 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTale of tails using rule augmented sequence labeling for event extraction
Aug 22, 2019
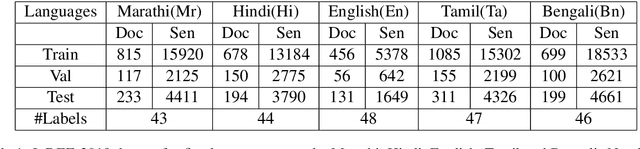
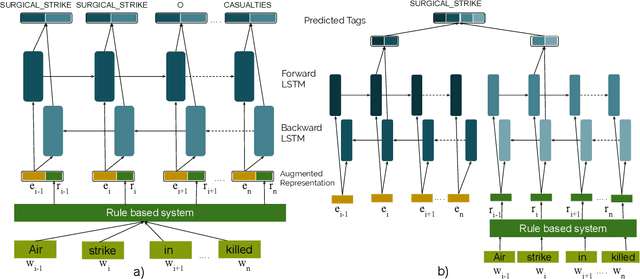
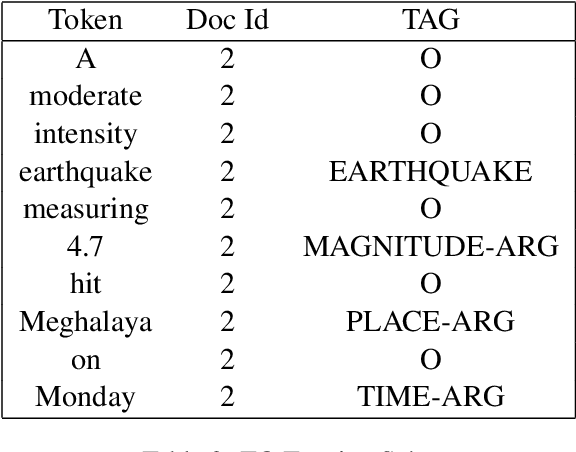
The problem of event extraction is a relatively difficult task for low resource languages due to the non-availability of sufficient annotated data. Moreover, the task becomes complex for tail (rarely occurring) labels wherein extremely less data is available. In this paper, we present a new dataset (InDEE-2019) in the disaster domain for multiple Indic languages, collected from news websites. Using this dataset, we evaluate several rule-based mechanisms to augment deep learning based models. We formulate our problem of event extraction as a sequence labeling task and perform extensive experiments to study and understand the effectiveness of different approaches. We further show that tail labels can be easily incorporated by creating new rules without the requirement of large annotated data.