 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graphs Generation from Cultural Heritage Texts: Combining LLMs and Ontological Engineering for Scholarly Debates
Nov 13, 2025



Cultural Heritage texts contain rich knowledge that is difficult to query systematically due to the challenges of converting unstructured discourse into structured Knowledge Graphs (KGs). This paper introduces ATR4CH (Adaptive Text-to-RDF for Cultural Heritage), a systematic five-step methodology for Large Language Model-based Knowledge Extraction from Cultural Heritage documents. We validate the methodology through a case study on authenticity assessment debates. Methodology - ATR4CH combines annotation models, ontological frameworks, and LLM-based extraction through iterative development: foundational analysis, annotation schema development, pipeline architecture, integration refinement, and comprehensive evaluation. We demonstrate the approach using Wikipedia articles about disputed items (documents, artifacts...), implementing a sequential pipeline with three LLMs (Claude Sonnet 3.7, Llama 3.3 70B, GPT-4o-mini). Findings - The methodology successfully extracts complex Cultural Heritage knowledge: 0.96-0.99 F1 for metadata extraction, 0.7-0.8 F1 for entity recognition, 0.65-0.75 F1 for hypothesis extraction, 0.95-0.97 for evidence extraction, and 0.62 G-EVAL for discourse representation. Smaller models performed competitively, enabling cost-effective deployment. Originality - This is the first systematic methodology for coordinating LLM-based extraction with Cultural Heritage ontologies. ATR4CH provides a replicable framework adaptable across CH domains and institutional resources. Research Limitations - The produced KG is limited to Wikipedia articles. While the results are encouraging, human oversight is necessary during post-processing. Practical Implications - ATR4CH enables Cultural Heritage institutions to systematically convert textual knowledge into queryable KGs, supporting automated metadata enrichment and knowledge discovery.
Explicit vs. Implicit Biographies: Evaluating and Adapting LLM Information Extraction on Wikidata-Derived Texts
Sep 18, 2025Text Implicitness has always been challenging in Natural Language Processing (NLP), with traditional methods relying on explicit statements to identify entities and their relationships. From the sentence "Zuhdi attends church every Sunday", the relationship between Zuhdi and Christianity is evident for a human reader, but it presents a challenge when it must be inferred automatically. Large language models (LLMs) have proven effective in NLP downstream tasks such as text comprehension and information extraction (IE). This study examines how textual implicitness affects IE tasks in pre-trained LLMs: LLaMA 2.3, DeepSeekV1, and Phi1.5. We generate two synthetic datasets of 10k implicit and explicit verbalization of biographic information to measure the impact on LLM performance and analyze whether fine-tuning implicit data improves their ability to generalize in implicit reasoning tasks. This research presents an experiment on the internal reasoning processes of LLMs in IE, particularly in dealing with implicit and explicit contexts. The results demonstrate that fine-tuning LLM models with LoRA (low-rank adaptation) improves their performance in extracting information from implicit texts, contributing to better model interpretability and reliability.
From Knowledge to Conjectures: A Modal Framework for Reasoning about Hypotheses
Aug 10, 2025This paper introduces a new family of cognitive modal logics designed to formalize conjectural reasoning: a modal system in which cognitive contexts extend known facts with hypothetical assumptions to explore their consequences. Unlike traditional doxastic and epistemic systems, conjectural logics rely on a principle, called Axiom C ($\varphi \rightarrow \Box\varphi$), that ensures that all established facts are preserved across hypothetical layers. While Axiom C was dismissed in the past due to its association with modal collapse, we show that the collapse only arises under classical and bivalent assumptions, and specifically in the presence of Axiom T. Hence we avoid Axiom T and adopt a paracomplete semantic framework, grounded in Weak Kleene logic or Description Logic, where undefined propositions coexist with modal assertions. This prevents the modal collapse and guarantees a layering to distinguish between factual and conjectural statements. Under this framework we define new modal systems, e.g., KC and KDC, and show that they are complete, decidable, and robust under partial knowledge. Finally, we introduce a dynamic operation, $\mathsf{settle}(\varphi)$, which formalizes the transition from conjecture to accepted fact, capturing the event of the update of a world's cognitive state through the resolution of uncertainty.
