 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Commonsense Validation and Reasoning with Large Language Models: An Evaluation on SemEval-2020 Task 4 Dataset
Feb 19, 2025
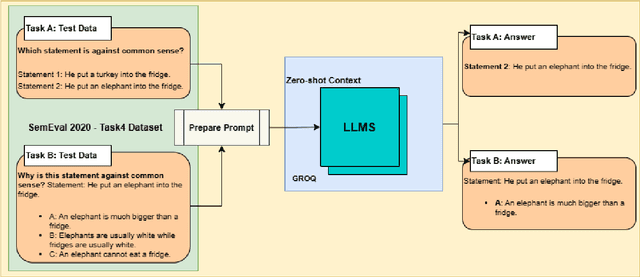
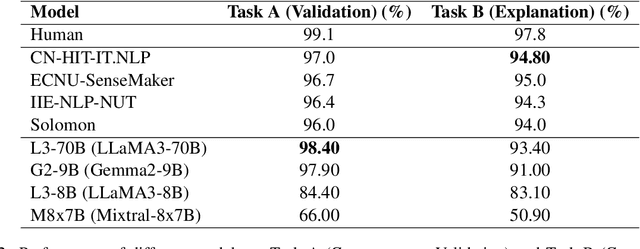

This study evaluates the performance of Large Language Models (LLMs) on SemEval-2020 Task 4 dataset, focusing on commonsense validation and explanation. Our methodology involves evaluating multiple LLMs, including LLaMA3-70B, Gemma2-9B, and Mixtral-8x7B, using zero-shot prompting techniques. The models are tested on two tasks: Task A (Commonsense Validation), where models determine whether a statement aligns with commonsense knowledge, and Task B (Commonsense Explanation), where models identify the reasoning behind implausible statements. Performance is assessed based on accuracy, and results are compared to fine-tuned transformer-based models. The results indicate that larger models outperform previous models and perform closely to human evaluation for Task A, with LLaMA3-70B achieving the highest accuracy of 98.40% in Task A whereas, lagging behind previous models with 93.40% in Task B. However, while models effectively identify implausible statements, they face challenges in selecting the most relevant explanation, highlighting limitations in causal and inferential reasoning.
IntegrityAI at GenAI Detection Task 2: Detecting Machine-Generated Academic Essays in English and Arabic Using ELECTRA and Stylometry
Jan 07, 2025



Recent research has investigated the problem of detecting machine-generated essays for academic purposes. To address this challenge, this research utilizes pre-trained, transformer-based models fine-tuned on Arabic and English academic essays with stylometric features. Custom models based on ELECTRA for English and AraELECTRA for Arabic were trained and evaluated using a benchmark dataset. Proposed models achieved excellent results with an F1-score of 99.7%, ranking 2nd among of 26 teams in the English subtask, and 98.4%, finishing 1st out of 23 teams in the Arabic one.
