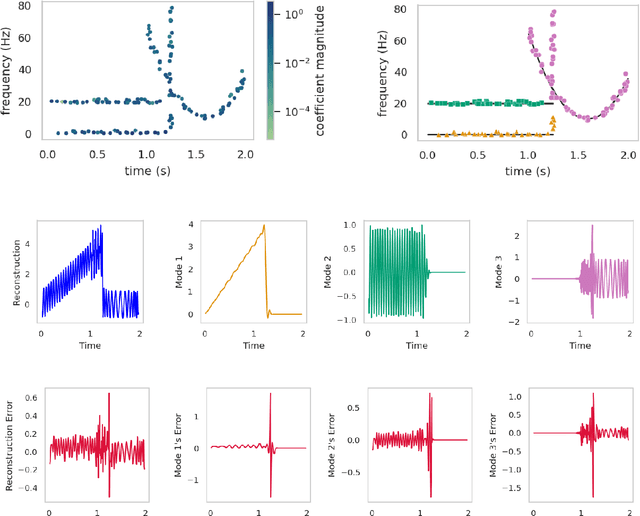


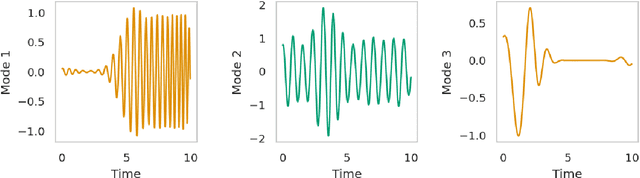
Signal decomposition and multiscale signal analysis provide many useful tools for time-frequency analysis. We proposed a random feature method for analyzing time-series data by constructing a sparse approximation to the spectrogram. The randomization is both in the time window locations and the frequency sampling, which lowers the overall sampling and computational cost. The sparsification of the spectrogram leads to a sharp separation between time-frequency clusters which makes it easier to identify intrinsic modes, and thus leads to a new data-driven mode decomposition. The applications include signal representation, outlier removal, and mode decomposition. On the benchmark tests, we show that our approach outperforms other state-of-the-art decomposition methods.