 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Document Categorization Using Naive Bayes Classifier and Latent Semantic Analysis
Paper and Code
Jun 02, 2020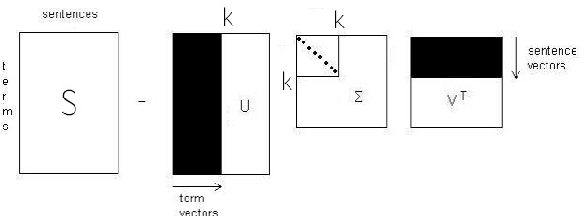


A rapid growth of web documents due to heavy use of World Wide Web necessitates efficient techniques to efficiently classify the document on the web. It is thus produced High volumes of data per second with high diversity. Automatically classification of these growing amounts of web document is One of the biggest challenges facing us today. Probabilistic classification algorithms such as Naive Bayes have become commonly used for web document classification. This problem is mainly because of the irrelatively high classification accuracy on plenty application areas as well as their lack of support to handle high dimensional and sparse data which is the exclusive characteristics of textual data representation. also it is common to Lack of attention and support the semantic relation between words using traditional feature selection method When dealing with the big data and large-scale web documents. In order to solve the problem, we proposed a method for web document classification that uses LSA to increase similarity of documents under the same class and improve the classification precision. Using this approach, we designed a faster and much accurate classifier for Web Documents. Experimental results have shown that using the mentioned preprocessing can improve accuracy and speed of Naive Bayes availably, the precision and recall metrics have indicated the improvement.