ChatGPT and Beyond: The Generative AI Revolution in Education
Nov 26, 2023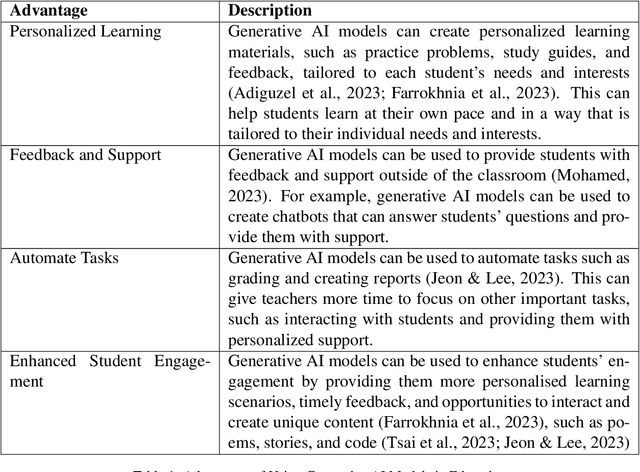
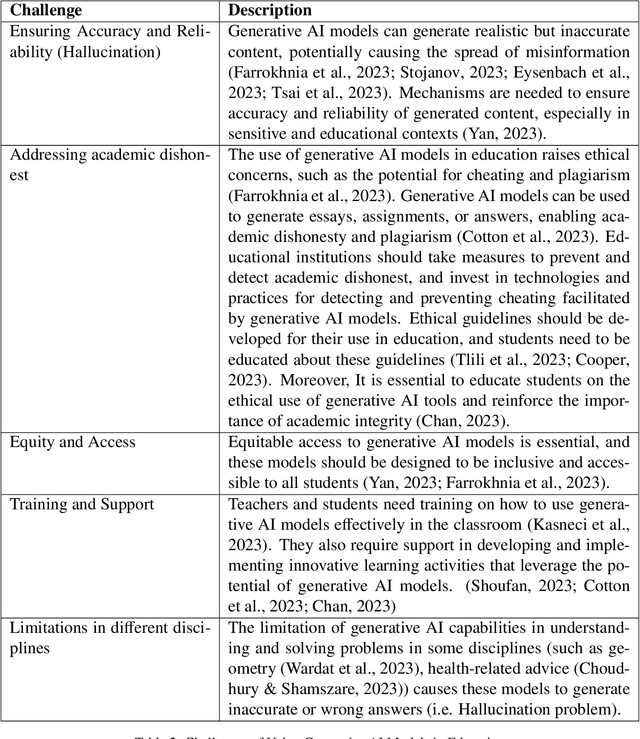
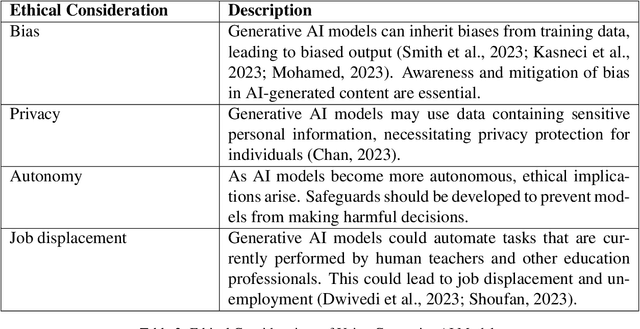

The wide adoption and usage of generative artificial intelligence (AI) models, particularly ChatGPT, has sparked a surge in research exploring their potential applications in the educational landscape. This survey examines academic literature published between November, 2022, and July, 2023, specifically targeting high-impact research from Scopus-indexed Q1 and Q2 journals. This survey delves into the practical applications and implications of generative AI models across a diverse range of educational contexts. Through a comprehensive and rigorous evaluation of recent academic literature, this survey seeks to illuminate the evolving role of generative AI models, particularly ChatGPT, in education. By shedding light on the potential benefits, challenges, and emerging trends in this dynamic field, the survey endeavors to contribute to the understanding of the nexus between artificial intelligence and education. The findings of this review will empower educators, researchers, and policymakers to make informed decisions about the integration of AI technologies into learning environments.
Healthcare Knowledge Graph Construction: State-of-the-art, open issues, and opportunities
Jul 08, 2022
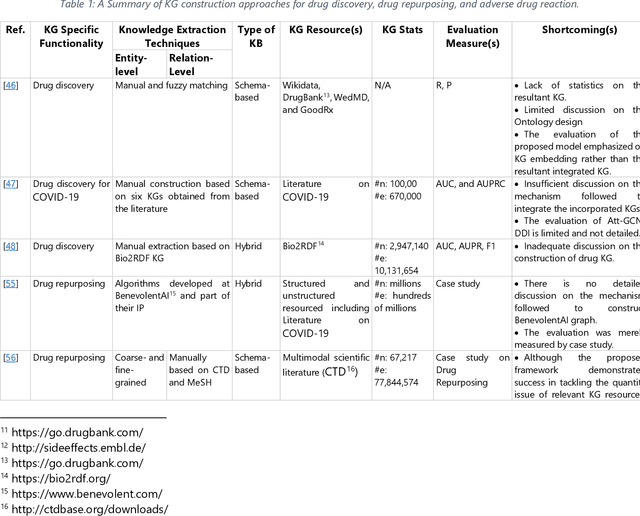
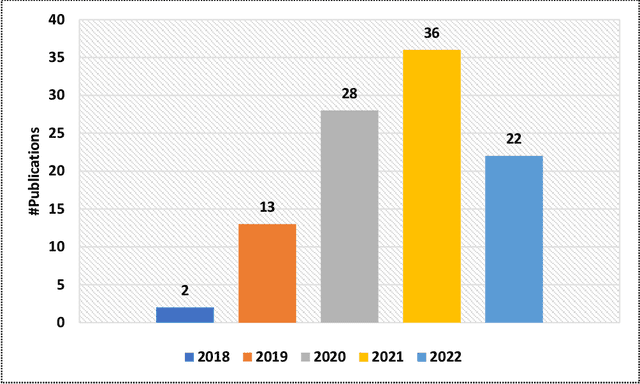
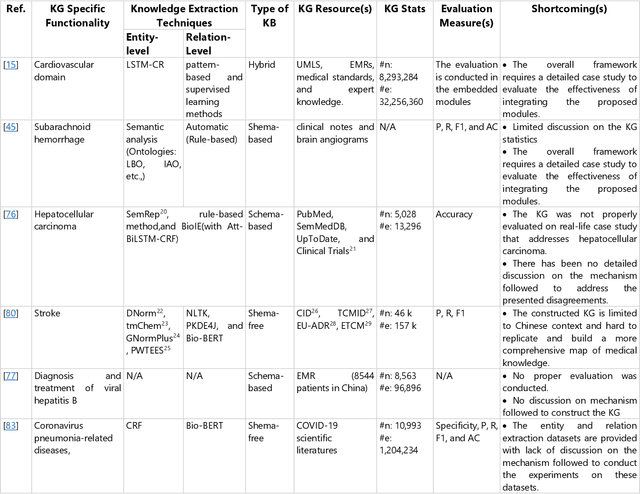
The incorporation of data analytics in the healthcare industry has made significant progress, driven by the demand for efficient and effective big data analytics solutions. Knowledge graphs (KGs) have proven utility in this arena and are rooted in a number of healthcare applications to furnish better data representation and knowledge inference. However, in conjunction with a lack of a representative KG construction taxonomy, several existing approaches in this designated domain are inadequate and inferior. This paper is the first to provide a comprehensive taxonomy and a bird's eye view of