 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability by design: an experimental analysis of the legal coding process
May 03, 2025Behind a set of rules in Deontic Defeasible Logic, there is a mapping process of normative background fragments. This process goes from text to rules and implicitly encompasses an explanation of the coded fragments. In this paper we deliver a methodology for \textit{legal coding} that starts with a fragment and goes onto a set of Deontic Defeasible Logic rules, involving a set of \textit{scenarios} to test the correctness of the coded fragments. The methodology is illustrated by the coding process of an example text. We then show the results of a series of experiments conducted with humans encoding a variety of normative backgrounds and corresponding cases in which we have measured the efforts made in the coding process, as related to some measurable features. To process these examples, a recently developed technology, Houdini, that allows reasoning in Deontic Defeasible Logic, has been employed. Finally we provide a technique to forecast time required in coding, that depends on factors such as knowledge of the legal domain, knowledge of the coding processes, length of the text, and a measure of \textit{depth} that refers to the length of the paths of legal references.
A Survey on Methods and Metrics for the Assessment of Explainability under the Proposed AI Act
Oct 21, 2021
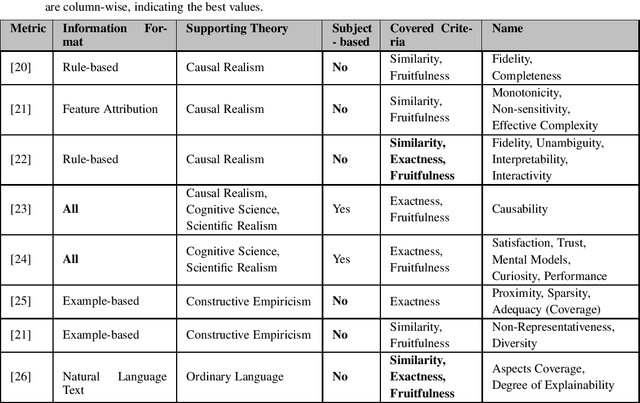
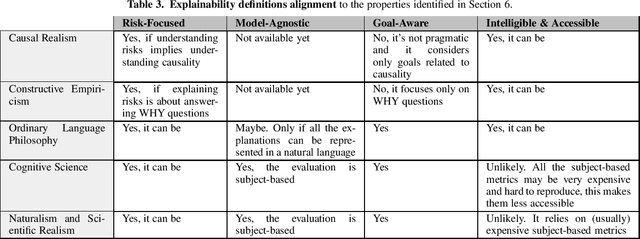
This study discusses the interplay between metrics used to measure the explainability of the AI systems and the proposed EU Artificial Intelligence Act. A standardisation process is ongoing: several entities (e.g. ISO) and scholars are discussing how to design systems that are compliant with the forthcoming Act and explainability metrics play a significant role. This study identifies the requirements that such a metric should possess to ease compliance with the AI Act. It does so according to an interdisciplinary approach, i.e. by departing from the philosophical concept of explainability and discussing some metrics proposed by scholars and standardisation entities through the lenses of the explainability obligations set by the proposed AI Act. Our analysis proposes that metrics to measure the kind of explainability endorsed by the proposed AI Act shall be risk-focused, model-agnostic, goal-aware, intelligible & accessible. This is why we discuss the extent to which these requirements are met by the metrics currently under discussion.
Making Things Explainable vs Explaining: Requirements and Challenges under the GDPR
Oct 02, 2021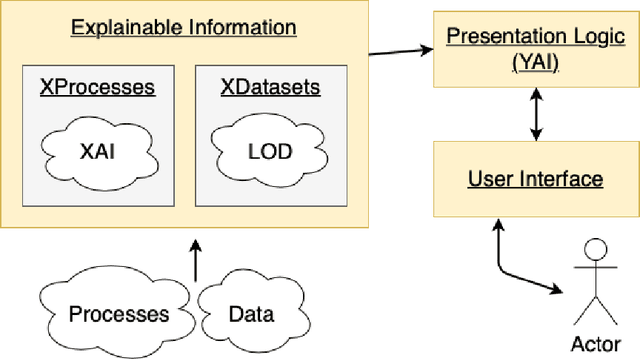

The European Union (EU) through the High-Level Expert Group on Artificial Intelligence (AI-HLEG) and the General Data Protection Regulation (GDPR) has recently posed an interesting challenge to the eXplainable AI (XAI) community, by demanding a more user-centred approach to explain Automated Decision-Making systems (ADMs). Looking at the relevant literature, XAI is currently focused on producing explainable software and explanations that generally follow an approach we could term One-Size-Fits-All, that is unable to meet a requirement of centring on user needs. One of the causes of this limit is the belief that making things explainable alone is enough to have pragmatic explanations. Thus, insisting on a clear separation between explainabilty (something that can be explained) and explanations, we point to explanatorY AI (YAI) as an alternative and more powerful approach to win the AI-HLEG challenge. YAI builds over XAI with the goal to collect and organize explainable information, articulating it into something we called user-centred explanatory discourses. Through the use of explanatory discourses/narratives we represent the problem of generating explanations for Automated Decision-Making systems (ADMs) into the identification of an appropriate path over an explanatory space, allowing explainees to interactively explore it and produce the explanation best suited to their needs.
