 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Commonsense Validation and Reasoning with Large Language Models: An Evaluation on SemEval-2020 Task 4 Dataset
Feb 19, 2025
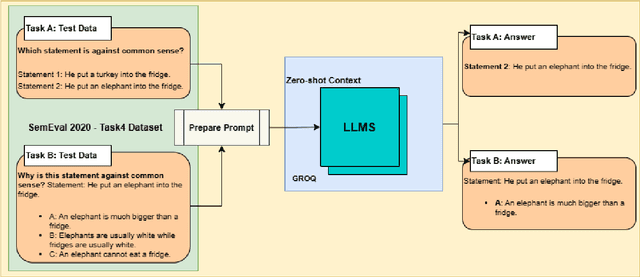
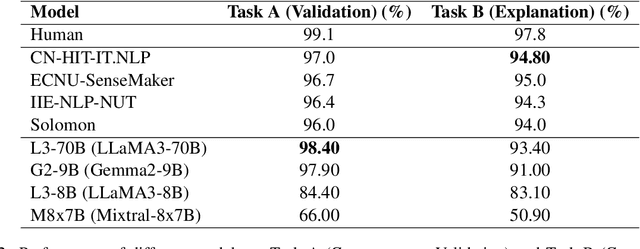

This study evaluates the performance of Large Language Models (LLMs) on SemEval-2020 Task 4 dataset, focusing on commonsense validation and explanation. Our methodology involves evaluating multiple LLMs, including LLaMA3-70B, Gemma2-9B, and Mixtral-8x7B, using zero-shot prompting techniques. The models are tested on two tasks: Task A (Commonsense Validation), where models determine whether a statement aligns with commonsense knowledge, and Task B (Commonsense Explanation), where models identify the reasoning behind implausible statements. Performance is assessed based on accuracy, and results are compared to fine-tuned transformer-based models. The results indicate that larger models outperform previous models and perform closely to human evaluation for Task A, with LLaMA3-70B achieving the highest accuracy of 98.40% in Task A whereas, lagging behind previous models with 93.40% in Task B. However, while models effectively identify implausible statements, they face challenges in selecting the most relevant explanation, highlighting limitations in causal and inferential reasoning.