healthcare KG construction. Additionally, a thorough examination of the current state-of-the-art techniques drawn from academic works relevant to various healthcare contexts is carried out. These techniques are critically evaluated in terms of methods used for knowledge extraction, types of the knowledge base and sources, and the incorporated evaluation protocols. Finally, several research findings and existing issues in the literature are reported and discussed, opening horizons for future research in this vibrant area.
A Benchmark Arabic Dataset for Commonsense Explanation
Dec 18, 2020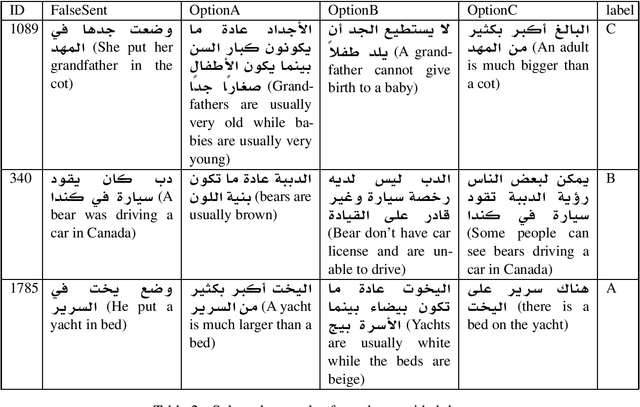
Language comprehension and commonsense knowledge validation by machines are challenging tasks that are still under researched and evaluated for Arabic text. In this paper, we present a benchmark Arabic dataset for commonsense explanation. The dataset consists of Arabic sentences that does not make sense along with three choices to select among them the one that explains why the sentence is false. Furthermore, this paper presents baseline results to assist and encourage the future evaluation of research in this field. The dataset is distributed under the Creative Commons CC-BY-SA 4.0 license and can be found on GitHub
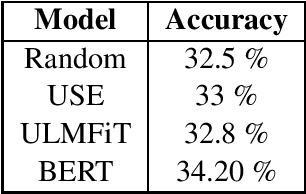
Is this sentence valid? An Arabic Dataset for Commonsense Validation
Aug 25, 2020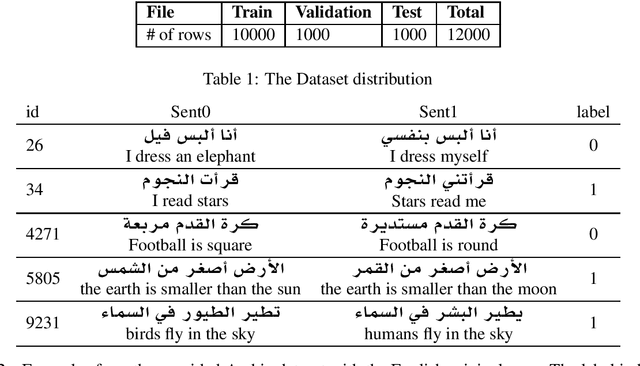
The commonsense understanding and validation remains a challenging task in the field of natural language understanding. Therefore, several research papers have been published that studied the capability of proposed systems to evaluate the models ability to validate commonsense in text. In this paper, we present a benchmark Arabic dataset for commonsense understanding and validation as well as a baseline research and models trained using the same dataset. To the best of our knowledge, this dataset is considered as the first in the field of Arabic text commonsense validation. The dataset is distributed under the Creative Commons BY-SA 4.0 license and can be found on GitHub.