Deep Learning Based Multi-Label Text Classification of UNGA Resolutions
Apr 01, 2020
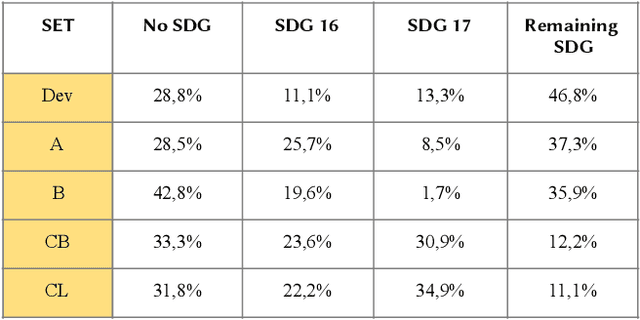
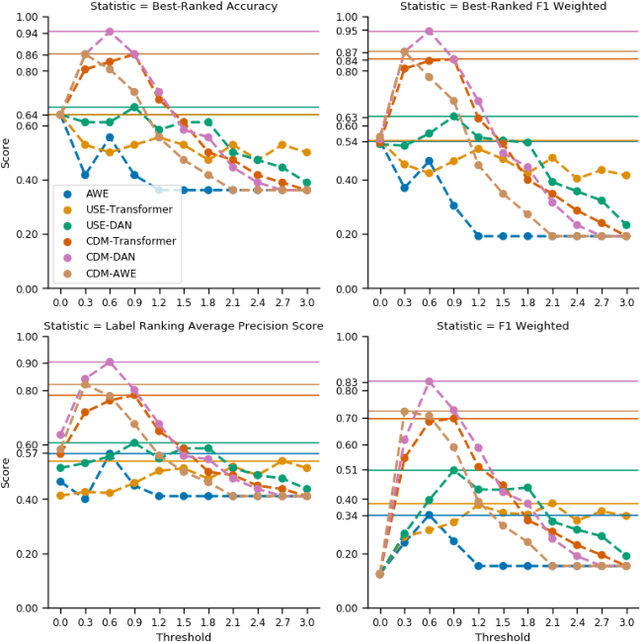
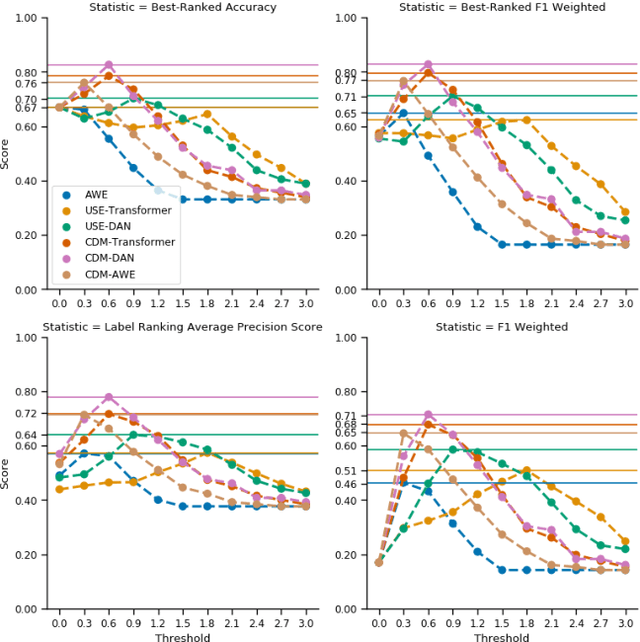
The main goal of this research is to produce a useful software for United Nations (UN), that could help to speed up the process of qualifying the UN documents following the Sustainable Development Goals (SDGs) in order to monitor the progresses at the world level to fight poverty, discrimination, climate changes. In fact human labeling of UN documents would be a daunting task given the size of the impacted corpus. Thus, automatic labeling must be adopted at least as a first step of a multi-phase process to reduce the overall effort of cataloguing and classifying. Deep Learning (DL) is nowadays one of the most powerful tools for state-of-the-art (SOTA) AI for this task, but very often it comes with the cost of an expensive and error-prone preparation of a training-set. In the case of multi-label text classification of domain-specific text it seems that we cannot effectively adopt DL without a big-enough domain-specific training-set. In this paper, we show that this is not always true. In fact we propose a novel method that is able, through statistics like TF-IDF, to exploit pre-trained SOTA DL models (such as the Universal Sentence Encoder) without any need for traditional transfer learning or any other expensive training procedure. We show the effectiveness of our method in a legal context, by classifying UN Resolutions according to their most related SDGs.