 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputationally efficient joint coordination of multiple electric vehicle charging points using reinforcement learning
Mar 26, 2022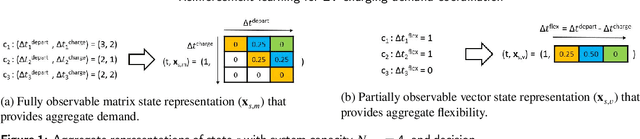


A major challenge in todays power grid is to manage the increasing load from electric vehicle (EV) charging. Demand response (DR) solutions aim to exploit flexibility therein, i.e., the ability to shift EV charging in time and thus avoid excessive peaks or achieve better balancing. Whereas the majority of existing research works either focus on control strategies for a single EV charger, or use a multi-step approach (e.g., a first high level aggregate control decision step, followed by individual EV control decisions), we rather propose a single-step solution that jointly coordinates multiple charging points at once. In this paper, we further refine an initial proposal using reinforcement learning (RL), specifically addressing computational challenges that would limit its deployment in practice. More precisely, we design a new Markov decision process (MDP) formulation of the EV charging coordination process, exhibiting only linear space and time complexity (as opposed to the earlier quadratic space complexity). We thus improve upon earlier state-of-the-art, demonstrating 30% reduction of training time in our case study using real-world EV charging session data. Yet, we do not sacrifice the resulting performance in meeting the DR objectives: our new RL solutions still improve the performance of charging demand coordination by 40-50% compared to a business-as-usual policy (that charges EV fully upon arrival) and 20-30% compared to a heuristic policy (that uniformly spreads individual EV charging over time).
Optimized cost function for demand response coordination of multiple EV charging stations using reinforcement learning
Mar 03, 2022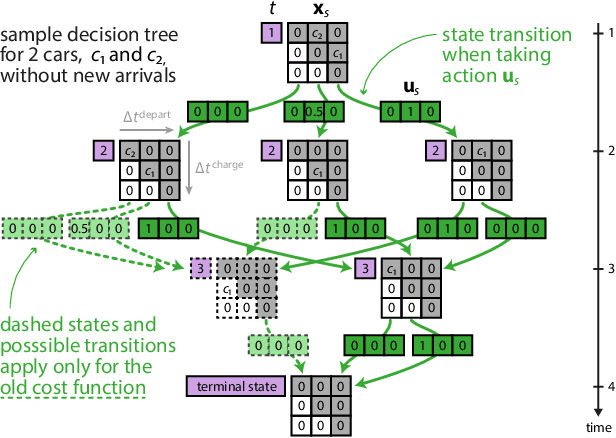
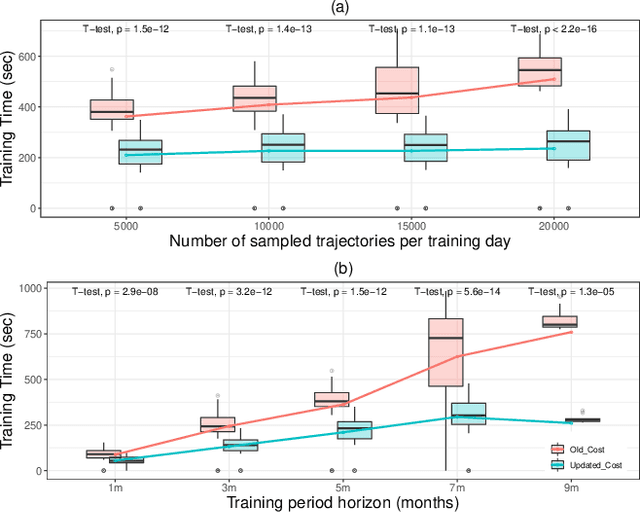
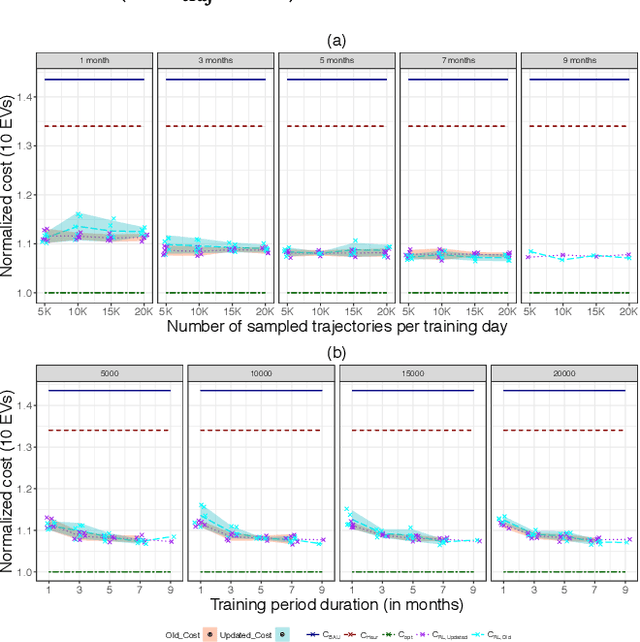
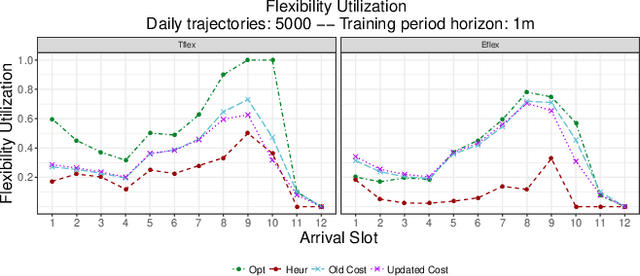
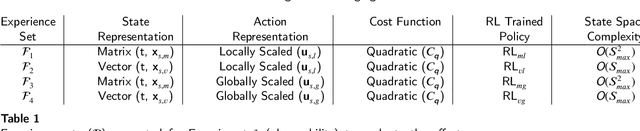
Electric vehicle (EV) charging stations represent a substantial load with significant flexibility. The exploitation of that flexibility in demand response (DR) algorithms becomes increasingly important to manage and balance demand and supply in power grids. Model-free DR based on reinforcement learning (RL) is an attractive approach to balance such EV charging load. We build on previous research on RL, based on a Markov decision process (MDP) to simultaneously coordinate multiple charging stations. However, we note that the computationally expensive cost function adopted in the previous research leads to large training times, which limits the feasibility and practicality of the approach. We, therefore, propose an improved cost function that