 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Outlier Detection based on Incremental Decision Trees
Paper and Code
Mar 09, 2018

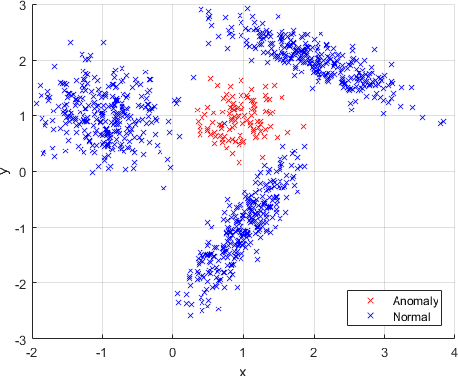

We introduce an online outlier detection algorithm to detect outliers in a sequentially observed data stream. For this purpose, we use a two-stage filtering and hedging approach. In the first stage, we construct a multi-modal probability density function to model the normal samples. In the second stage, given a new observation, we label it as an anomaly if the value of aforementioned density function is below a specified threshold at the newly observed point. In order to construct our multi-modal density function, we use an incremental decision tree to construct a set of subspaces of the observation space. We train a single component density function of the exponential family using the observations, which fall inside each subspace represented on the tree. These single component density functions are then adaptively combined to produce our multi-modal density function, which is shown to achieve the performance of the best convex combination of the density functions defined on the subspaces. As we observe more samples, our tree grows and produces more subspaces. As a result, our modeling power increases in time, while mitigating overfitting issues. In order to choose our threshold level to label the observations, we use an adaptive thresholding scheme. We show that our adaptive threshold level achieves the performance of the optimal pre-fixed threshold level, which knows the observation labels in hindsight. Our algorithm provides significant performance improvements over the state of the art in our wide set of experiments involving both synthetic as well as real data.