Fast Calibrated Explanations: Efficient and Uncertainty-Aware Explanations for Machine Learning Models
Oct 28, 2024



This paper introduces Fast Calibrated Explanations, a method designed for generating rapid, uncertainty-aware explanations for machine learning models. By incorporating perturbation techniques from ConformaSight - a global explanation framework - into the core elements of Calibrated Explanations (CE), we achieve significant speedups. These core elements include local feature importance with calibrated predictions, both of which retain uncertainty quantification. While the new method sacrifices a small degree of detail, it excels in computational efficiency, making it ideal for high-stakes, real-time applications. Fast Calibrated Explanations are applicable to probabilistic explanations in classification and thresholded regression tasks, where they provide the likelihood of a target being above or below a user-defined threshold. This approach maintains the versatility of CE for both classification and probabilistic regression, making it suitable for a range of predictive tasks where uncertainty quantification is crucial.
KwicKwocKwac, a tool for rapidly generating concordances and marking up a literary text
Oct 08, 2024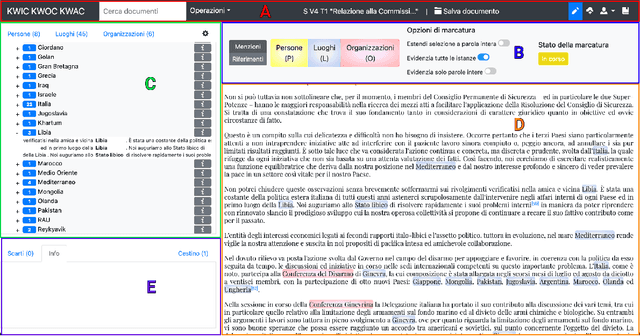
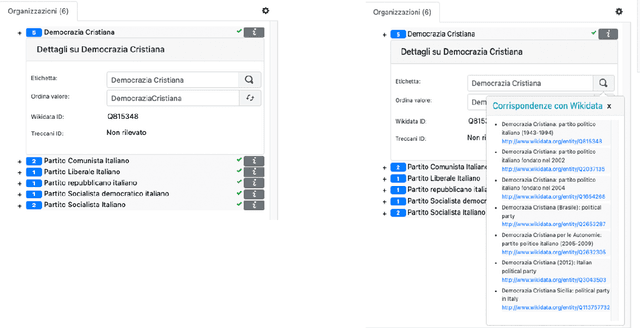
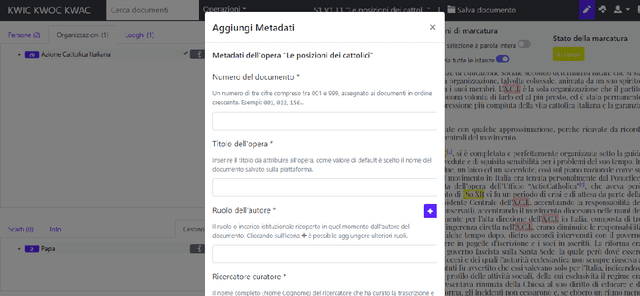
This paper introduces KwicKwocKwac 1.0 (KwicKK), a web application designed to enhance the annotation and enrichment of digital texts in the humanities. KwicKK provides a user-friendly interface that enables scholars and researchers to perform semi-automatic markup of textual documents, facilitating the identification of relevant entities such as people, organizations, and locations. Key functionalities include the visualization of annotated texts using KeyWord in Context (KWIC), KeyWord Out Of Context (KWOC), and KeyWord After Context (KWAC) methodologies, alongside automatic disambiguation of generic references and integration with Wikidata for Linked Open Data connections. The application supports metadata input and offers multiple download formats, promoting accessibility and ease of use. Developed primarily for the National Edition of Aldo Moro's works, KwicKK aims to lower the technical barriers for users while fostering deeper engagement with digital scholarly resources. The architecture leverages contemporary web technologies, ensuring scalability and reliability. Future developments will explore user experience enhancements, collaborative features, and integration of additional data sources.
