 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing the Thinking Budget is Not All You Need
Dec 22, 2025Recently, a new wave of thinking-capable Large Language Models has emerged, demonstrating exceptional capabilities across a wide range of reasoning benchmarks. Early studies have begun to explore how the amount of compute in terms of the length of the reasoning process, the so-called thinking budget, impacts model performance. In this work, we propose a systematic investigation of the thinking budget as a key parameter, examining its interaction with various configurations such as self-consistency, reflection, and others. Our goal is to provide an informative, balanced comparison framework that considers both performance outcomes and computational cost. Among our findings, we discovered that simply increasing the thinking budget is not the most effective use of compute. More accurate responses can instead be achieved through alternative configurations, such as self-consistency and self-reflection.
Leveraging BERT Language Model for Arabic Long Document Classification
May 04, 2023Given the number of Arabic speakers worldwide and the notably large amount of content in the web today in some fields such as law, medicine, or even news, documents of considerable length are produced regularly. Classifying those documents using traditional learning models is often impractical since extended length of the documents increases computational requirements to an unsustainable level. Thus, it is necessary to customize these models specifically for long textual documents. In this paper we propose two simple but effective models to classify long length Arabic documents. We also fine-tune two different models-namely, Longformer and RoBERT, for the same task and compare their results to our models. Both of our models outperform the Longformer and RoBERT in this task over two different datasets.
AraLegal-BERT: A pretrained language model for Arabic Legal text
Oct 15, 2022



The effectiveness of the BERT model on multiple linguistic tasks has been well documented. On the other hand, its potentials for narrow and specific domains such as Legal, have not been fully explored. In this paper, we examine how BERT can be used in the Arabic legal domain and try customizing this language model for several downstream tasks using several different domain-relevant training and testing datasets to train BERT from scratch. We introduce the AraLegal-BERT, a bidirectional encoder Transformer-based model that have been thoroughly tested and carefully optimized with the goal to amplify the impact of NLP-driven solution concerning jurisprudence, legal documents, and legal practice. We fine-tuned AraLegal-BERT and evaluated it against three BERT variations for Arabic language in three natural languages understanding (NLU) tasks. The results show that the base version of AraLegal-BERT achieve better accuracy than the general and original BERT over the Legal text.
Healthcare Knowledge Graph Construction: State-of-the-art, open issues, and opportunities
Jul 08, 2022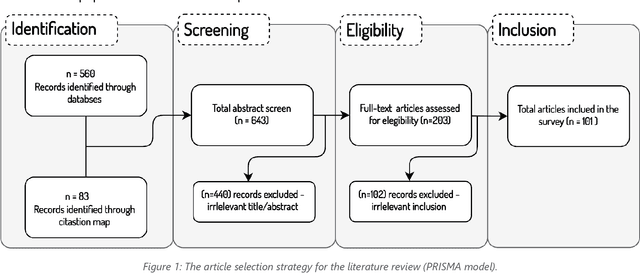
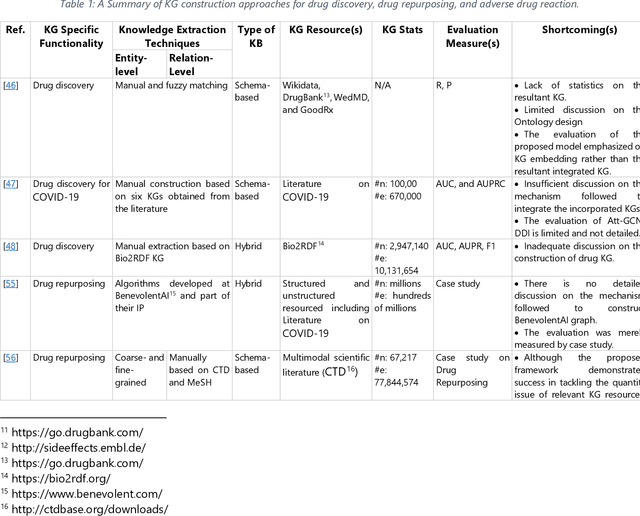
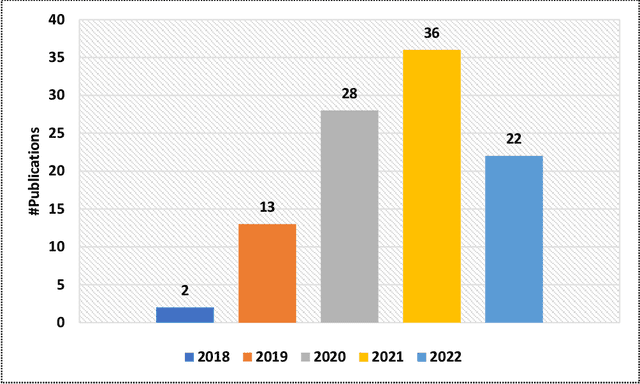
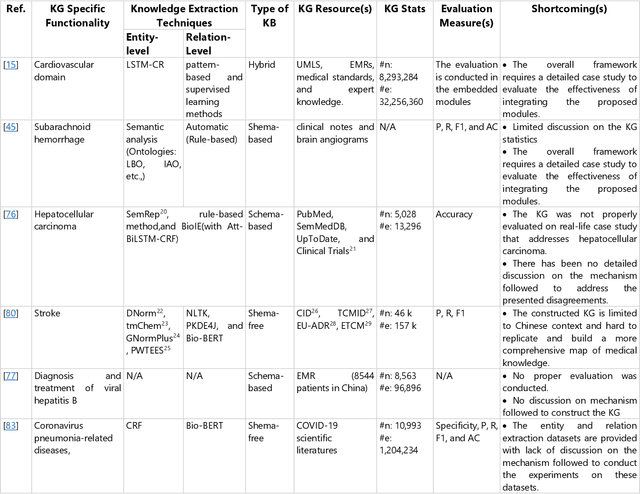
The incorporation of data analytics in the healthcare industry has made significant progress, driven by the demand for efficient and effective big data analytics solutions. Knowledge graphs (KGs) have proven utility in this arena and are rooted in a number of healthcare applications to furnish better data representation and knowledge inference. However, in conjunction with a lack of a representative KG construction taxonomy, several existing approaches in this designated domain are inadequate and inferior. This paper is the first to provide a comprehensive taxonomy and a bird's eye view of healthcare KG construction. Additionally, a thorough examination of the current state-of-the-art techniques drawn from academic works relevant to various healthcare contexts is carried out. These techniques are critically evaluated in terms of methods used for knowledge extraction, types of the knowledge base and sources, and the incorporated evaluation protocols. Finally, several research findings and existing issues in the literature are reported and discussed, opening horizons for future research in this vibrant area.