 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Biases for Zero-shot Systematic Generalization in Language-informed Reinforcement Learning
Jan 25, 2025



Sample efficiency and systematic generalization are two long-standing challenges in reinforcement learning. Previous studies have shown that involving natural language along with other observation modalities can improve generalization and sample efficiency due to its compositional and open-ended nature. However, to transfer these properties of language to the decision-making process, it is necessary to establish a proper language grounding mechanism. One approach to this problem is applying inductive biases to extract fine-grained and informative representations from the observations, which makes them more connectable to the language units. We provide architecture-level inductive biases for modularity and sparsity mainly based on Neural Production Systems (NPS). Alongside NPS, we assign a central role to memory in our architecture. It can be seen as a high-level information aggregator which feeds policy/value heads with comprehensive information and simultaneously guides selective attention in NPS through attentional feedback. Our results in the BabyAI environment suggest that the proposed model's systematic generalization and sample efficiency are improved significantly compared to previous models. An extensive ablation study on variants of the proposed method is conducted, and the effectiveness of each employed technique on generalization, sample efficiency, and training stability is specified.
CAREL: Instruction-guided reinforcement learning with cross-modal auxiliary objectives
Nov 29, 2024


Grounding the instruction in the environment is a key step in solving language-guided goal-reaching reinforcement learning problems. In automated reinforcement learning, a key concern is to enhance the model's ability to generalize across various tasks and environments. In goal-reaching scenarios, the agent must comprehend the different parts of the instructions within the environmental context in order to complete the overall task successfully. In this work, we propose CAREL (Cross-modal Auxiliary REinforcement Learning) as a new framework to solve this problem using auxiliary loss functions inspired by video-text retrieval literature and a novel method called instruction tracking, which automatically keeps track of progress in an environment. The results of our experiments suggest superior sample efficiency and systematic generalization for this framework in multi-modal reinforcement learning problems. Our code base is available here.
PreND: Enhancing Intrinsic Motivation in Reinforcement Learning through Pre-trained Network Distillation
Oct 02, 2024



Intrinsic motivation, inspired by the psychology of developmental learning in infants, stimulates exploration in agents without relying solely on sparse external rewards. Existing methods in reinforcement learning like Random Network Distillation (RND) face significant limitations, including (1) relying on raw visual inputs, leading to a lack of meaningful representations, (2) the inability to build a robust latent space, (3) poor target network initialization and (4) rapid degradation of intrinsic rewards. In this paper, we introduce Pre-trained Network Distillation (PreND), a novel approach to enhance intrinsic motivation in reinforcement learning (RL) by improving upon the widely used prediction-based method, RND. PreND addresses these challenges by incorporating pre-trained representation models into both the target and predictor networks, resulting in more meaningful and stable intrinsic rewards, while enhancing the representation learned by the model. We also tried simple but effective variants of the predictor network optimization by controlling the learning rate. Through experiments on the Atari domain, we demonstrate that PreND significantly outperforms RND, offering a more robust intrinsic motivation signal that leads to better exploration, improving overall performance and sample efficiency. This research highlights the importance of target and predictor networks representation in prediction-based intrinsic motivation, setting a new direction for improving RL agents' learning efficiency in sparse reward environments.
SCGG: A Deep Structure-Conditioned Graph Generative Model
Sep 20, 2022
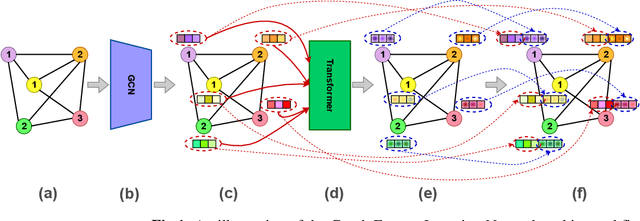
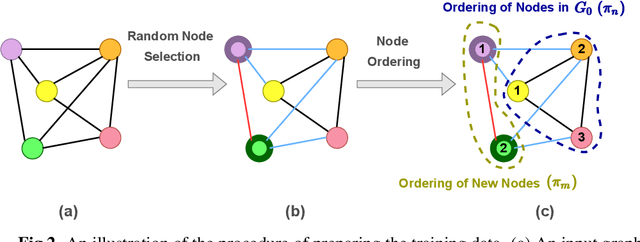

Deep learning-based graph generation approaches have remarkable capacities for graph data modeling, allowing them to solve a wide range of real-world problems. Making these methods able to consider different conditions during the generation procedure even increases their effectiveness by empowering them to generate new graph samples that meet the desired criteria. This paper presents a conditional deep graph generation method called SCGG that considers a particular type of structural conditions. Specifically, our proposed SCGG model takes an initial subgraph and autoregressively generates new nodes and their corresponding edges on top of the given conditioning substructure. The architecture of SCGG consists of a graph representation learning network and an autoregressive generative model, which is trained end-to-end. Using this model, we can address graph completion, a rampant and inherently difficult problem of recovering missing nodes and their associated edges of partially observed graphs. Experimental results on both synthetic and real-world datasets demonstrate the superiority of our method compared with state-of-the-art baselines.