 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Prediction using Knowledge Graphs for Contextual Malware Threat Intelligence
Feb 18, 2021
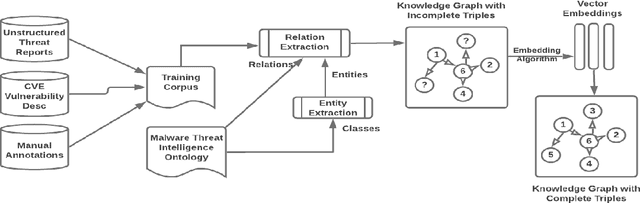
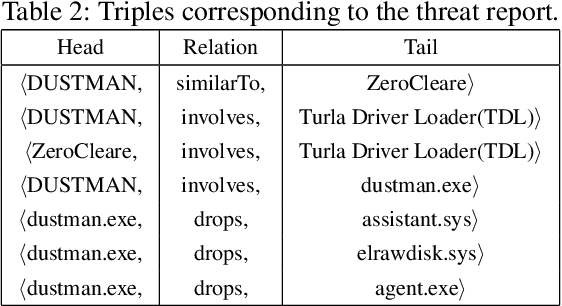

Large amounts of threat intelligence information about mal-ware attacks are available in disparate, typically unstructured, formats. Knowledge graphs can capture this information and its context using RDF triples represented by entities and relations. Sparse or inaccurate threat information, however, leads to challenges such as incomplete or erroneous triples. Named entity recognition (NER) and relation extraction (RE) models used to populate the knowledge graph cannot fully guaran-tee accurate information retrieval, further exacerbating this problem. This paper proposes an end-to-end approach to generate a Malware Knowledge Graph called MalKG, the first open-source automated knowledge graph for malware threat intelligence. MalKG dataset called MT40K1 contains approximately 40,000 triples generated from 27,354 unique entities and 34 relations. We demonstrate the application of MalKGin predicting missing malware threat intelligence information in the knowledge graph. For ground truth, we manually curate a knowledge graph called MT3K, with 3,027 triples generated from 5,741 unique entities and 22 relations. For entity prediction via a state-of-the-art entity prediction model(TuckER), our approach achieves 80.4 for the hits@10 metric (predicts the top 10 options for missing entities in the knowledge graph), and 0.75 for the MRR (mean reciprocal rank). We also propose a framework to automate the extraction of thousands of entities and relations into RDF triples, both manually and automatically, at the sentence level from1,100 malware threat intelligence reports and from the com-mon vulnerabilities and exposures (CVE) database.
Multiple Instance Learning by Discriminative Training of Markov Networks
Sep 26, 2013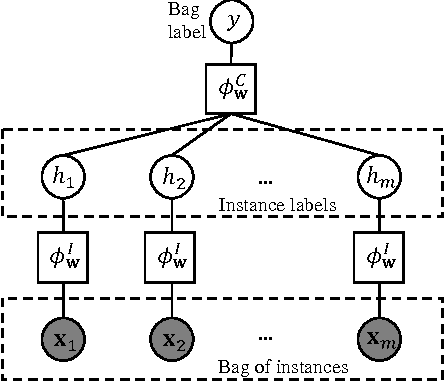
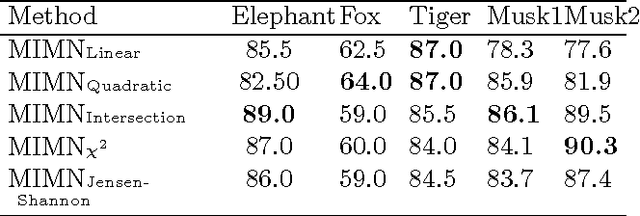
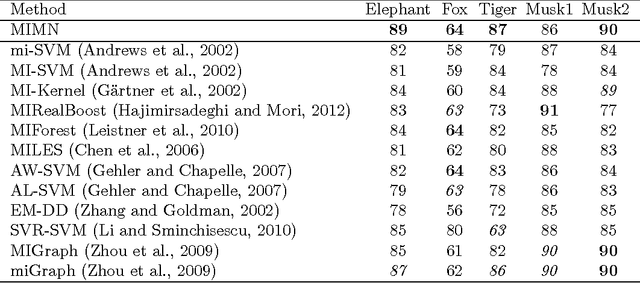
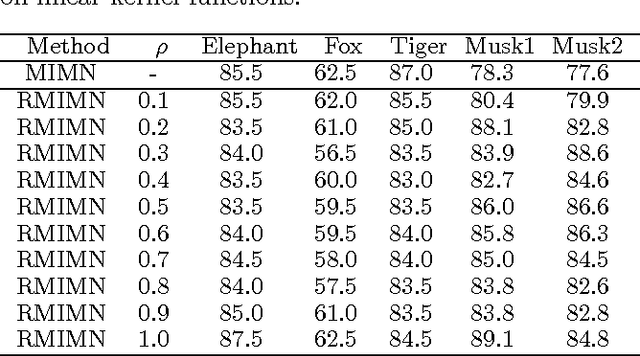
We introduce a graphical framework for multiple instance learning (MIL) based on Markov networks. This framework can be used to model the traditional MIL definition as well as more general MIL definitions. Different levels of ambiguity -- the portion of positive instances in a bag -- can be explored in weakly supervised data. To train these models, we propose a discriminative max-margin learning algorithm leveraging efficient inference for cardinality-based cliques. The efficacy of the proposed framework is evaluated on a variety of data sets. Experimental results verify that encoding or learning the degree of ambiguity can improve classification performance.