 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPCSE: Neural Speech Enhancement through Linear Predictive Coding
Jun 22, 2022

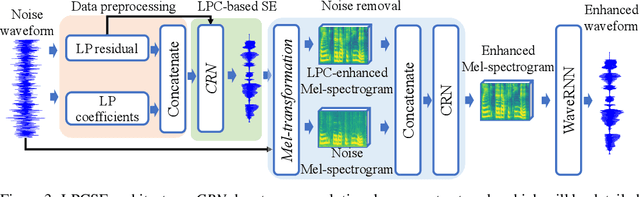

The increasingly stringent requirement on quality-of-experience in 5G/B5G communication systems has led to the emerging neural speech enhancement techniques, which however have been developed in isolation from the existing expert-rule based models of speech pronunciation and distortion, such as the classic Linear Predictive Coding (LPC) speech model because it is difficult to integrate the models with auto-differentiable machine learning frameworks. In this paper, to improve the efficiency of neural speech enhancement, we introduce an LPC-based speech enhancement (LPCSE) architecture, which leverages the strong inductive biases in the LPC speech model in conjunction with the expressive power of neural networks. Differentiable end-to-end learning is achieved in LPCSE via two novel blocks: a block that utilizes the expert rules to reduce the computational overhead when integrating the LPC speech model into neural networks, and a block that ensures the stability of the model and avoids exploding gradients in end-to-end training by mapping the Linear prediction coefficients to the filter poles. The experimental results show that LPCSE successfully restores the formants of the speeches distorted by transmission loss, and outperforms two existing neural speech enhancement methods of comparable neural network sizes in terms of the Perceptual evaluation of speech quality (PESQ) and Short-Time Objective Intelligibility (STOI) on the LJ Speech corpus.