 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Deep Learning with Fixed Time Budget
Oct 03, 2024The success of modern deep learning is attributed to two key elements: huge amounts of training data and large model sizes. Where a vast amount of data allows the model to learn more features, the large model architecture boosts the learning capability of the model. However, both these factors result in prolonged training time. In some practical applications such as edge-based learning and federated learning, limited-time budgets necessitate more efficient training methods. This paper proposes an effective technique for training arbitrary deep learning models within fixed time constraints utilizing sample importance and dynamic ranking. The proposed method is extensively evaluated in both classification and regression tasks in computer vision. The results consistently show clear gains achieved by the proposed method in improving the learning performance of various state-of-the-art deep learning models in both regression and classification tasks.
Object Depth and Size Estimation using Stereo-vision and Integration with SLAM
Sep 11, 2024



Autonomous robots use simultaneous localization and mapping (SLAM) for efficient and safe navigation in various environments. LiDAR sensors are integral in these systems for object identification and localization. However, LiDAR systems though effective in detecting solid objects (e.g., trash bin, bottle, etc.), encounter limitations in identifying semitransparent or non-tangible objects (e.g., fire, smoke, steam, etc.) due to poor reflecting characteristics. Additionally, LiDAR also fails to detect features such as navigation signs and often struggles to detect certain hazardous materials that lack a distinct surface for effective laser reflection. In this paper, we propose a highly accurate stereo-vision approach to complement LiDAR in autonomous robots. The system employs advanced stereo vision-based object detection to detect both tangible and non-tangible objects and then uses simple machine learning to precisely estimate the depth and size of the object. The depth and size information is then integrated into the SLAM process to enhance the robot's navigation capabilities in complex environments. Our evaluation, conducted on an autonomous robot equipped with LiDAR and stereo-vision systems demonstrates high accuracy in the estimation of an object's depth and size. A video illustration of the proposed scheme is available at: \url{https://www.youtube.com/watch?v=nusI6tA9eSk}.
Haris: an Advanced Autonomous Mobile Robot for Smart Parking Assistance
Jan 31, 2024
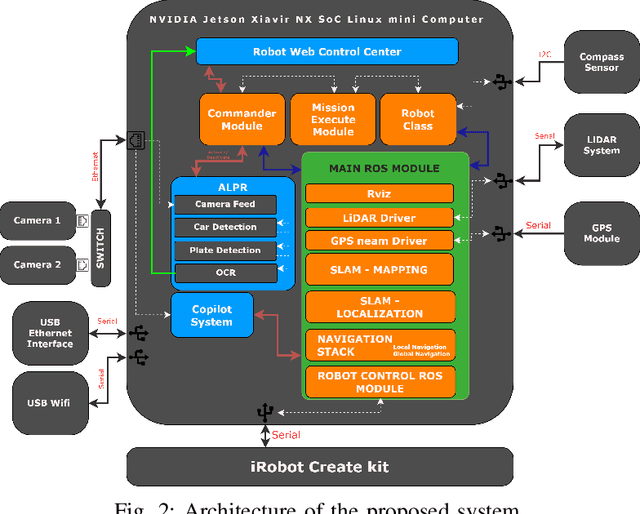
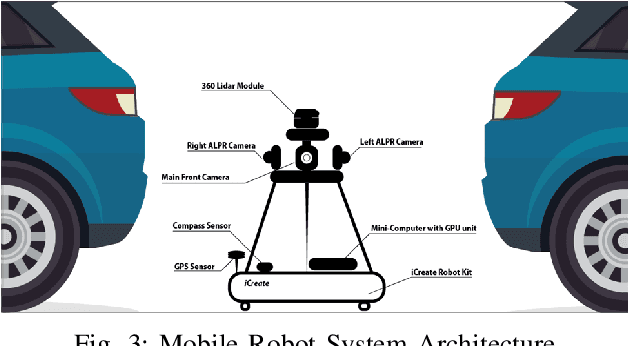

This paper presents Haris, an advanced autonomous mobile robot system for tracking the location of vehicles in crowded car parks using license plate recognition. The system employs simultaneous localization and mapping (SLAM) for autonomous navigation and precise mapping of the parking area, eliminating the need for GPS dependency. In addition, the system utilizes a sophisticated framework using computer vision techniques for object detection and automatic license plate recognition (ALPR) for reading and associating license plate numbers with location data. This information is subsequently synchronized with a back-end service and made accessible to users via a user-friendly mobile app, offering effortless vehicle location and alleviating congestion within the parking facility. The proposed system has the potential to improve the management of short-term large outdoor parking areas in crowded places such as sports stadiums. The demo of the robot can be found on https://youtu.be/ZkTCM35fxa0?si=QjggJuN7M1o3oifx.
Curriculum for Crowd Counting -- Is it Worthy?
