 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuron-Anchored Rule Extraction for Large Language Models via Contrastive Hierarchical Ablation
May 04, 2026A key goal of explainable AI (XAI) is to express the decision logic of large language models (LLMs) in symbolic form and link it to internal mechanisms. Global rule-extraction methods typically learn symbolic surrogates without grounding rules in model circuitry, while mechanistic interpretability can connect behaviors to neuron sets but often depends on hand-crafted hypotheses and expensive neuron-level interventions. We introduce MechaRule, a pipeline that grounds rule extraction in LLM circuits by efficiently localizing sparse neurons called agonists, whose activation neutralization disrupts rule-related behaviors. MechaRule rests on two empirical observations. First, within a fixed baseline/flip regime, sparse agonist effects can be approximately monotone and saturating: a few dominant neuron activations can overtop weaker ones at coarse scales, while overlapping neurons flip many of the same examples. This motivates viewing localization as adaptive group testing driven by a regime-conditional strength predicate with confidence-guided conservative pruning, yielding Theta(k log(N/k) + k) interventions over N candidates when k << N neurons are agonists under the monotone-overtopping abstraction. Second, agonists emerge more reliably when ablations are verified through data splits aligned with close-to-faithful rule behavior; spectral splits remain a useful rule-free fallback, while unfaithful splits degrade localization. Empirically, overtopping appears mainly in learned, task-aligned regimes: on arithmetic and jailbreak tasks across Qwen2 and GPT-J, MechaRule recalls 96.8% of high-effect brute-force agonists in completed comparisons, and suppressing localized agonists reduces arithmetic accuracy and jailbreak success by up to 71.1% and 8.8%, respectively.
In-Context Symbolic Regression for Robustness-Improved Kolmogorov-Arnold Networks
Mar 16, 2026Symbolic regression aims to replace black-box predictors with concise analytical expressions that can be inspected and validated in scientific machine learning. Kolmogorov-Arnold Networks (KANs) are well suited to this goal because each connection between adjacent units (an "edge") is parametrised by a learnable univariate function that can, in principle, be replaced by a symbolic operator. In practice, however, symbolic extraction is a bottleneck: the standard KAN-to-symbol approach fits operators to each learned edge function in isolation, making the discrete choice sensitive to initialisation and non-convex parameter fitting, and ignoring how local substitutions interact through the full network. We study in-context symbolic regression for operator extraction in KANs, and present two complementary instantiations. Greedy in-context Symbolic Regression (GSR) performs greedy, in-context selection by choosing edge replacements according to end-to-end loss improvement after brief fine-tuning. Gated Matching Pursuit (GMP) amortises this in-context selection by training a differentiable gated operator layer that places an operator library behind sparse gates on each edge; after convergence, gates are discretised (optionally followed by a short in-context greedy refinement pass). We quantify robustness via one-factor-at-a-time (OFAT) hyper-parameter sweeps and assess both predictive error and qualitative consistency of recovered formulas. Across several experiments, greedy in-context symbolic regression achieves up to 99.8% reduction in median OFAT test MSE.
Explicit vs. Implicit Biographies: Evaluating and Adapting LLM Information Extraction on Wikidata-Derived Texts
Sep 18, 2025Text Implicitness has always been challenging in Natural Language Processing (NLP), with traditional methods relying on explicit statements to identify entities and their relationships. From the sentence "Zuhdi attends church every Sunday", the relationship between Zuhdi and Christianity is evident for a human reader, but it presents a challenge when it must be inferred automatically. Large language models (LLMs) have proven effective in NLP downstream tasks such as text comprehension and information extraction (IE). This study examines how textual implicitness affects IE tasks in pre-trained LLMs: LLaMA 2.3, DeepSeekV1, and Phi1.5. We generate two synthetic datasets of 10k implicit and explicit verbalization of biographic information to measure the impact on LLM performance and analyze whether fine-tuning implicit data improves their ability to generalize in implicit reasoning tasks. This research presents an experiment on the internal reasoning processes of LLMs in IE, particularly in dealing with implicit and explicit contexts. The results demonstrate that fine-tuning LLM models with LoRA (low-rank adaptation) improves their performance in extracting information from implicit texts, contributing to better model interpretability and reliability.