A Survey on Methods and Metrics for the Assessment of Explainability under the Proposed AI Act
Oct 21, 2021
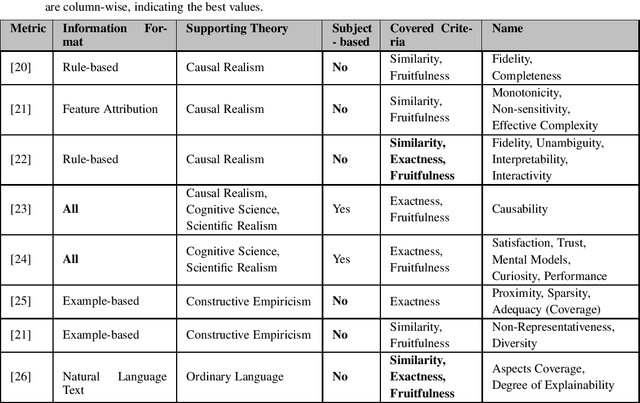
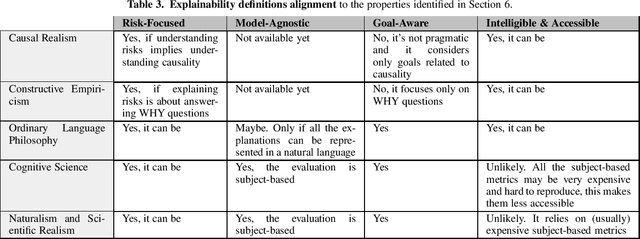
This study discusses the interplay between metrics used to measure the explainability of the AI systems and the proposed EU Artificial Intelligence Act. A standardisation process is ongoing: several entities (e.g. ISO) and scholars are discussing how to design systems that are compliant with the forthcoming Act and explainability metrics play a significant role. This study identifies the requirements that such a metric should possess to ease compliance with the AI Act. It does so according to an interdisciplinary approach, i.e. by departing from the philosophical concept of explainability and discussing some metrics proposed by scholars and standardisation entities through the lenses of the explainability obligations set by the proposed AI Act. Our analysis proposes that metrics to measure the kind of explainability endorsed by the proposed AI Act shall be risk-focused, model-agnostic, goal-aware, intelligible & accessible. This is why we discuss the extent to which these requirements are met by the metrics currently under discussion.
Generating User-Centred Explanations via Illocutionary Question Answering: From Philosophy to Interfaces
Oct 02, 2021



We propose a new method for generating explanations with Artificial Intelligence (AI) and a tool to test its expressive power within a user interface. In order to bridge the gap between philosophy and human-computer interfaces, we show a new approach for the generation of interactive explanations based on a sophisticated pipeline of AI algorithms for structuring natural language documents into knowledge graphs, answering questions effectively and satisfactorily. With this work we aim to prove that the philosophical theory of explanations presented by Achinstein can be actually adapted for being implemented into a concrete software application, as an interactive and illocutionary process of answering questions. Specifically, our contribution is an approach to frame illocution in a computer-friendly way, to achieve user-centrality with statistical question answering. In fact, we frame illocution, in an explanatory process, as that mechanism responsible for anticipating the needs of the explainee in the form of unposed, implicit, archetypal questions, hence improving the user-centrality of the underlying explanatory process. More precisely, we hypothesise that given an arbitrary explanatory process, increasing its goal-orientedness and degree of illocution results in the generation of more usable (as per ISO 9241-210) explanations. We tested our hypotheses with a user-study involving more than 60 participants, on two XAI-based systems, one for credit approval (finance) and one for heart disease prediction (healthcare). The results showed that our proposed solution produced a statistically significant improvement (hence with a p-value lower than 0.05) on effectiveness. This, combined with a visible alignment between the increments in effectiveness and satisfaction, suggests that our understanding of illocution can be correct, giving evidence in favour of our theory.