Jan 15, 2024Recent advances in deep learning techniques have achieved remarkable performance in several computer vision problems. A notably intuitive technique called Curriculum Learning (CL) has been introduced recently for training deep learning models. Surprisingly, curriculum learning achieves significantly improved results in some tasks but marginal or no improvement in others. Hence, there is still a debate about its adoption as a standard method to train supervised learning models. In this work, we investigate the impact of curriculum learning in crowd counting using the density estimation method. We performed detailed investigations by conducting 112 experiments using six different CL settings using eight different crowd models. Our experiments show that curriculum learning improves the model learning performance and shortens the convergence time.
Multimodal Crowd Counting with Pix2Pix GANs
Jan 15, 2024Most state-of-the-art crowd counting methods use color (RGB) images to learn the density map of the crowd. However, these methods often struggle to achieve higher accuracy in densely crowded scenes with poor illumination. Recently, some studies have reported improvement in the accuracy of crowd counting models using a combination of RGB and thermal images. Although multimodal data can lead to better predictions, multimodal data might not be always available beforehand. In this paper, we propose the use of generative adversarial networks (GANs) to automatically generate thermal infrared (TIR) images from color (RGB) images and use both to train crowd counting models to achieve higher accuracy. We use a Pix2Pix GAN network first to translate RGB images to TIR images. Our experiments on several state-of-the-art crowd counting models and benchmark crowd datasets report significant improvement in accuracy.
Crowd Counting in Harsh Weather using Image Denoising with Pix2Pix GANs
Oct 11, 2023Visual crowd counting estimates the density of the crowd using deep learning models such as convolution neural networks (CNNs). The performance of the model heavily relies on the quality of the training data that constitutes crowd images. In harsh weather such as fog, dust, and low light conditions, the inference performance may severely degrade on the noisy and blur images. In this paper, we propose the use of Pix2Pix generative adversarial network (GAN) to first denoise the crowd images prior to passing them to the counting model. A Pix2Pix network is trained using synthetic noisy images generated from original crowd images and then the pretrained generator is then used in the inference engine to estimate the crowd density in unseen, noisy crowd images. The performance is tested on JHU-Crowd dataset to validate the significance of the proposed method particularly when high reliability and accuracy are required.
Visual Crowd Analysis: Open Research Problems
Aug 24, 2023Over the last decade, there has been a remarkable surge in interest in automated crowd monitoring within the computer vision community. Modern deep-learning approaches have made it possible to develop fully-automated vision-based crowd-monitoring applications. However, despite the magnitude of the issue at hand, the significant technological advancements, and the consistent interest of the research community, there are still numerous challenges that need to be overcome. In this article, we delve into six major areas of visual crowd analysis, emphasizing the key developments in each of these areas. We outline the crucial unresolved issues that must be tackled in future works, in order to ensure that the field of automated crowd monitoring continues to progress and thrive. Several surveys related to this topic have been conducted in the past. Nonetheless, this article thoroughly examines and presents a more intuitive categorization of works, while also depicting the latest breakthroughs within the field, incorporating more recent studies carried out within the last few years in a concise manner. By carefully choosing prominent works with significant contributions in terms of novelty or performance gains, this paper presents a more comprehensive exposition of advancements in the current state-of-the-art.
LCDnet: A Lightweight Crowd Density Estimation Model for Real-time Video Surveillance
Feb 10, 2023Automatic crowd counting using density estimation has gained significant attention in computer vision research. As a result, a large number of crowd counting and density estimation models using convolution neural networks (CNN) have been published in the last few years. These models have achieved good accuracy over benchmark datasets. However, attempts to improve the accuracy often lead to higher complexity in these models. In real-time video surveillance applications using drones with limited computing resources, deep models incur intolerable higher inference delay. In this paper, we propose (i) a Lightweight Crowd Density estimation model (LCDnet) for real-time video surveillance, and (ii) an improved training method using curriculum learning (CL). LCDnet is trained using CL and evaluated over two benchmark datasets i.e., DroneRGBT and CARPK. Results are compared with existing crowd models. Our evaluation shows that the LCDnet achieves a reasonably good accuracy while significantly reducing the inference time and memory requirement and thus can be deployed over edge devices with very limited computing resources.
