 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Masking: Deep Q-Learning for Context Encoding in Medical Image Analysis
Apr 04, 2022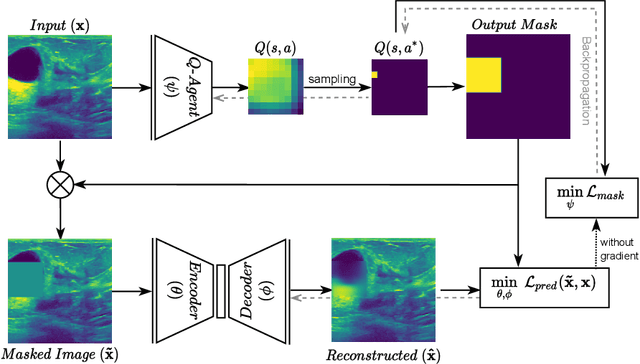

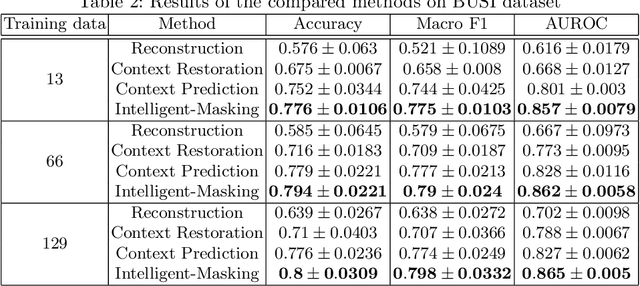
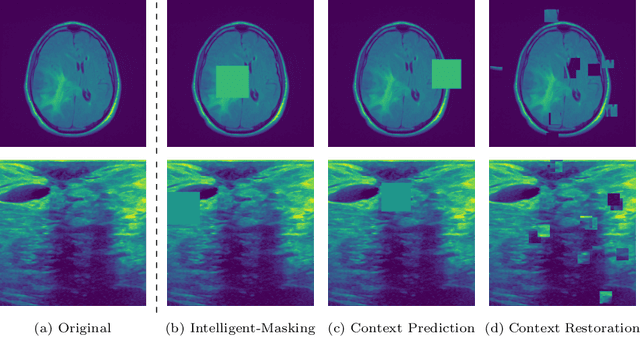
The need for a large amount of labeled data in the supervised setting has led recent studies to utilize self-supervised learning to pre-train deep neural networks using unlabeled data. Many self-supervised training strategies have been investigated especially for medical datasets to leverage the information available in the much fewer unlabeled data. One of the fundamental strategies in image-based self-supervision is context prediction. In this approach, a model is trained to reconstruct the contents of an arbitrary missing region of an image based on its surroundings. However, the existing methods adopt a random and blind masking approach by focusing uniformly on all regions of the images. This approach results in a lot of unnecessary network updates that cause the model to forget the rich extracted features. In this work, we develop a novel self-supervised approach that occludes targeted regions to improve the pre-training procedure. To this end, we propose a reinforcement learning-based agent which learns to intelligently mask input images through deep Q-learning. We show that training the agent against the prediction model can significantly improve the semantic features extracted for downstream classification tasks. We perform our experiments on two public datasets for diagnosing breast cancer in the ultrasound images and detecting lower-grade glioma with MR images. In our experiments, we show that our novel masking strategy advances the learned features according to the performance on the classification task in terms of accuracy, macro F1, and AUROC.
GKD: Semi-supervised Graph Knowledge Distillation for Graph-Independent Inference
Apr 08, 2021



The increased amount of multi-modal medical data has opened the opportunities to simultaneously process various modalities such as imaging and non-imaging data to gain a comprehensive insight into the disease prediction domain. Recent studies using Graph Convolutional Networks (GCNs) provide novel semi-supervised approaches for integrating heterogeneous modalities while investigating the patients' associations for disease prediction. However, when the meta-data used for graph construction is not available at inference time (e.g., coming from a distinct population), the conventional methods exhibit poor performance. To address this issue, we propose a novel semi-supervised approach named GKD based on knowledge distillation. We train a teacher component that employs the label-propagation algorithm besides a deep neural network to benefit from the graph and non-graph modalities only in the training phase. The teacher component embeds all the available information into the soft pseudo-labels. The soft pseudo-labels are then used to train a deep student network for disease prediction of unseen test data for which the graph modality is unavailable. We perform our experiments on two public datasets for diagnosing Autism spectrum disorder, and Alzheimer's disease, along with a thorough analysis on synthetic multi-modal datasets. According to these experiments, GKD outperforms the previous graph-based deep learning methods in terms of accuracy, AUC, and Macro F1.