Making Things Explainable vs Explaining: Requirements and Challenges under the GDPR
Oct 02, 2021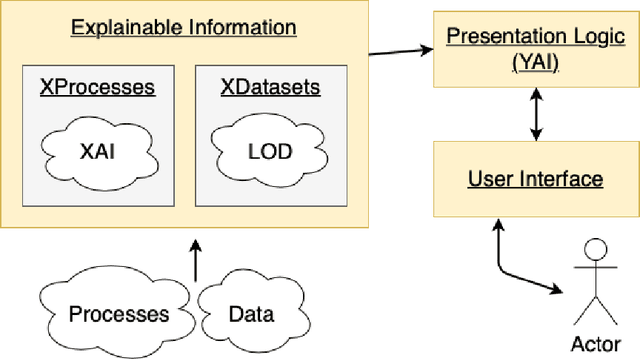

The European Union (EU) through the High-Level Expert Group on Artificial Intelligence (AI-HLEG) and the General Data Protection Regulation (GDPR) has recently posed an interesting challenge to the eXplainable AI (XAI) community, by demanding a more user-centred approach to explain Automated Decision-Making systems (ADMs). Looking at the relevant literature, XAI is currently focused on producing explainable software and explanations that generally follow an approach we could term One-Size-Fits-All, that is unable to meet a requirement of centring on user needs. One of the causes of this limit is the belief that making things explainable alone is enough to have pragmatic explanations. Thus, insisting on a clear separation between explainabilty (something that can be explained) and explanations, we point to explanatorY AI (YAI) as an alternative and more powerful approach to win the AI-HLEG challenge. YAI builds over XAI with the goal to collect and organize explainable information, articulating it into something we called user-centred explanatory discourses. Through the use of explanatory discourses/narratives we represent the problem of generating explanations for Automated Decision-Making systems (ADMs) into the identification of an appropriate path over an explanatory space, allowing explainees to interactively explore it and produce the explanation best suited to their needs.
An Objective Metric for Explainable AI: How and Why to Estimate the Degree of Explainability
Sep 11, 2021


Numerous government initiatives (e.g. the EU with GDPR) are coming to the conclusion that the increasing complexity of modern software systems must be contrasted with some Rights to Explanation and metrics for the Impact Assessment of these tools, that allow humans to understand and oversee the output of Automated Decision Making systems. Explainable AI was born as a pathway to allow humans to explore and understand the inner working of complex systems. But establishing what is an explanation and objectively evaluating explainability, are not trivial tasks. With this paper, we present a new model-agnostic metric to measure the Degree of eXplainability of correct information in an objective way, exploiting a specific model from Ordinary Language Philosophy called the Achinstein's Theory of Explanations. In order to understand whether this metric is actually behaving as explainability is expected to, we designed a few experiments and a user-study on two realistic AI-based systems for healthcare and finance, involving famous AI technology including Artificial Neural Networks and TreeSHAP. The results we obtained are very encouraging, suggesting that our proposed metric for measuring the Degree of eXplainability is robust on several scenarios and it can be eventually exploited for a lawful Impact Assessment of an Automated Decision Making system.
From Philosophy to Interfaces: an Explanatory Method and a Tool Inspired by Achinstein's Theory of Explanation
Sep 09, 2021
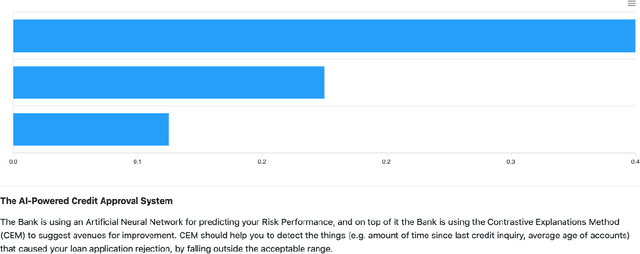


We propose a new method for explanations in Artificial Intelligence (AI) and a tool to test its expressive power within a user interface. In order to bridge the gap between philosophy and human-computer interfaces, we show a new approach for the generation of interactive explanations based on a sophisticated pipeline of AI algorithms for structuring natural language documents into knowledge graphs, answering questions effectively and satisfactorily. Among the mainstream philosophical theories of explanation we identified one that in our view is more easily applicable as a practical model for user-centric tools: Achinstein's Theory of Explanation. With this work we aim to prove that the theory proposed by Achinstein can be actually adapted for being implemented into a concrete software application, as an interactive process answering questions. To this end we found a way to handle the generic (archetypal) questions that implicitly characterise an explanatory processes as preliminary overviews rather than as answers to explicit questions, as commonly understood. To show the expressive power of this approach we designed and implemented a pipeline of AI algorithms for the generation of interactive explanations under the form of overviews, focusing on this aspect of explanations rather than on existing interfaces and presentation logic layers for question answering. We tested our hypothesis on a well-known XAI-powered credit approval system by IBM, comparing CEM, a static explanatory tool for post-hoc explanations, with an extension we developed adding interactive explanations based on our model. The results of the user study, involving more than 100 participants, showed that our proposed solution produced a statistically relevant improvement on effectiveness (U=931.0, p=0.036) over the baseline, thus giving evidence in favour of our theory.