essentially forces the learned control policy to always fulfill any charging demand that does not offer any flexibility. We rigorously compare the newly proposed batch RL fitted Q-iteration implementation with the original (costly) one, using real-world data. Specifically, for the case of load flattening, we compare the two approaches in terms of (i) the processing time to learn the RL-based charging policy, as well as (ii) the overall performance of the policy decisions in terms of meeting the target load for unseen test data. The performance is analyzed for different training periods and varying training sample sizes. In addition to both RL policies performance results, we provide performance bounds in terms of both (i) an optimal all-knowing strategy, and (ii) a simple heuristic spreading individual EV charging uniformly over time
Definition and evaluation of model-free coordination of electrical vehicle charging with reinforcement learning
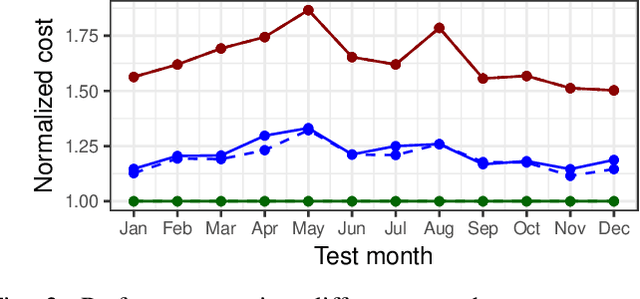
Sep 27, 2018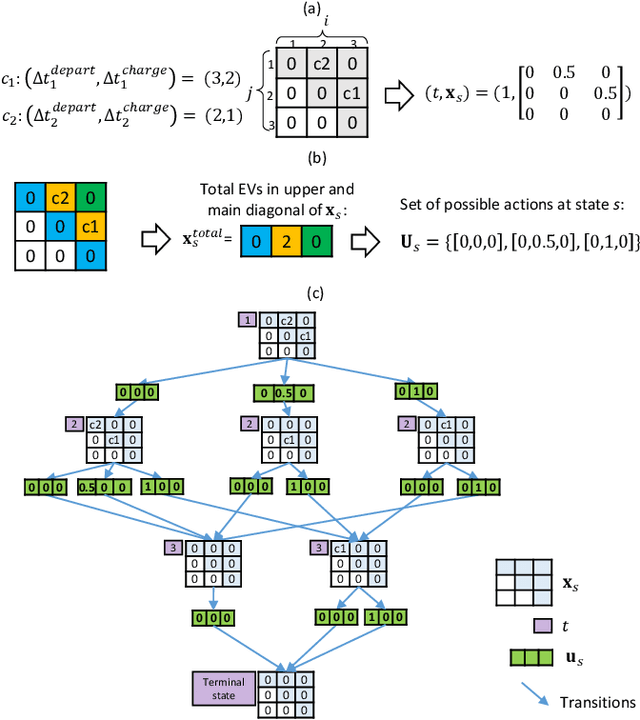

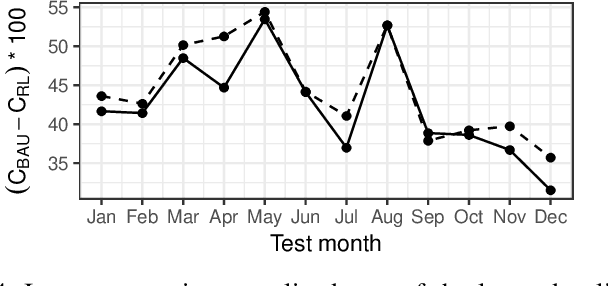
Initial DR studies mainly adopt model predictive control and thus require accurate models of the control problem (e.g., a customer behavior model), which are to a large extent uncertain for the EV scenario. Hence, model-free approaches, especially based on reinforcement learning (RL) are an attractive alternative. In this paper, we propose a new Markov decision process (MDP) formulation in the RL framework, to jointly coordinate a set of EV charging stations. State-of-the-art algorithms either focus on a single EV, or perform the control of an aggregate of EVs in multiple steps (e.g., aggregate load decisions in one step, then a step translating the aggregate decision to individual connected EVs). On the contrary, we propose an RL approach to jointly control the whole set of EVs at once. We contribute a new MDP formulation, with a scalable state representation that is independent of the number of EV charging stations. Further, we use a batch reinforcement learning algorithm, i.e., an instance of fitted Q-iteration, to learn the optimal charging policy. We analyze its performance using simulation experiments based on a real-world EV charging data. More specifically, we (i) explore the various settings in training the RL policy (e.g., duration of the period with training data), (ii) compare its performance to an oracle all-knowing benchmark (which provides an upper bound for performance, relying on information that is not available or at least imperfect in practice), (iii) analyze performance over time, over the course of a full year to evaluate possible performance fluctuations (e.g, across different seasons), and (iv) demonstrate the generalization capacity of a learned control policy to larger sets of charging stations.