 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Approach to Robustness Modelling for Deep Convolutional Neural Networks
Paper and Code

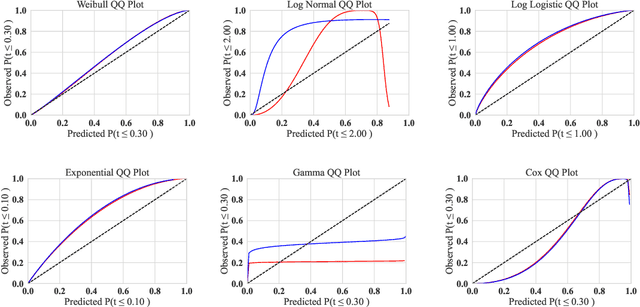


Convolutional neural networks have shown to be widely applicable to a large number of fields when large amounts of labelled data are available. The recent trend has been to use models with increasingly larger sets of tunable parameters to increase model accuracy, reduce model loss, or create more adversarially robust models -- goals that are often at odds with one another. In particular, recent theoretical work raises questions about the ability for even larger models to generalize to data outside of the controlled train and test sets. As such, we examine the role of the number of hidden layers in the ResNet model, demonstrated on the MNIST, CIFAR10, CIFAR100 datasets. We test a variety of parameters including the size of the model, the floating point precision, and the noise level of both the training data and the model output. To encapsulate the model's predictive power and computational cost, we provide a method that uses induced failures to model the probability of failure as a function of time and relate that to a novel metric that allows us to quickly determine whether or not the cost of training a model outweighs the cost of attacking it. Using this approach, we are able to approximate the expected failure rate using a small number of specially crafted samples rather than increasingly larger benchmark datasets. We demonstrate the efficacy of this technique on both the MNIST and CIFAR10 datasets using 8-, 16-, 32-, and 64-bit floating-point numbers, various data pre-processing techniques, and several attacks on five configurations of the ResNet model. Then, using empirical measurements, we examine the various trade-offs between cost, robustness, latency, and reliability to find that larger models do not significantly aid in adversarial robustness despite costing significantly more to train.