Can Global XAI Methods Reveal Injected Bias in LLMs? SHAP vs Rule Extraction vs RuleSHAP
May 16, 2025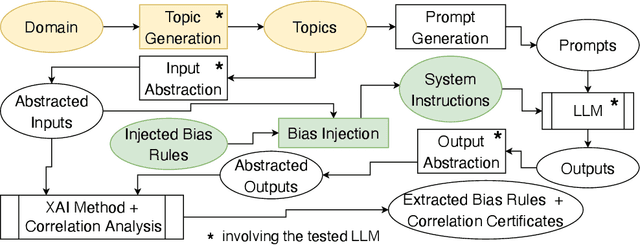
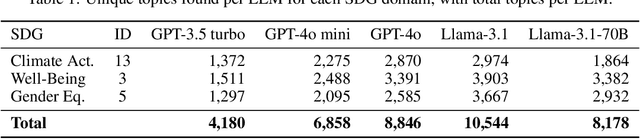
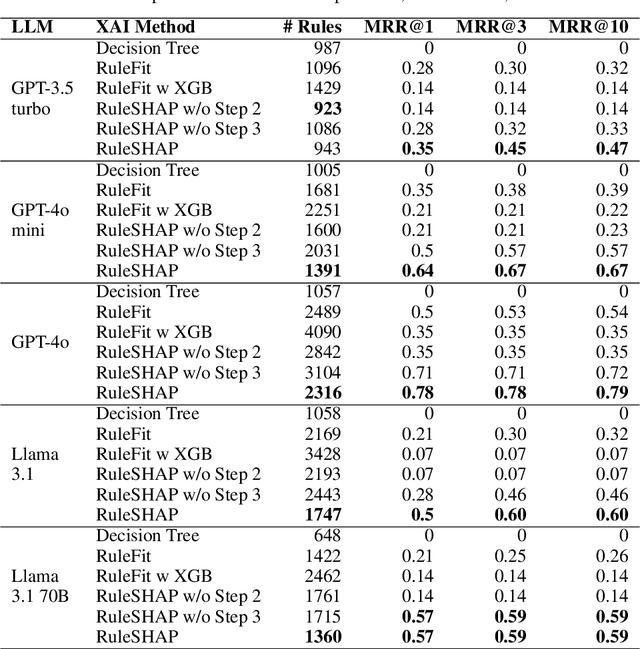
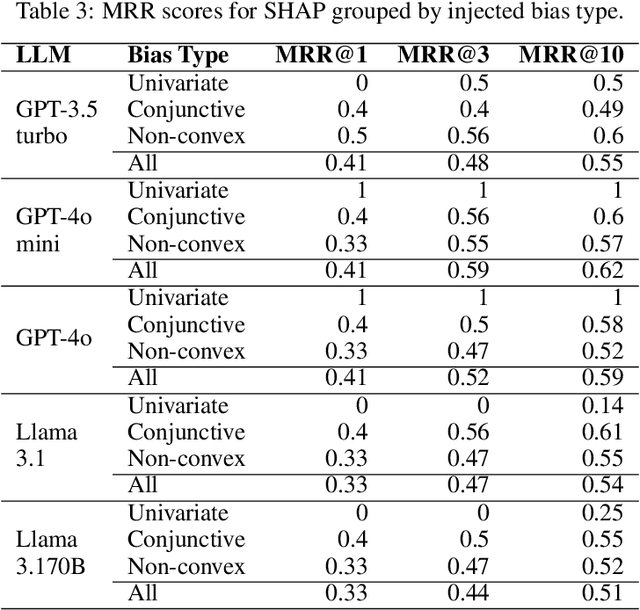
Generative AI systems can help spread information but also misinformation and biases, potentially undermining the UN Sustainable Development Goals (SDGs). Explainable AI (XAI) aims to reveal the inner workings of AI systems and expose misbehaviours or biases. However, current XAI tools, built for simpler models, struggle to handle the non-numerical nature of large language models (LLMs). This paper examines the effectiveness of global XAI methods, such as rule-extraction algorithms and SHAP, in detecting bias in LLMs. To do so, we first show a text-to-ordinal mapping strategy to convert non-numerical inputs/outputs into numerical features, enabling these tools to identify (some) misinformation-related biases in LLM-generated content. Then, we inject non-linear biases of varying complexity (univariate, conjunctive, and non-convex) into widespread LLMs like ChatGPT and Llama via system instructions, using global XAI methods to detect them. This way, we found that RuleFit struggles with conjunctive and non-convex biases, while SHAP can approximate conjunctive biases but cannot express them as actionable rules. Hence, we introduce RuleSHAP, a global rule extraction algorithm combining SHAP and RuleFit to detect more non-univariate biases, improving injected bias detection over RuleFit by +94% (MRR@1) on average.
