 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.
Transfer Learning with Kernel Methods
Nov 01, 2022Transfer learning refers to the process of adapting a model trained on a source task to a target task. While kernel methods are conceptually and computationally simple machine learning models that are competitive on a variety of tasks, it has been unclear how to perform transfer learning for kernel methods. In this work, we propose a transfer learning framework for kernel methods by projecting and translating the source model to the target task. We demonstrate the effectiveness of our framework in applications to image classification and virtual drug screening. In particular, we show that transferring modern kernels trained on large-scale image datasets can result in substantial performance increase as compared to using the same kernel trained directly on the target task. In addition, we show that transfer-learned kernels allow a more accurate prediction of the effect of drugs on cancer cell lines. For both applications, we identify simple scaling laws that characterize the performance of transfer-learned kernels as a function of the number of target examples. We explain this phenomenon in a simplified linear setting, where we are able to derive the exact scaling laws. By providing a simple and effective transfer learning framework for kernel methods, our work enables kernel methods trained on large datasets to be easily adapted to a variety of downstream target tasks.
Optimal Transport using GANs for Lineage Tracing
Jul 27, 2020
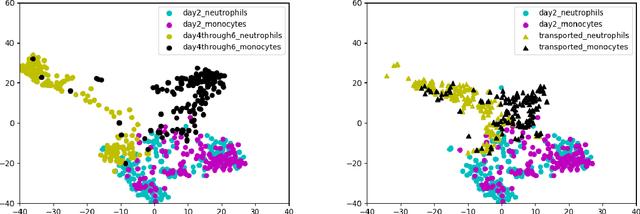


In this paper, we present Super-OT, a novel approach to computational lineage tracing that combines a supervised learning framework with optimal transport based on Generative Adversarial Networks (GANs). Unlike previous approaches to lineage tracing, Super-OT has the flexibility to integrate paired data. We benchmark Super-OT based on single-cell RNA-seq data against Waddington-OT, a popular approach for lineage tracing that also employs optimal transport. We show that Super-OT achieves gains over Waddington-OT in predicting the class outcome of cells during differentiation, since it allows the integration of additional information during \mbox{training.}