 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Traditional DoE: Deep Reinforcement Learning for Optimizing Experiments in Model Identification of Battery Dynamics
Oct 12, 2023Model identification of battery dynamics is a central problem in energy research; many energy management systems and design processes rely on accurate battery models for efficiency optimization. The standard methodology for battery modelling is traditional design of experiments (DoE), where the battery dynamics are excited with many different current profiles and the measured outputs are used to estimate the system dynamics. However, although it is possible to obtain useful models with the traditional approach, the process is time consuming and expensive because of the need to sweep many different current-profile configurations. In the present work, a novel DoE approach is developed based on deep reinforcement learning, which alters the configuration of the experiments on the fly based on the statistics of past experiments. Instead of sticking to a library of predefined current profiles, the proposed approach modifies the current profiles dynamically by updating the output space covered by past measurements, hence only the current profiles that are informative for future experiments are applied. Simulations and real experiments are used to show that the proposed approach gives models that are as accurate as those obtained with traditional DoE but by using 85\% less resources.
Nonlinear Model Based Guidance with Deep Learning Based Target Trajectory Prediction Against Aerial Agile Attack Patterns
Apr 06, 2021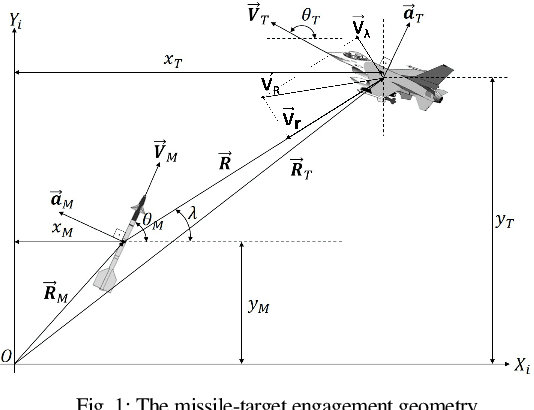
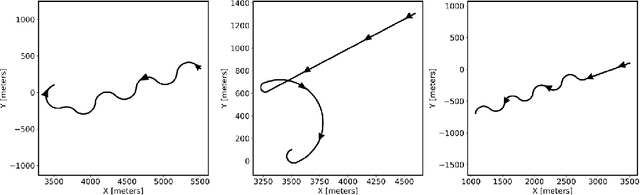
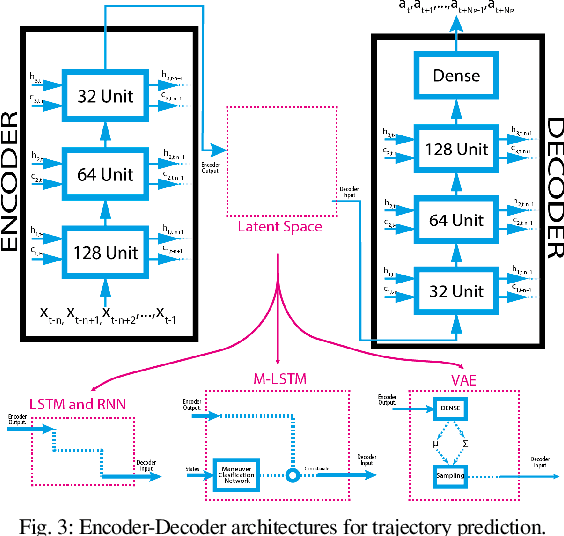
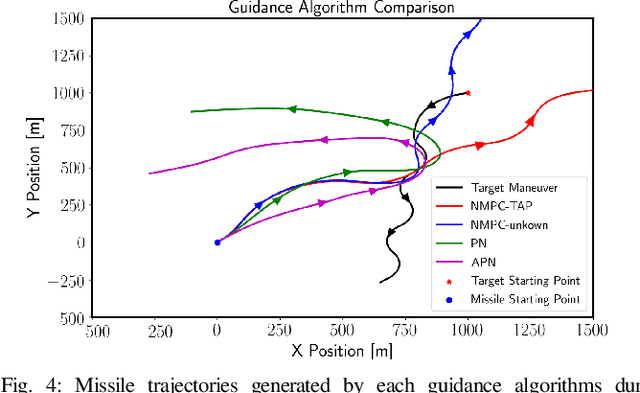
In this work, we propose a novel missile guidance algorithm that combines deep learning based trajectory prediction with nonlinear model predictive control. Although missile guidance and threat interception is a well-studied problem, existing algorithms' performance degrades significantly when the target is pulling high acceleration attack maneuvers while rapidly changing its direction. We argue that since most threats execute similar attack maneuvers, these nonlinear trajectory patterns can be processed with modern machine learning methods to build high accuracy trajectory prediction algorithms. We train a long short-term memory network (LSTM) based on a class of simulated structured agile attack patterns, then combine this predictor with quadratic programming based nonlinear model predictive control (NMPC). Our method, named nonlinear model based predictive control with target acceleration predictions (NMPC-TAP), significantly outperforms compared approaches in terms of miss distance, for the scenarios where the target/threat is executing agile maneuvers.