Large Language Models for In-File Vulnerability Localization Can Be "Lost in the End"
Feb 09, 2025Recent advancements in artificial intelligence have enabled processing of larger inputs, leading everyday software developers to increasingly rely on chat-based large language models (LLMs) like GPT-3.5 and GPT-4 to detect vulnerabilities across entire files, not just within functions. This new development practice requires researchers to urgently investigate whether commonly used LLMs can effectively analyze large file-sized inputs, in order to provide timely insights for software developers and engineers about the pros and cons of this emerging technological trend. Hence, the goal of this paper is to evaluate the effectiveness of several state-of-the-art chat-based LLMs, including the GPT models, in detecting in-file vulnerabilities. We conducted a costly investigation into how the performance of LLMs varies based on vulnerability type, input size, and vulnerability location within the file. To give enough statistical power to our study, we could only focus on the three most common (as well as dangerous) vulnerabilities: XSS, SQL injection, and path traversal. Our findings indicate that the effectiveness of LLMs in detecting these vulnerabilities is strongly influenced by both the location of the vulnerability and the overall size of the input. Specifically, regardless of the vulnerability type, LLMs tend to significantly (p < .05) underperform when detecting vulnerabilities located toward the end of larger files, a pattern we call the 'lost-in-the-end' effect. Finally, to further support software developers and practitioners, we also explored the optimal input size for these LLMs and presented a simple strategy for identifying it, which can be applied to other models and vulnerability types. Eventually, we show how adjusting the input size can lead to significant improvements in LLM-based vulnerability detection, with an average recall increase of over 37% across all models.
Aligning XAI with EU Regulations for Smart Biomedical Devices: A Methodology for Compliance Analysis
Aug 27, 2024Significant investment and development have gone into integrating Artificial Intelligence (AI) in medical and healthcare applications, leading to advanced control systems in medical technology. However, the opacity of AI systems raises concerns about essential characteristics needed in such sensitive applications, like transparency and trustworthiness. Our study addresses these concerns by investigating a process for selecting the most adequate Explainable AI (XAI) methods to comply with the explanation requirements of key EU regulations in the context of smart bioelectronics for medical devices. The adopted methodology starts with categorising smart devices by their control mechanisms (open-loop, closed-loop, and semi-closed-loop systems) and delving into their technology. Then, we analyse these regulations to define their explainability requirements for the various devices and related goals. Simultaneously, we classify XAI methods by their explanatory objectives. This allows for matching legal explainability requirements with XAI explanatory goals and determining the suitable XAI algorithms for achieving them. Our findings provide a nuanced understanding of which XAI algorithms align better with EU regulations for different types of medical devices. We demonstrate this through practical case studies on different neural implants, from chronic disease management to advanced prosthetics. This study fills a crucial gap in aligning XAI applications in bioelectronics with stringent provisions of EU regulations. It provides a practical framework for developers and researchers, ensuring their AI innovations advance healthcare technology and adhere to legal and ethical standards.
An Empirical Study on Compliance with Ranking Transparency in the Software Documentation of EU Online Platforms
Dec 22, 2023Compliance with the European Union's Platform-to-Business (P2B) Regulation is challenging for online platforms, and assessing their compliance can be difficult for public authorities. This is partly due to the lack of automated tools for assessing the information (e.g., software documentation) platforms provide concerning ranking transparency. Our study tackles this issue in two ways. First, we empirically evaluate the compliance of six major platforms (Amazon, Bing, Booking, Google, Tripadvisor, and Yahoo), revealing substantial differences in their documentation. Second, we introduce and test automated compliance assessment tools based on ChatGPT and information retrieval technology. These tools are evaluated against human judgments, showing promising results as reliable proxies for compliance assessments. Our findings could help enhance regulatory compliance and align with the United Nations Sustainable Development Goal 10.3, which seeks to reduce inequality, including business disparities, on these platforms.
