 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarization of User-Generated Sports Video by Using Deep Action Recognition Features
Apr 13, 2018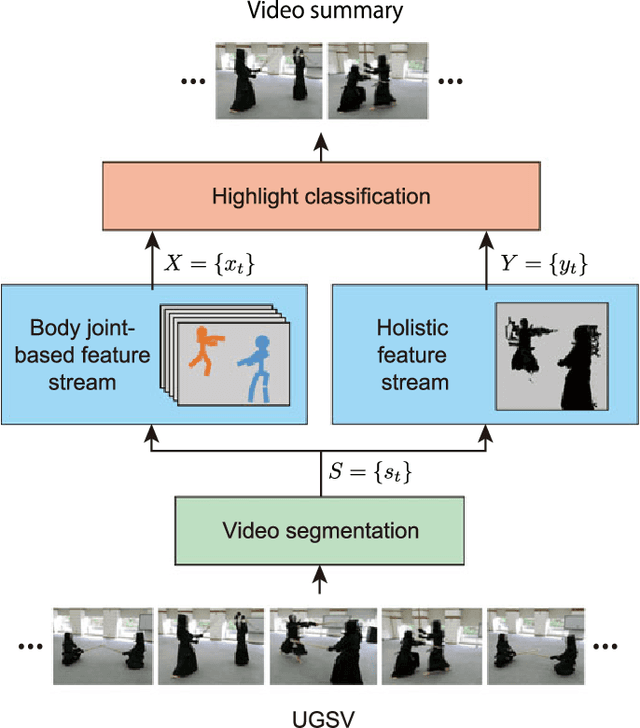

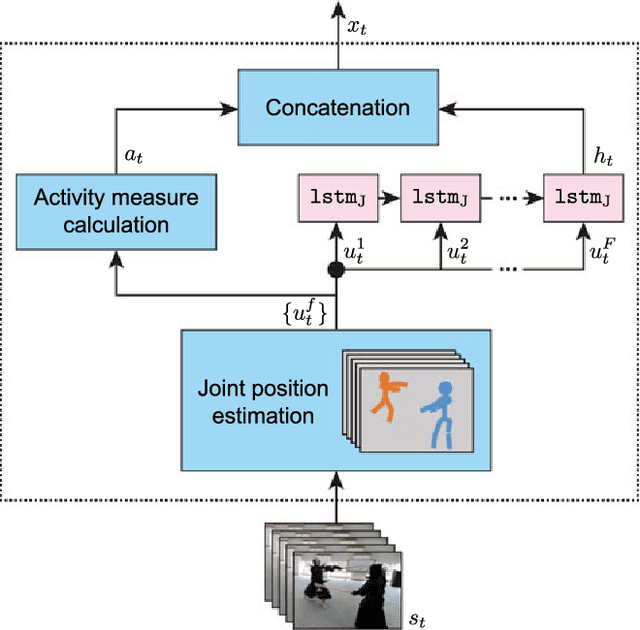
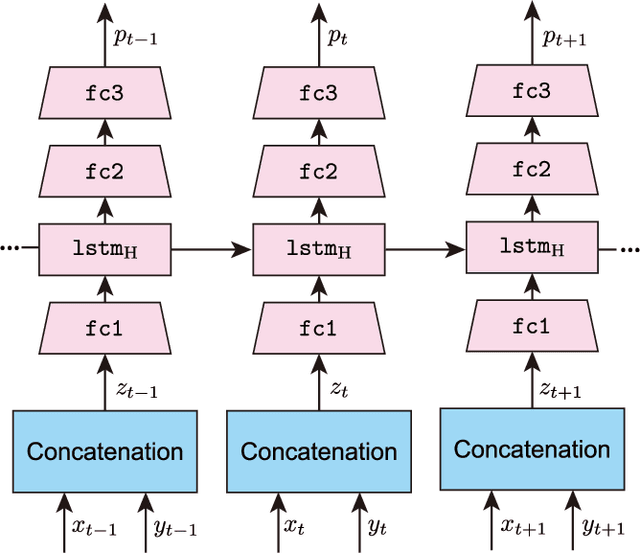
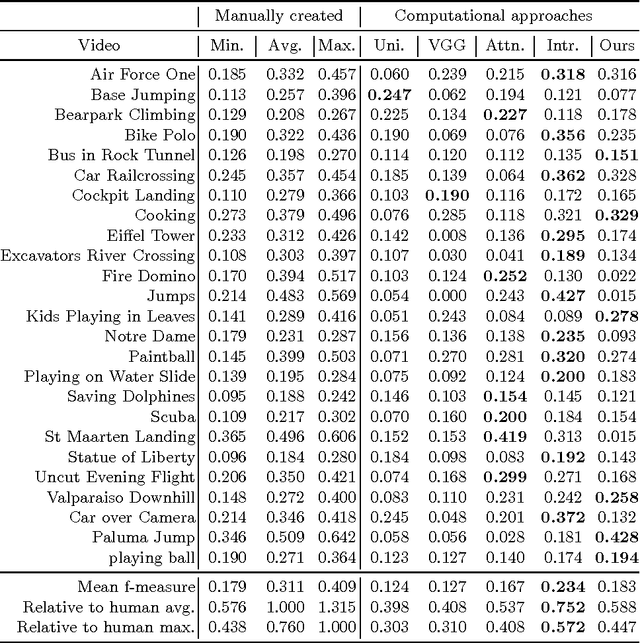
Automatically generating a summary of sports video poses the challenge of detecting interesting moments, or highlights, of a game. Traditional sports video summarization methods leverage editing conventions of broadcast sports video that facilitate the extraction of high-level semantics. However, user-generated videos are not edited, and thus traditional methods are not suitable to generate a summary. In order to solve this problem, this work proposes a novel video summarization method that uses players' actions as a cue to determine the highlights of the original video. A deep neural network-based approach is used to extract two types of action-related features and to classify video segments into interesting or uninteresting parts. The proposed method can be applied to any sports in which games consist of a succession of actions. Especially, this work considers the case of Kendo (Japanese fencing) as an example of a sport to evaluate the proposed method. The method is trained using Kendo videos with ground truth labels that indicate the video highlights. The labels are provided by annotators possessing different experience with respect to Kendo to demonstrate how the proposed method adapts to different needs. The performance of the proposed method is compared with several combinations of different features, and the results show that it outperforms previous summarization methods.