Unauthorized Drone Detection: Experiments and Prototypes
Dec 02, 2022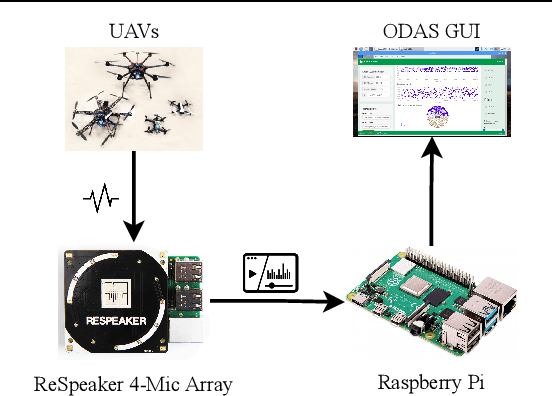

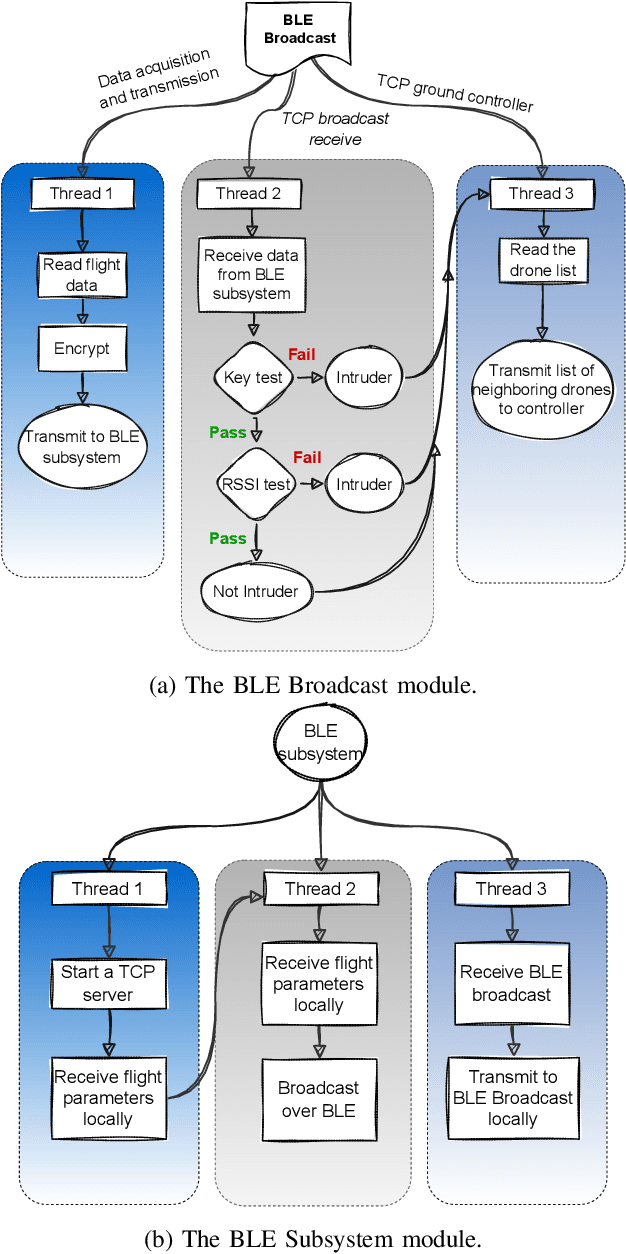
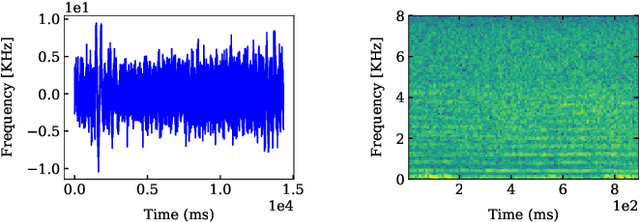
The increase in the number of unmanned aerial vehicles a.k.a. drones pose several threats to public privacy, critical infrastructure and cyber security. Hence, detecting unauthorized drones is a significant problem which received attention in the last few years. In this paper, we present our experimental work on three drone detection methods (i.e., acoustic detection, radio frequency (RF) detection, and visual detection) to evaluate their efficacy in both indoor and outdoor environments. Owing to the limitations of these schemes, we present a novel encryption-based drone detection scheme that uses a two-stage verification of the drone's received signal strength indicator (RSSI) and the encryption key generated from the drone's position coordinates to reliably detect an unauthorized drone in the presence of authorized drones.
Crowd Density Estimation using Imperfect Labels
Dec 02, 2022Density estimation is one of the most widely used methods for crowd counting in which a deep learning model learns from head-annotated crowd images to estimate crowd density in unseen images. Typically, the learning performance of the model is highly impacted by the accuracy of the annotations and inaccurate annotations may lead to localization and counting errors during prediction. A significant amount of works exist on crowd counting using perfectly labelled datasets but none of these explore the impact of annotation errors on the model accuracy. In this paper, we investigate the impact of imperfect labels (both noisy and missing labels) on crowd counting accuracy. We propose a system that automatically generates imperfect labels using a deep learning model (called annotator) which are then used to train a new crowd counting model (target model). Our analysis on two crowd counting models and two benchmark datasets shows that the proposed scheme achieves accuracy closer to that of the model trained with perfect labels showing the robustness of crowd models to annotation errors.