 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Outlier Detection based on Incremental Decision Trees
Mar 09, 2018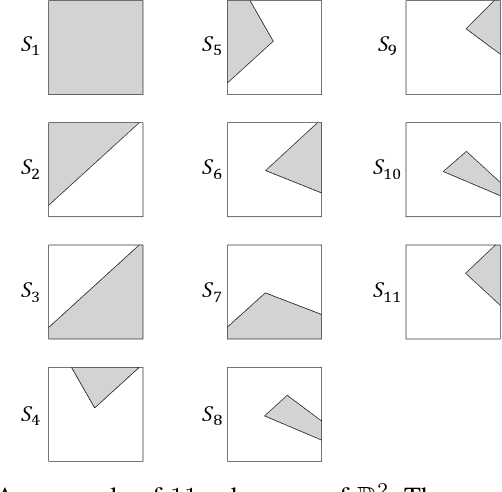

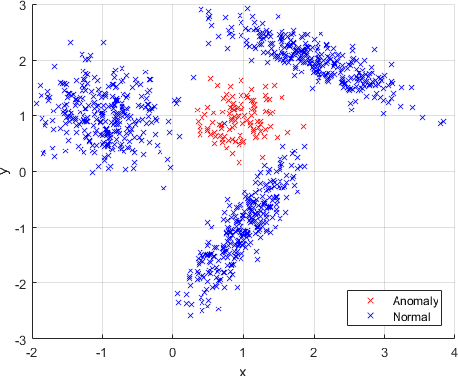

We introduce an online outlier detection algorithm to detect outliers in a sequentially observed data stream. For this purpose, we use a two-stage filtering and hedging approach. In the first stage, we construct a multi-modal probability density function to model the normal samples. In the second stage, given a new observation, we label it as an anomaly if the value of aforementioned density function is below a specified threshold at the newly observed point. In order to construct our multi-modal density function, we use an incremental decision tree to construct a set of subspaces of the observation space. We train a single component density function of the exponential family using the observations, which fall inside each subspace represented on the tree. These single component density functions are then adaptively combined to produce our multi-modal density function, which is shown to achieve the performance of the best convex combination of the density functions defined on the subspaces. As we observe more samples, our tree grows and produces more subspaces. As a result, our modeling power increases in time, while mitigating overfitting issues. In order to choose our threshold level to label the observations, we use an adaptive thresholding scheme. We show that our adaptive threshold level achieves the performance of the optimal pre-fixed threshold level, which knows the observation labels in hindsight. Our algorithm provides significant performance improvements over the state of the art in our wide set of experiments involving both synthetic as well as real data.
An Asymptotically Optimal Contextual Bandit Algorithm Using Hierarchical Structures
Dec 07, 2017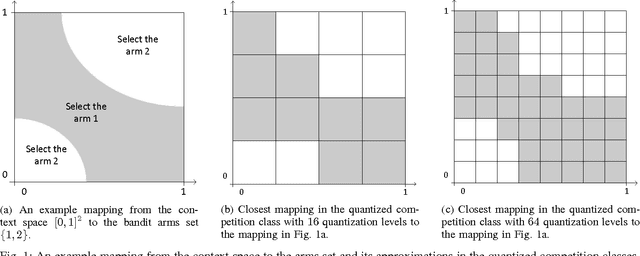

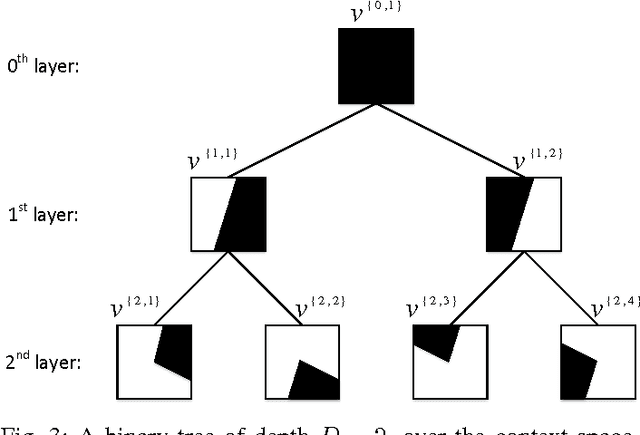
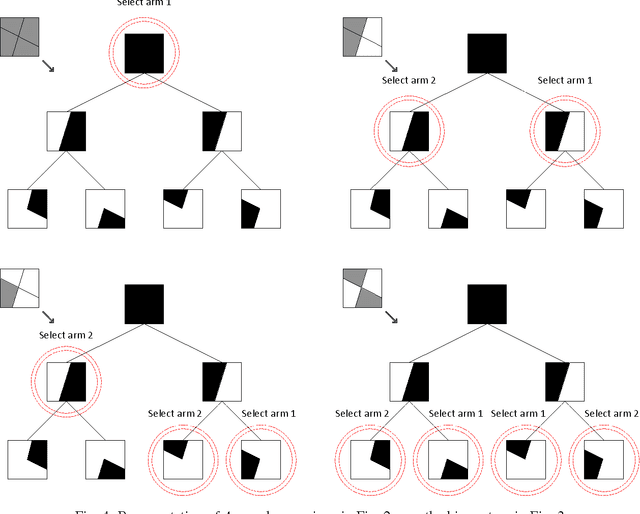
We propose online algorithms for sequential learning in the contextual multi-armed bandit setting. Our approach is to partition the context space and then optimally combine all of the possible mappings between the partition regions and the set of bandit arms in a data driven manner. We show that in our approach, the best mapping is able to approximate the best arm selection policy to any desired degree under mild Lipschitz conditions. Therefore, we design our algorithms based on the optimal adaptive combination and asymptotically achieve the performance of the best mapping as well as the best arm selection policy. This optimality is also guaranteed to hold even in adversarial environments since we do not rely on any statistical assumptions regarding the contexts or the loss of the bandit arms. Moreover, we design efficient implementations for our algorithms in various hierarchical partitioning structures such as lexicographical or arbitrary position splitting and binary trees (and several other partitioning examples). For instance, in the case of binary tree partitioning, the computational complexity is only log-linear in the number of regions in the finest partition. In conclusion, we provide significant performance improvements by introducing upper bounds (w.r.t. the best arm selection policy) that are mathematically proven to vanish in the average loss per round sense at a faster rate compared to the state-of-the-art. Our experimental work extensively covers various scenarios ranging from bandit settings to multi-class classification with real and synthetic data. In these experiments, we show that our algorithms are highly superior over the state-of-the-art techniques while maintaining the introduced mathematical guarantees and a computationally decent scalability.