Video Summarization using Deep Semantic Features
Sep 28, 2016


This paper presents a video summarization technique for an Internet video to provide a quick way to overview its content. This is a challenging problem because finding important or informative parts of the original video requires to understand its content. Furthermore the content of Internet videos is very diverse, ranging from home videos to documentaries, which makes video summarization much more tough as prior knowledge is almost not available. To tackle this problem, we propose to use deep video features that can encode various levels of content semantics, including objects, actions, and scenes, improving the efficiency of standard video summarization techniques. For this, we design a deep neural network that maps videos as well as descriptions to a common semantic space and jointly trained it with associated pairs of videos and descriptions. To generate a video summary, we extract the deep features from each segment of the original video and apply a clustering-based summarization technique to them. We evaluate our video summaries using the SumMe dataset as well as baseline approaches. The results demonstrated the advantages of incorporating our deep semantic features in a video summarization technique.
Learning Joint Representations of Videos and Sentences with Web Image Search
Aug 08, 2016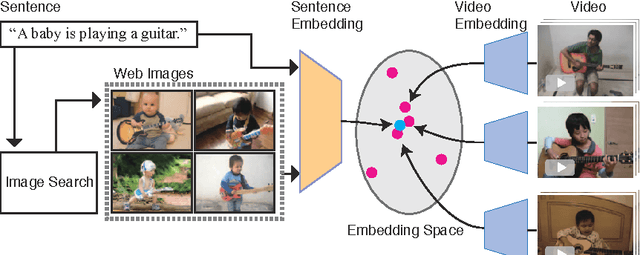
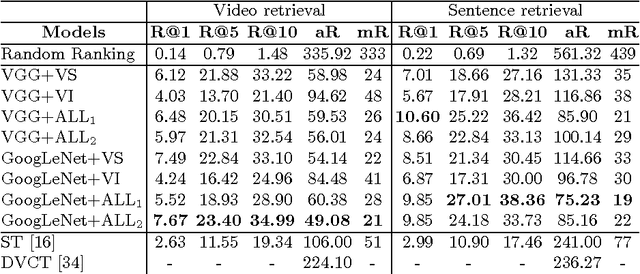
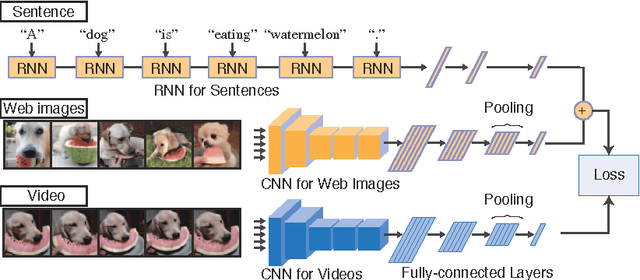
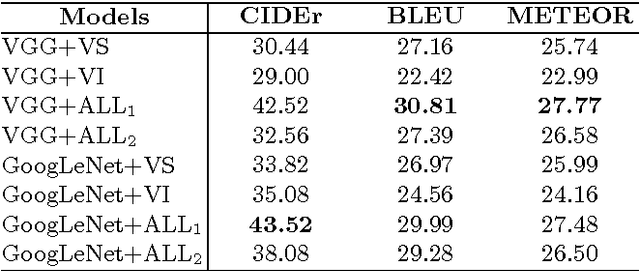
Our objective is video retrieval based on natural language queries. In addition, we consider the analogous problem of retrieving sentences or generating descriptions given an input video. Recent work has addressed the problem by embedding visual and textual inputs into a common space where semantic similarities correlate to distances. We also adopt the embedding approach, and make the following contributions: First, we utilize web image search in sentence embedding process to disambiguate fine-grained visual concepts. Second, we propose embedding models for sentence, image, and video inputs whose parameters are learned simultaneously. Finally, we show how the proposed model can be applied to description generation. Overall, we observe a clear improvement over the state-of-the-art methods in the video and sentence retrieval tasks. In description generation, the performance level is comparable to the current state-of-the-art, although our embeddings were trained for the retrieval tasks.