A Survey on Methods and Metrics for the Assessment of Explainability under the Proposed AI Act
Oct 21, 2021
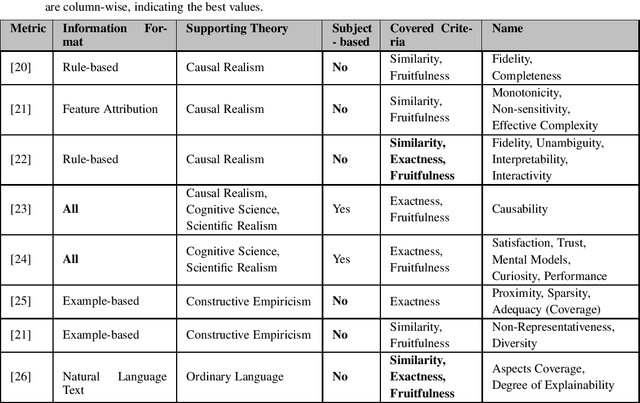
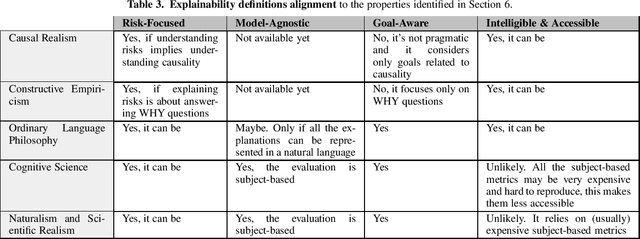
This study discusses the interplay between metrics used to measure the explainability of the AI systems and the proposed EU Artificial Intelligence Act. A standardisation process is ongoing: several entities (e.g. ISO) and scholars are discussing how to design systems that are compliant with the forthcoming Act and explainability metrics play a significant role. This study identifies the requirements that such a metric should possess to ease compliance with the AI Act. It does so according to an interdisciplinary approach, i.e. by departing from the philosophical concept of explainability and discussing some metrics proposed by scholars and standardisation entities through the lenses of the explainability obligations set by the proposed AI Act. Our analysis proposes that metrics to measure the kind of explainability endorsed by the proposed AI Act shall be risk-focused, model-agnostic, goal-aware, intelligible & accessible. This is why we discuss the extent to which these requirements are met by the metrics currently under discussion.
Generating User-Centred Explanations via Illocutionary Question Answering: From Philosophy to Interfaces
Oct 02, 2021



We propose a new method for generating explanations with Artificial Intelligence (AI) and a tool to test its expressive power within a user interface. In order to bridge the gap between philosophy and human-computer interfaces, we show a new approach for the generation of interactive explanations based on a sophisticated pipeline of AI algorithms for structuring natural language documents into knowledge graphs, answering questions effectively and satisfactorily. With this work we aim to prove that the philosophical theory of explanations presented by Achinstein can be actually adapted for being implemented into a concrete software application, as an interactive and illocutionary process of answering questions. Specifically, our contribution is an approach to frame illocution in a computer-friendly way, to achieve user-centrality with statistical question answering. In fact, we frame illocution, in an explanatory process, as that mechanism responsible for anticipating the needs of the explainee in the form of unposed, implicit, archetypal questions, hence improving the user-centrality of the underlying explanatory process. More precisely, we hypothesise that given an arbitrary explanatory process, increasing its goal-orientedness and degree of illocution results in the generation of more usable (as per ISO 9241-210) explanations. We tested our hypotheses with a user-study involving more than 60 participants, on two XAI-based systems, one for credit approval (finance) and one for heart disease prediction (healthcare). The results showed that our proposed solution produced a statistically significant improvement (hence with a p-value lower than 0.05) on effectiveness. This, combined with a visible alignment between the increments in effectiveness and satisfaction, suggests that our understanding of illocution can be correct, giving evidence in favour of our theory.
Making Things Explainable vs Explaining: Requirements and Challenges under the GDPR
Oct 02, 2021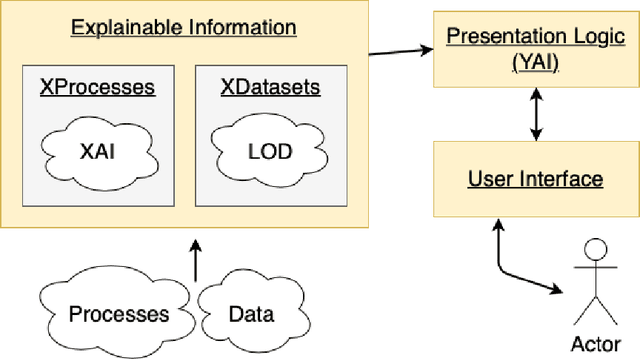

The European Union (EU) through the High-Level Expert Group on Artificial Intelligence (AI-HLEG) and the General Data Protection Regulation (GDPR) has recently posed an interesting challenge to the eXplainable AI (XAI) community, by demanding a more user-centred approach to explain Automated Decision-Making systems (ADMs). Looking at the relevant literature, XAI is currently focused on producing explainable software and explanations that generally follow an approach we could term One-Size-Fits-All, that is unable to meet a requirement of centring on user needs. One of the causes of this limit is the belief that making things explainable alone is enough to have pragmatic explanations. Thus, insisting on a clear separation between explainabilty (something that can be explained) and explanations, we point to explanatorY AI (YAI) as an alternative and more powerful approach to win the AI-HLEG challenge. YAI builds over XAI with the goal to collect and organize explainable information, articulating it into something we called user-centred explanatory discourses. Through the use of explanatory discourses/narratives we represent the problem of generating explanations for Automated Decision-Making systems (ADMs) into the identification of an appropriate path over an explanatory space, allowing explainees to interactively explore it and produce the explanation best suited to their needs.