Learning How to Trade-Off Safety with Agility Using Deep Covariance Estimation for Perception Driven UAV Motion Planning
Dec 11, 2020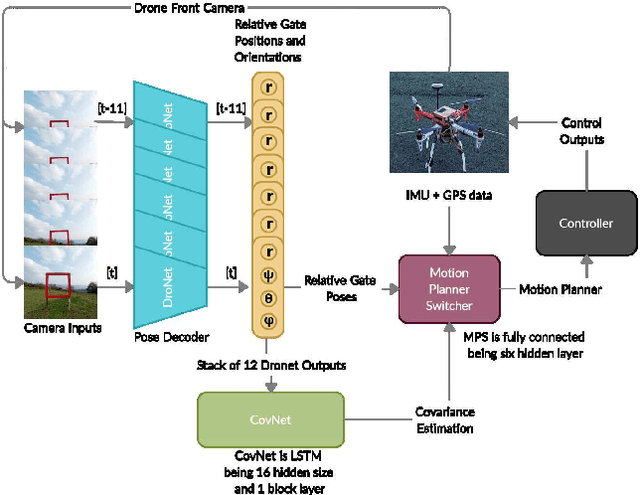
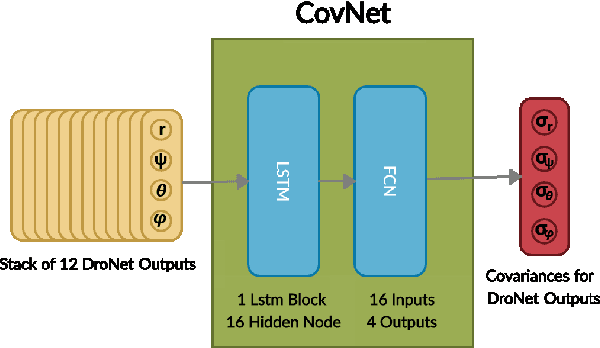
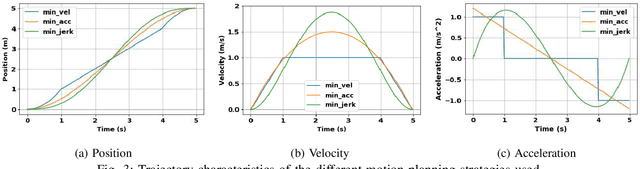
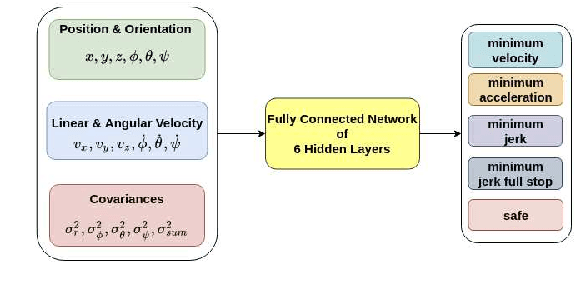
We investigate how to utilize predictive models for selecting appropriate motion planning strategies based on perception uncertainty estimation for agile unmanned aerial vehicle (UAV) navigation tasks. Although there are variety of motion planning and perception algorithms for such tasks, the impact of perception uncertainty is not explicitly handled in many of the current motion algorithms, which leads to performance loss in real-life scenarios where the measurement are often noisy due to external disturbances. We develop a novel framework for embedding perception uncertainty to high level motion planning management, in order to select the best available motion planning approach for the currently estimated perception uncertainty. We estimate the uncertainty in visual inputs using a deep neural network (CovNet) that explicitly predicts the covariance of the current measurements. Next, we train a high level machine learning model for predicting the lowest cost motion planning algorithm given the current estimate of covariance as well as the UAV states. We demonstrate on both real-life data and drone racing simulations that our approach, named uncertainty driven motion planning switcher (UDS) yields the safest and fastest trajectories among compared alternatives. Furthermore, we show that the developed approach learns how to trade-off safety with agility by switching to motion planners that leads to more agile trajectories when the estimated covariance is high and vice versa.
