 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cost-Aware Approach to Adversarial Robustness in Neural Networks
Sep 11, 2024



Considering the growing prominence of production-level AI and the threat of adversarial attacks that can evade a model at run-time, evaluating the robustness of models to these evasion attacks is of critical importance. Additionally, testing model changes likely means deploying the models to (e.g. a car or a medical imaging device), or a drone to see how it affects performance, making un-tested changes a public problem that reduces development speed, increases cost of development, and makes it difficult (if not impossible) to parse cause from effect. In this work, we used survival analysis as a cloud-native, time-efficient and precise method for predicting model performance in the presence of adversarial noise. For neural networks in particular, the relationships between the learning rate, batch size, training time, convergence time, and deployment cost are highly complex, so researchers generally rely on benchmark datasets to assess the ability of a model to generalize beyond the training data. To address this, we propose using accelerated failure time models to measure the effect of hardware choice, batch size, number of epochs, and test-set accuracy by using adversarial attacks to induce failures on a reference model architecture before deploying the model to the real world. We evaluate several GPU types and use the Tree Parzen Estimator to maximize model robustness and minimize model run-time simultaneously. This provides a way to evaluate the model and optimise it in a single step, while simultaneously allowing us to model the effect of model parameters on training time, prediction time, and accuracy. Using this technique, we demonstrate that newer, more-powerful hardware does decrease the training time, but with a monetary and power cost that far outpaces the marginal gains in accuracy.
A Systematic Approach to Robustness Modelling for Deep Convolutional Neural Networks
Jan 24, 2024
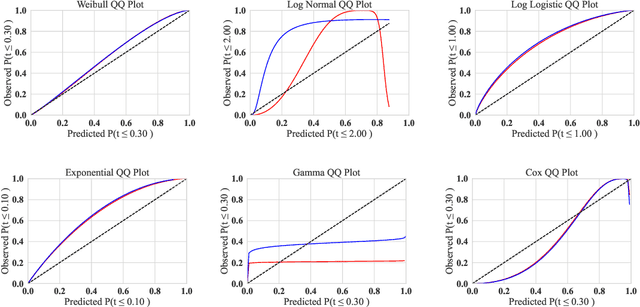


Convolutional neural networks have shown to be widely applicable to a large number of fields when large amounts of labelled data are available. The recent trend has been to use models with increasingly larger sets of tunable parameters to increase model accuracy, reduce model loss, or create more adversarially robust models -- goals that are often at odds with one another. In particular, recent theoretical work raises questions about the ability for even larger models to generalize to data outside of the controlled train and test sets. As such, we examine the role of the number of hidden layers in the ResNet model, demonstrated on the MNIST, CIFAR10, CIFAR100 datasets. We test a variety of parameters including the size of the model, the floating point precision, and the noise level of both the training data and the model output. To encapsulate the model's predictive power and computational cost, we provide a method that uses induced failures to model the probability of failure as a function of time and relate that to a novel metric that allows us to quickly determine whether or not the cost of training a model outweighs the cost of attacking it. Using this approach, we are able to approximate the expected failure rate using a small number of specially crafted samples rather than increasingly larger benchmark datasets. We demonstrate the efficacy of this technique on both the MNIST and CIFAR10 datasets using 8-, 16-, 32-, and 64-bit floating-point numbers, various data pre-processing techniques, and several attacks on five configurations of the ResNet model. Then, using empirical measurements, we examine the various trade-offs between cost, robustness, latency, and reliability to find that larger models do not significantly aid in adversarial robustness despite costing significantly more to train.
Web Document Categorization Using Naive Bayes Classifier and Latent Semantic Analysis
Jun 02, 2020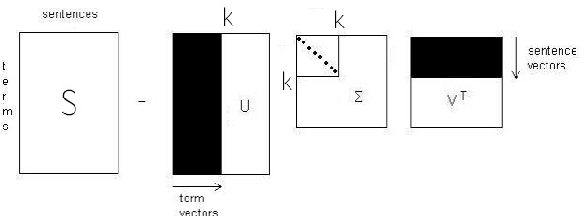


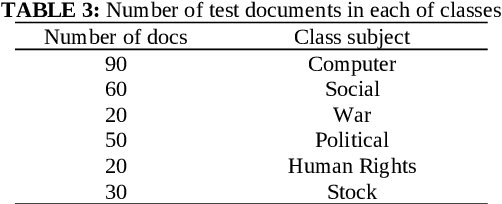
A rapid growth of web documents due to heavy use of World Wide Web necessitates efficient techniques to efficiently classify the document on the web. It is thus produced High volumes of data per second with high diversity. Automatically classification of these growing amounts of web document is One of the biggest challenges facing us today. Probabilistic classification algorithms such as Naive Bayes have become commonly used for web document classification. This problem is mainly because of the irrelatively high classification accuracy on plenty application areas as well as their lack of support to handle high dimensional and sparse data which is the exclusive characteristics of textual data representation. also it is common to Lack of attention and support the semantic relation between words using traditional feature selection method When dealing with the big data and large-scale web documents. In order to solve the problem, we proposed a method for web document classification that uses LSA to increase similarity of documents under the same class and improve the classification precision. Using this approach, we designed a faster and much accurate classifier for Web Documents. Experimental results have shown that using the mentioned preprocessing can improve accuracy and speed of Naive Bayes availably, the precision and recall metrics have indicated the improvement.