KEIS@JUST at SemEval-2020 Task 12: Identifying Multilingual Offensive Tweets Using Weighted Ensemble and Fine-Tuned BERT
May 15, 2020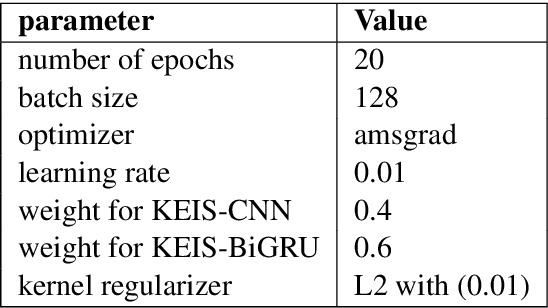
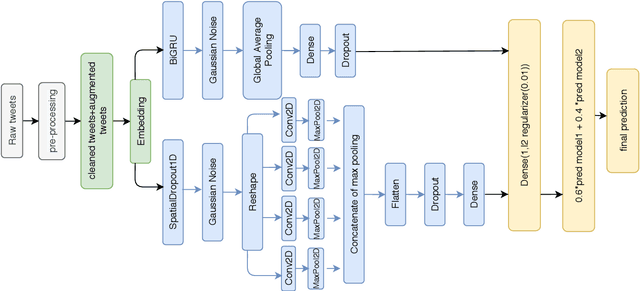
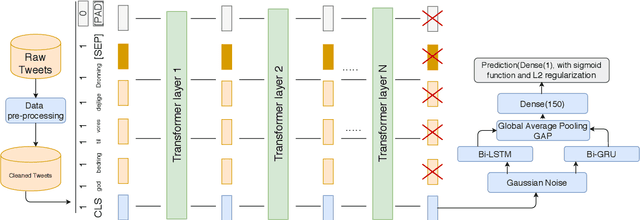
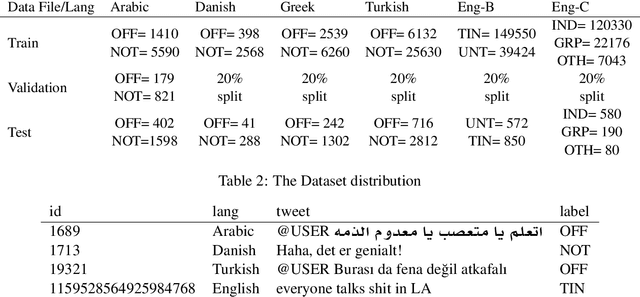
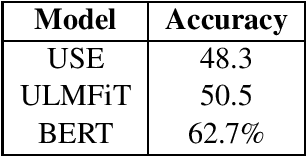
This research presents our team KEIS@JUST participation at SemEval-2020 Task 12 which represents shared task on multilingual offensive language. We participated in all the provided languages for all subtasks except sub-task-A for the English language. Two main approaches have been developed the first is performed to tackle both languages Arabic and English, a weighted ensemble consists of Bi-GRU and CNN followed by Gaussian noise and global pooling layer multiplied by weights to improve the overall performance. The second is performed for other languages, a transfer learning from BERT beside the recurrent neural networks such as Bi-LSTM and Bi-GRU followed by a global average pooling layer. Word embedding and contextual embedding have been used as features, moreover, data augmentation has been used only for the Arabic language.