 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Network for Multi-Person Tracking and Re-Identification in Unconstrained Environment
Dec 19, 2023Multi-object tracking (MOT) has profound applications in a variety of fields, including surveillance, sports analytics, self-driving, and cooperative robotics. Despite considerable advancements, existing MOT methodologies tend to falter when faced with non-uniform movements, occlusions, and appearance-reappearance scenarios of the objects. Recognizing this inadequacy, we put forward an integrated MOT method that not only marries object detection and identity linkage within a singular, end-to-end trainable framework but also equips the model with the ability to maintain object identity links over long periods of time. Our proposed model, named STMMOT, is built around four key modules: 1) candidate proposal generation, which generates object proposals via a vision-transformer encoder-decoder architecture that detects the object from each frame in the video; 2) scale variant pyramid, a progressive pyramid structure to learn the self-scale and cross-scale similarities in multi-scale feature maps; 3) spatio-temporal memory encoder, extracting the essential information from the memory associated with each object under tracking; and 4) spatio-temporal memory decoder, simultaneously resolving the tasks of object detection and identity association for MOT. Our system leverages a robust spatio-temporal memory module that retains extensive historical observations and effectively encodes them using an attention-based aggregator. The uniqueness of STMMOT lies in representing objects as dynamic query embeddings that are updated continuously, which enables the prediction of object states with attention mechanisms and eradicates the need for post-processing.
A Robust Hybrid Approach for Textual Document Classification
Sep 12, 2019
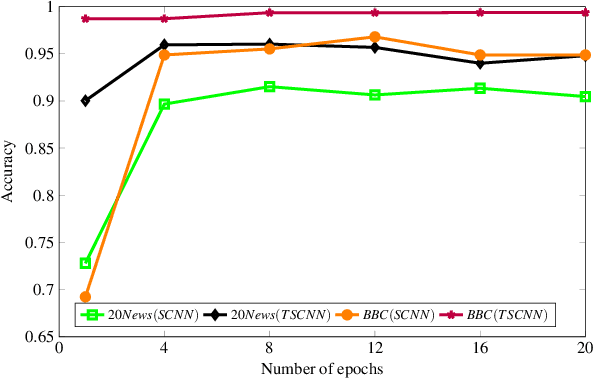

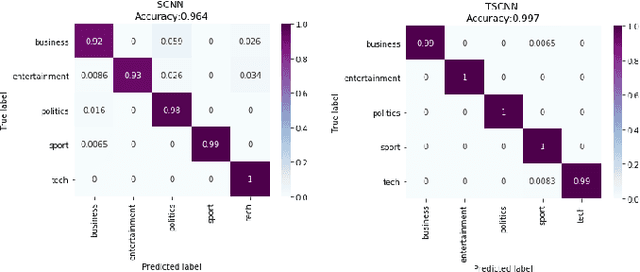
Text document classification is an important task for diverse natural language processing based applications. Traditional machine learning approaches mainly focused on reducing dimensionality of textual data to perform classification. This although improved the overall classification accuracy, the classifiers still faced sparsity problem due to lack of better data representation techniques. Deep learning based text document classification, on the other hand, benefitted greatly from the invention of word embeddings that have solved the sparsity problem and researchers focus mainly remained on the development of deep architectures. Deeper architectures, however, learn some redundant features that limit the performance of deep learning based solutions. In this paper, we propose a two stage text document classification methodology which combines traditional feature engineering with automatic feature engineering (using deep learning). The proposed methodology comprises a filter based feature selection (FSE) algorithm followed by a deep convolutional neural network. This methodology is evaluated on the two most commonly used public datasets, i.e., 20 Newsgroups data and BBC news data. Evaluation results reveal that the proposed methodology outperforms the state-of-the-art of both the (traditional) machine learning and deep learning based text document classification methodologies with a significant margin of 7.7% on 20 Newsgroups and 6.6% on BBC news datasets.