A New Approach for Tactical Decision Making in Lane Changing: Sample Efficient Deep Q Learning with a Safety Feedback Reward
Sep 24, 2020
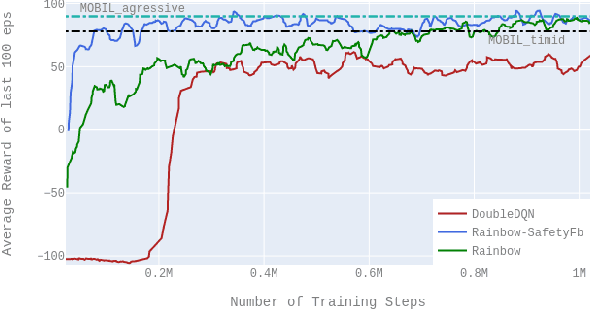
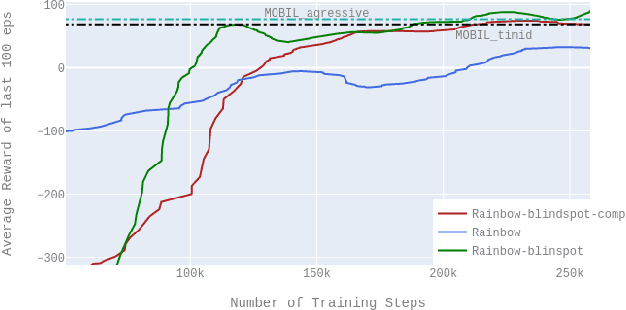
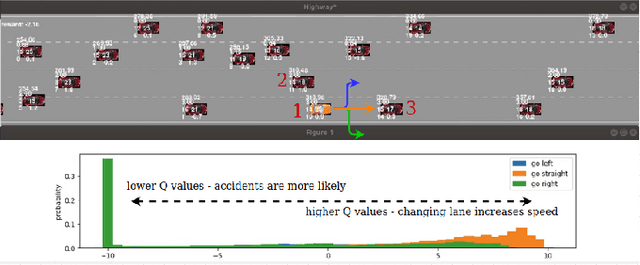
Automated lane change is one of the most challenging task to be solved of highly automated vehicles due to its safety-critical, uncertain and multi-agent nature. This paper presents the novel deployment of the state of art Q learning method, namely Rainbow DQN, that uses a new safety driven rewarding scheme to tackle the issues in an dynamic and uncertain simulation environment. We present various comparative results to show that our novel approach of having reward feedback from the safety layer dramatically increases both the agent's performance and sample efficiency. Furthermore, through the novel deployment of Rainbow DQN, it is shown that more intuition about the agent's actions is extracted by examining the distributions of generated Q values of the agents. The proposed algorithm shows superior performance to the baseline algorithm in the challenging scenarios with only 200000 training steps (i.e. equivalent to 55 hours driving).